
A Smarter Claude Model Burns More Tokens, Not Fewer!
...and how to fix it using Karpathy's context engineering principles.

A smarter Claude model burns more tokens, not fewer!
The above line sounds counterintuitive, but MCPMark V2 benchmarks confirmed this across 21 backend tasks.
And it’s not a minor 3-5% difference.
But 54% higher token usage.
The reason has nothing to do with the model itself.
Instead, it has to do with what the agent needs to know before it can start building.
When you’re building a full-stack app, CC must understand the entire backend, like:
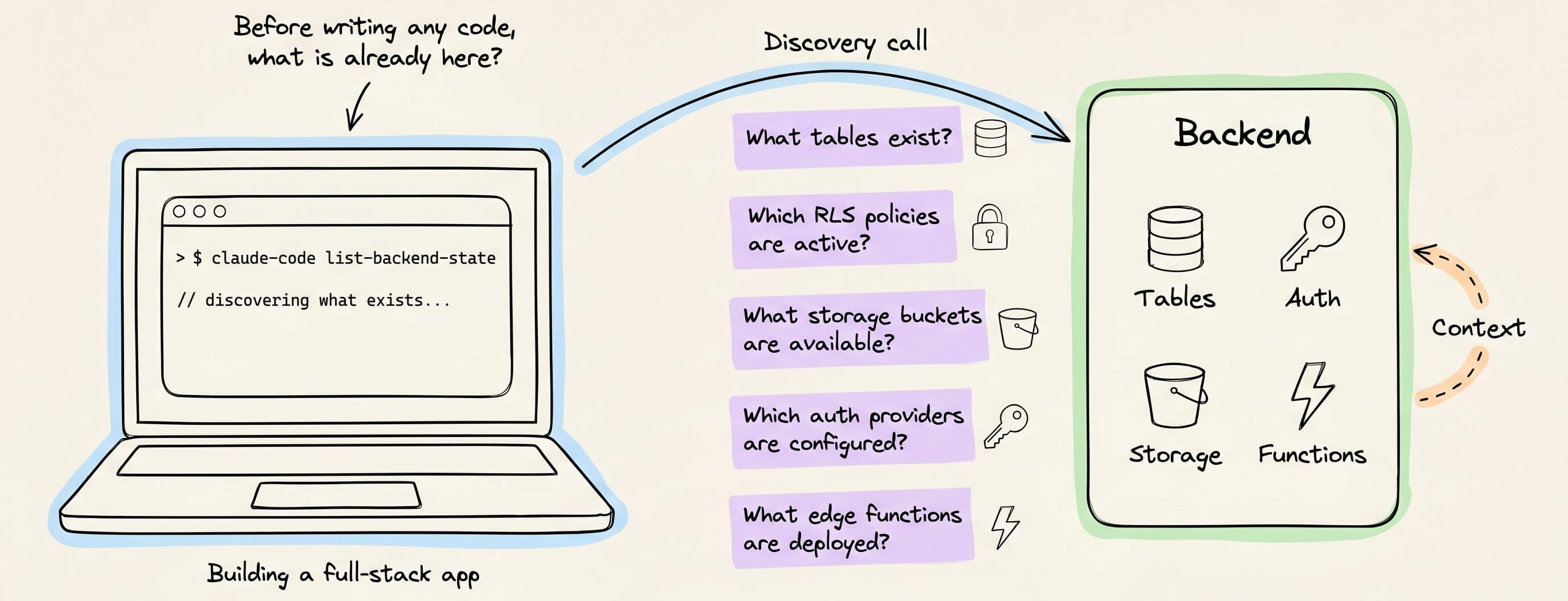
what tables already exist
what RLS policies are active
what storage buckets are available
which auth providers are configured
and what edge functions are deployed
Most backends don’t hand over this info cleanly.
For instance, with Supabase, asking for OAuth setup via MCP returns the entire auth docs, including sections on email/password, magic links, phone auth, SAML, and SSO.
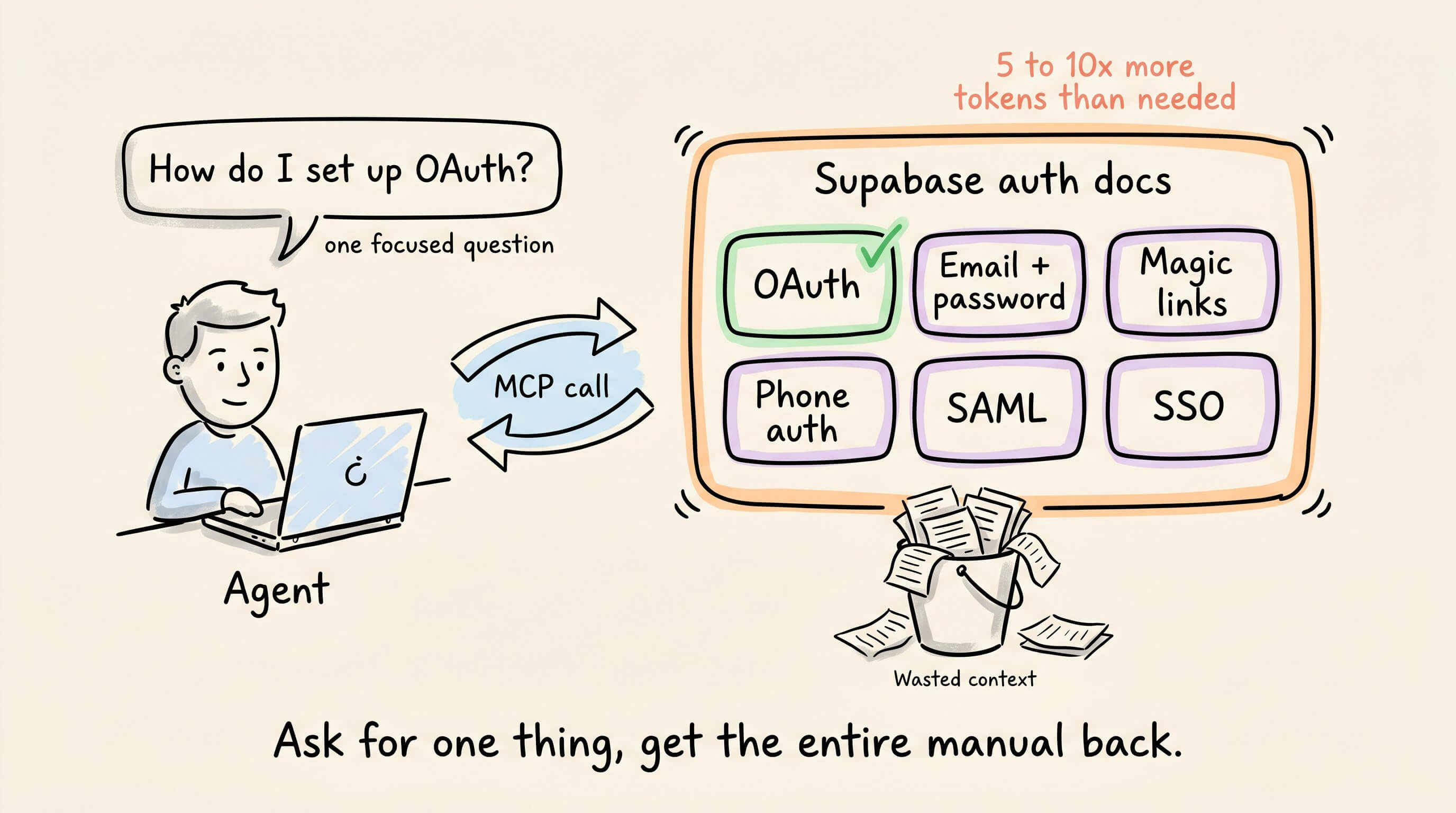
That’s 5-10x more tokens than the agent actually needed. And this happens on every MCP call across every domain.
The agent then discovers the state through separate calls to list_tables, execute_sql, and list_extensions, each returning a partial view.
Some info, like which auth providers are configured, isn’t queryable through MCP at all.
And when something breaks, Supabase returns the same error code whether the rejection came from the platform layer or from the function code.
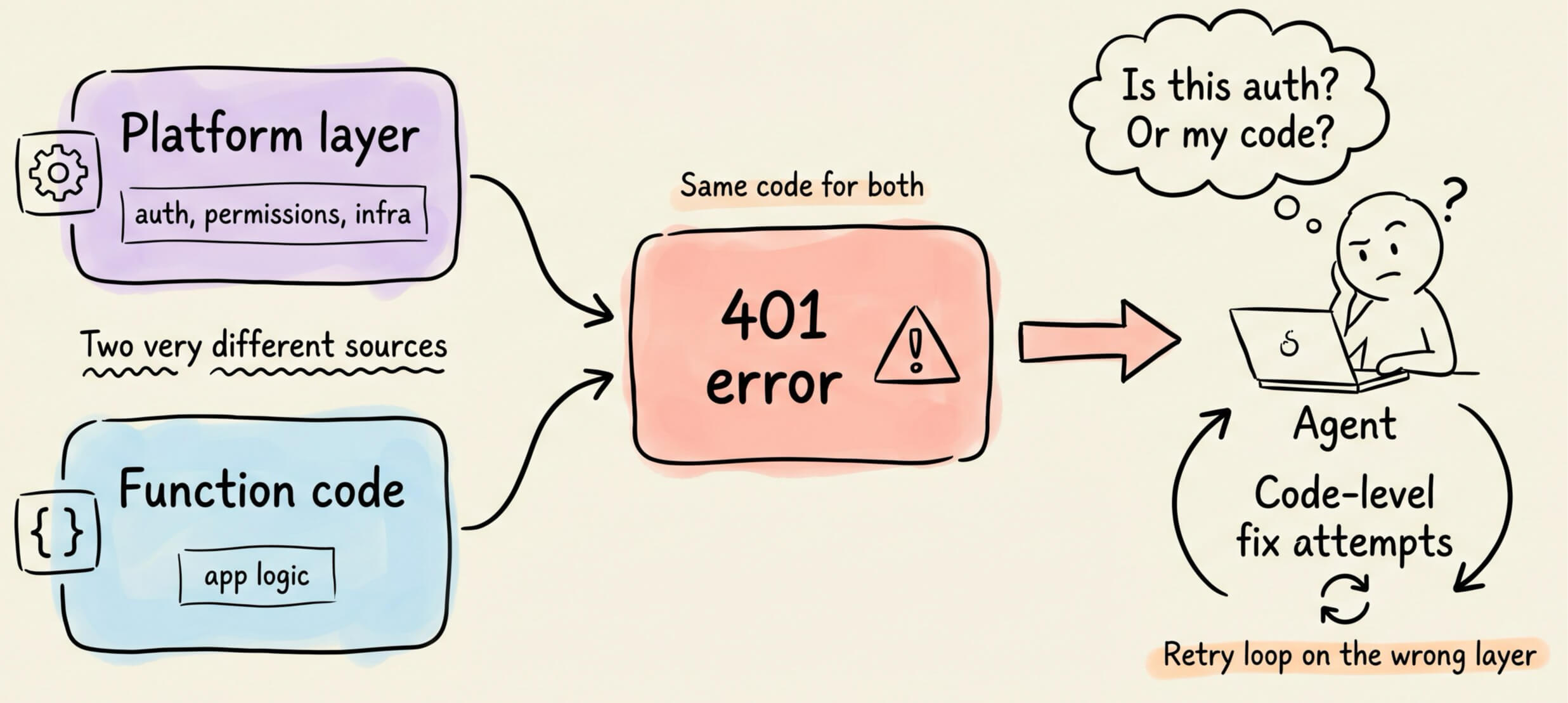
The agent has no way to infer accurately, so it cycles through code-level fixes for a problem that might not be in the code at all.
A better model does not have a magical way to skip these gaps.
In fact, it tries even harder to fill them, which means more discovery queries, more reasoning, and more retries. That’s why the token cost went up with a better Claude model.
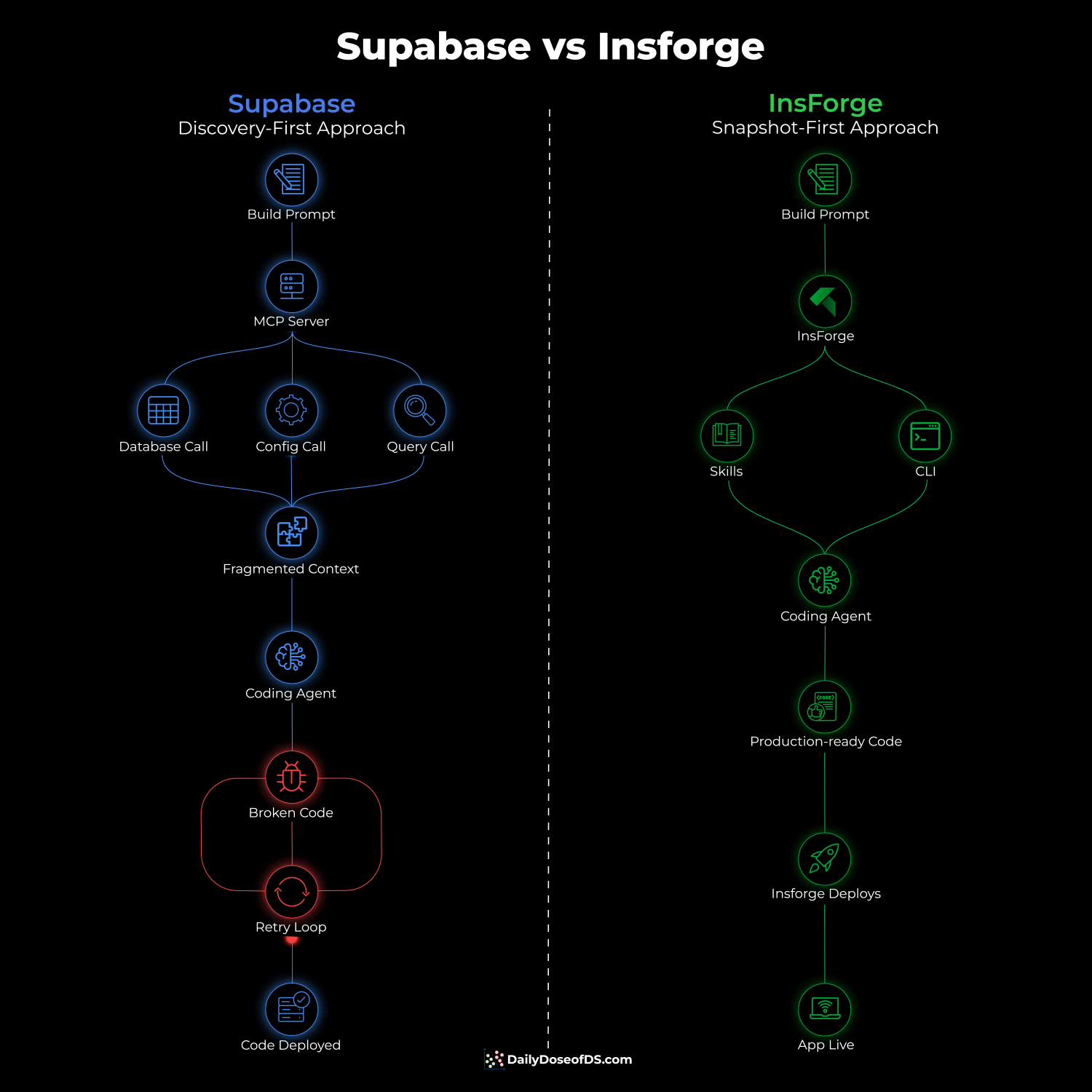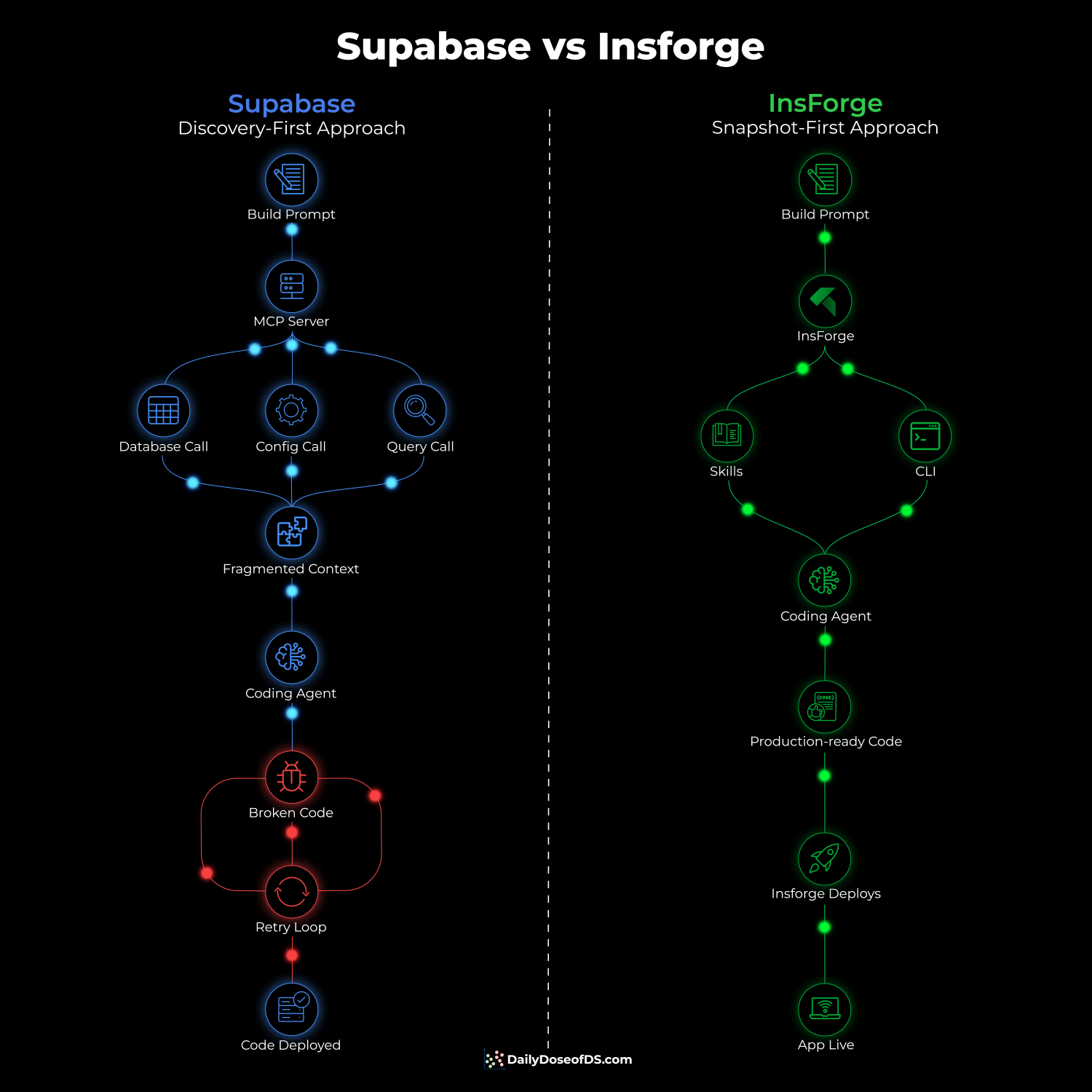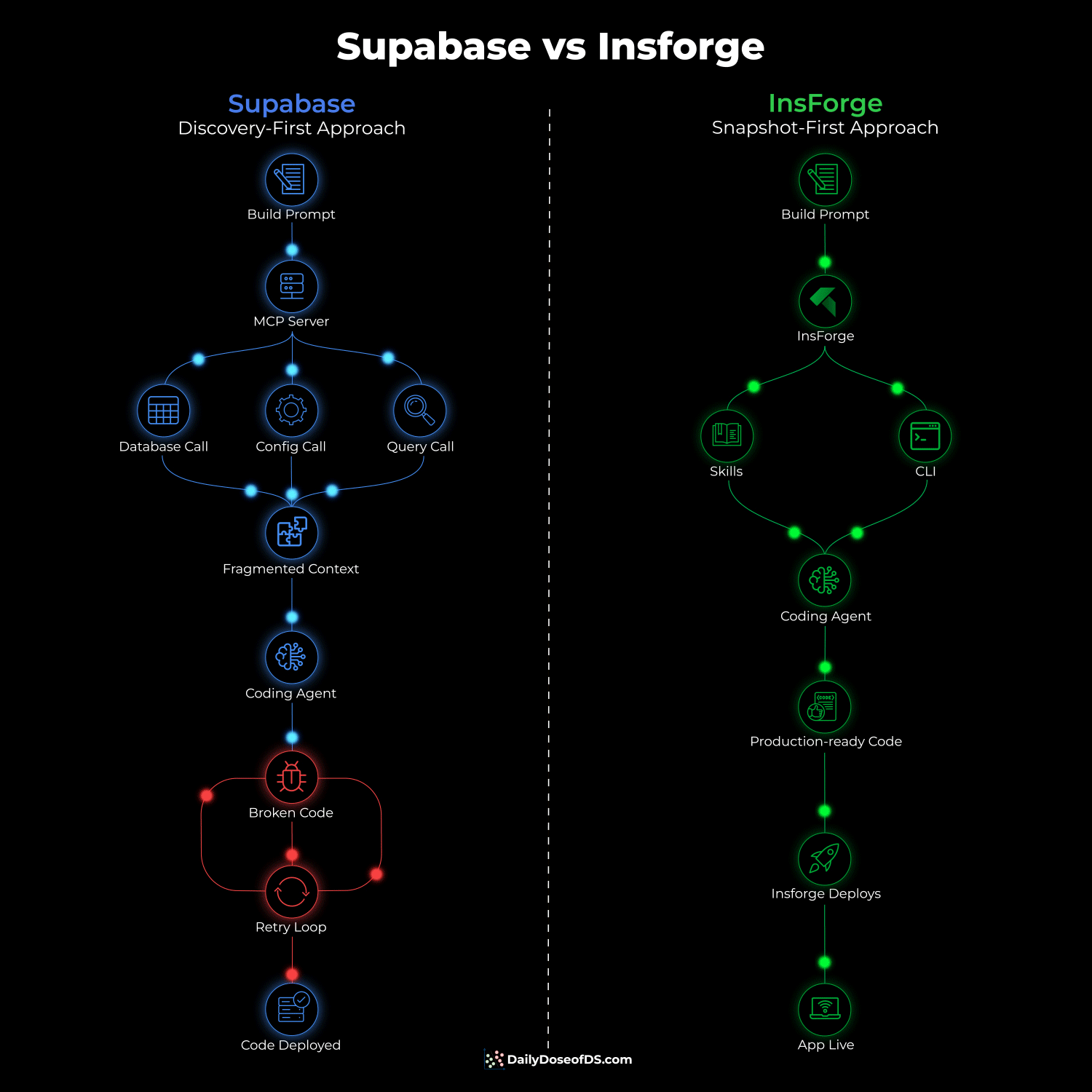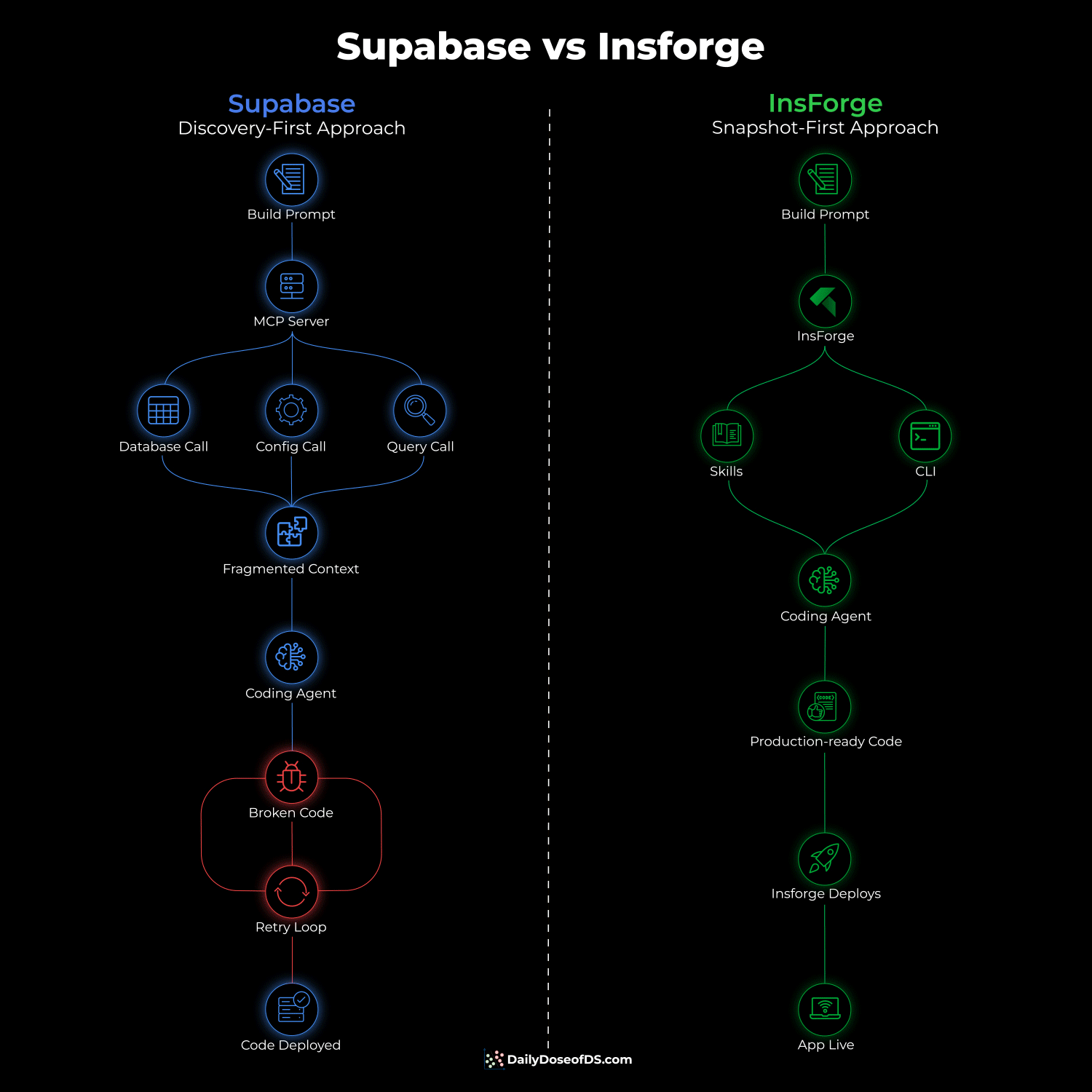
A smarter approach is actually implemented in InsForge, an open-source backend (self-hostable via Docker) that offers the same primitives as Supabase but structures everything around the assumption that an agent is operating the backend, not a human on a dashboard.
Before writing any code, a single CLI call returns the full backend topology in ~500 tokens.
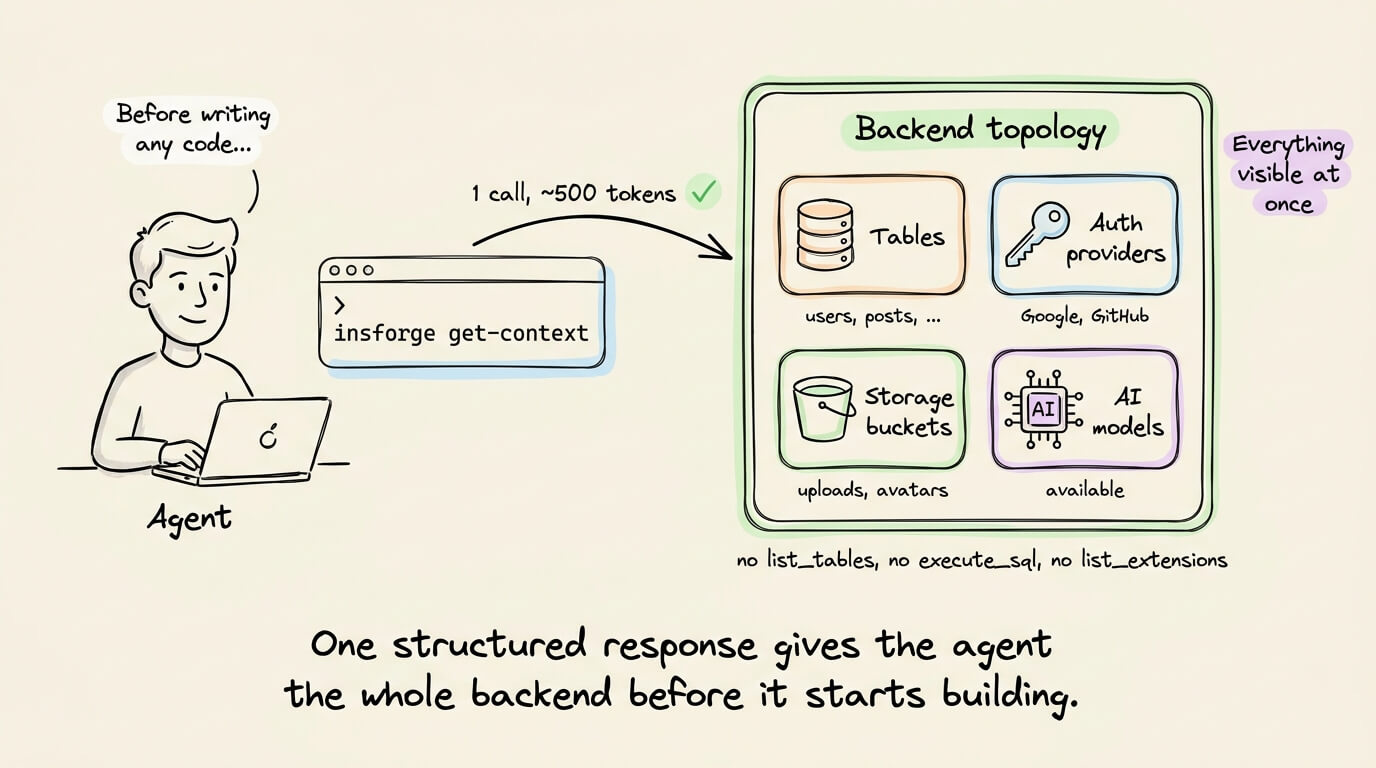
The agent sees every table, auth provider, storage bucket, and available AI models in one structured response.
Instead of one broad skill like Supabase that triggers on everything, it has four narrowly scoped skills.
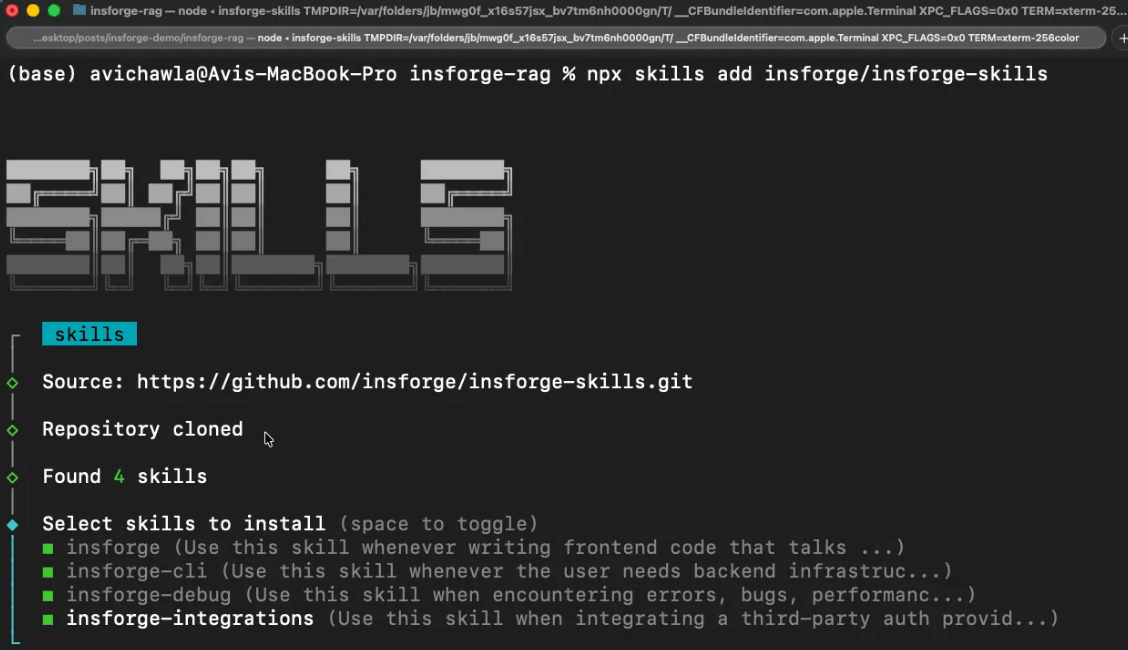
Creating tables only activates the CLI skill.
Debug skill only activates when code breaks.
Building frontend only activates the SDK skill.
Wiring third-party auth only activates the integrations skill.
This keeps the agent’s cognitive load lean since it only loads what matches the current task.
The CLI returns structured JSON with semantic exit codes on every operation, so the agent always knows whether something succeeded or failed and why. There are no ambiguous 401s that may indicate three different things.
We tested both backends on the same full-stack RAG app and recorded the full sessions.
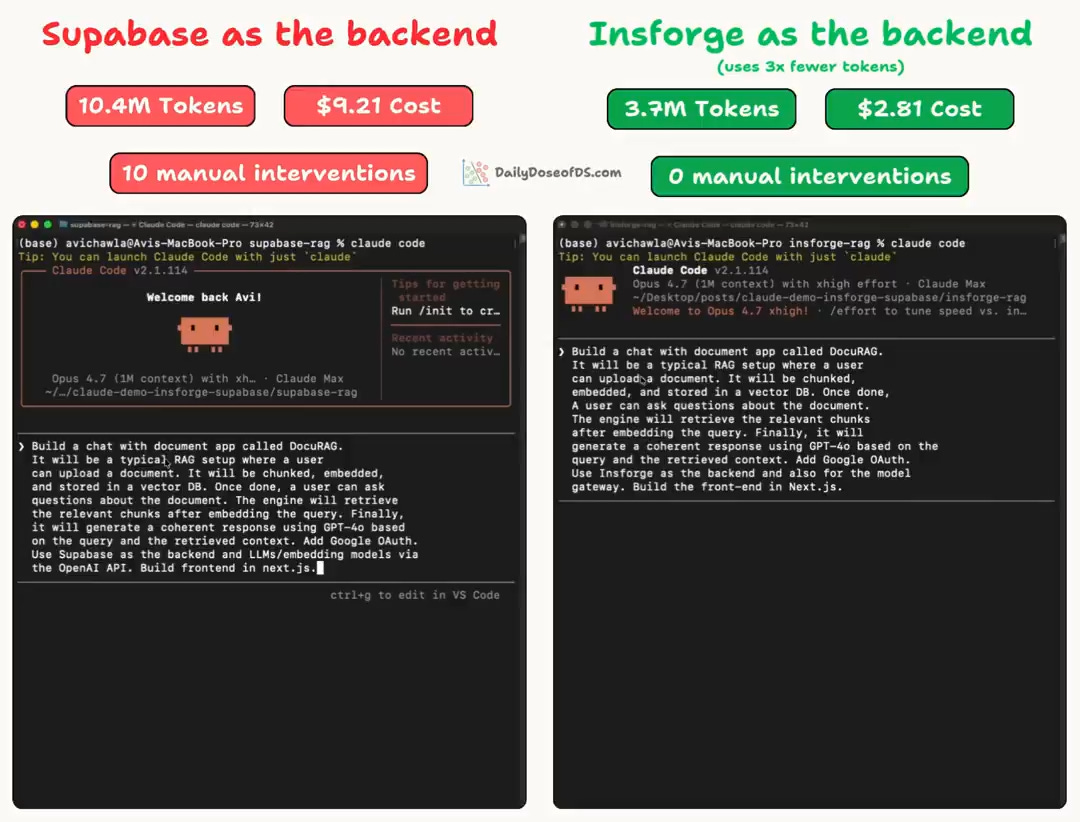
Supabase:
consumed 10.4M tokens
needed 10 manual interventions
InsForge:
consumed 3.7M tokens
completed the entire build without any errors
This isn’t a Supabase-specific problem. Most backends were designed for humans who can see dashboards and interpret raw errors.
When an agent operates the backend instead, every missing piece of context needs a discovery call, and every ambiguous error enters a retry loop.
Fixing this requires giving agents structured backend context before they start writing code.
InsForge is an open-source implementation of exactly this, and you can self-host it via Docker.
GitHub repo (9k+ stars): https://github.com/InsForge/InsForge
(don’t forget to star it ⭐ )
Checkpoint any method automatically using CrewAI
Long-running agent flows fail mid-run, and in most frameworks, that means restarting from zero and burning the tokens again.
CrewAI just shipped checkpointing in v1.14. Every flow method becomes a recovery point, written automatically when an event you specify fires (e.g., method_execution_finished).
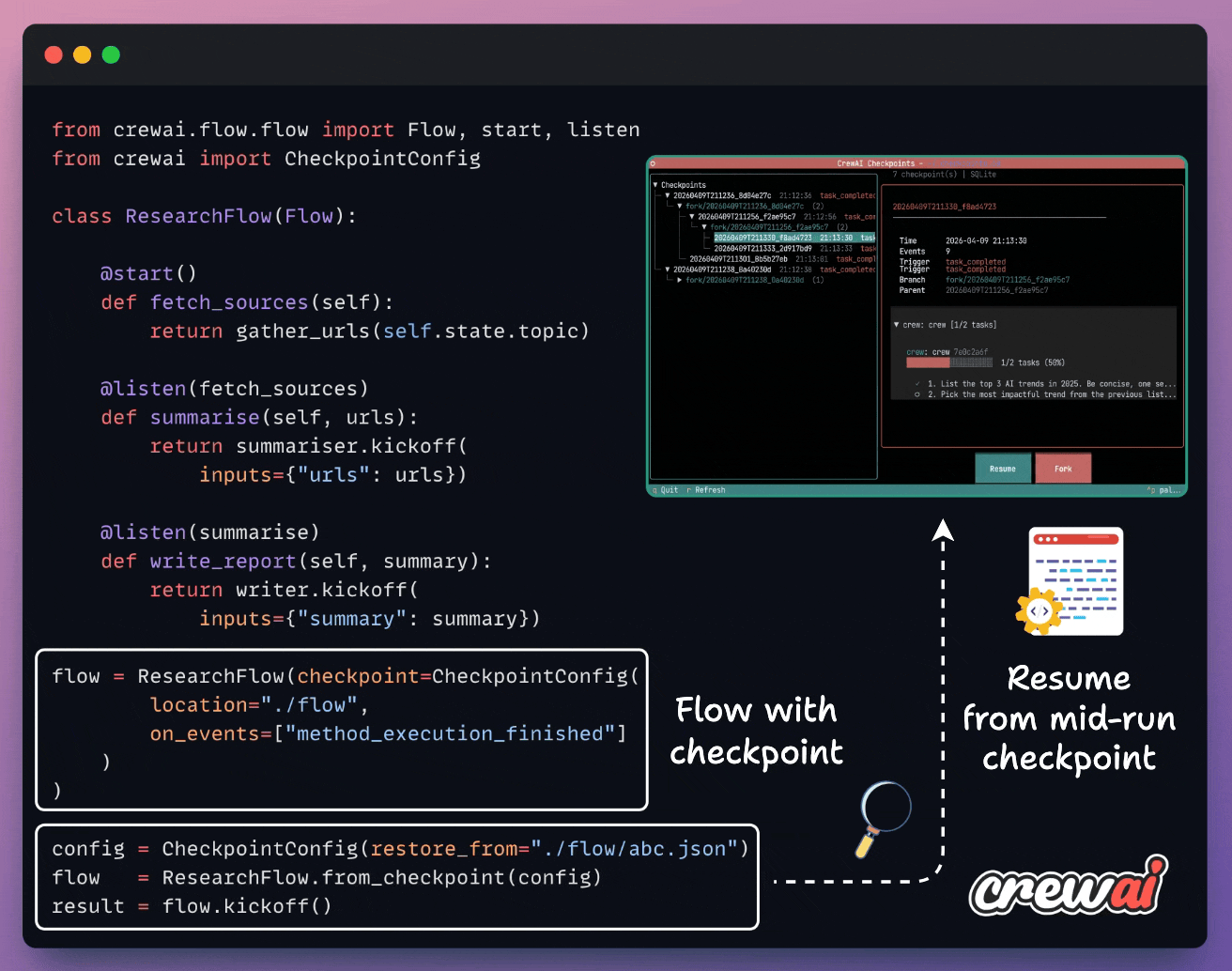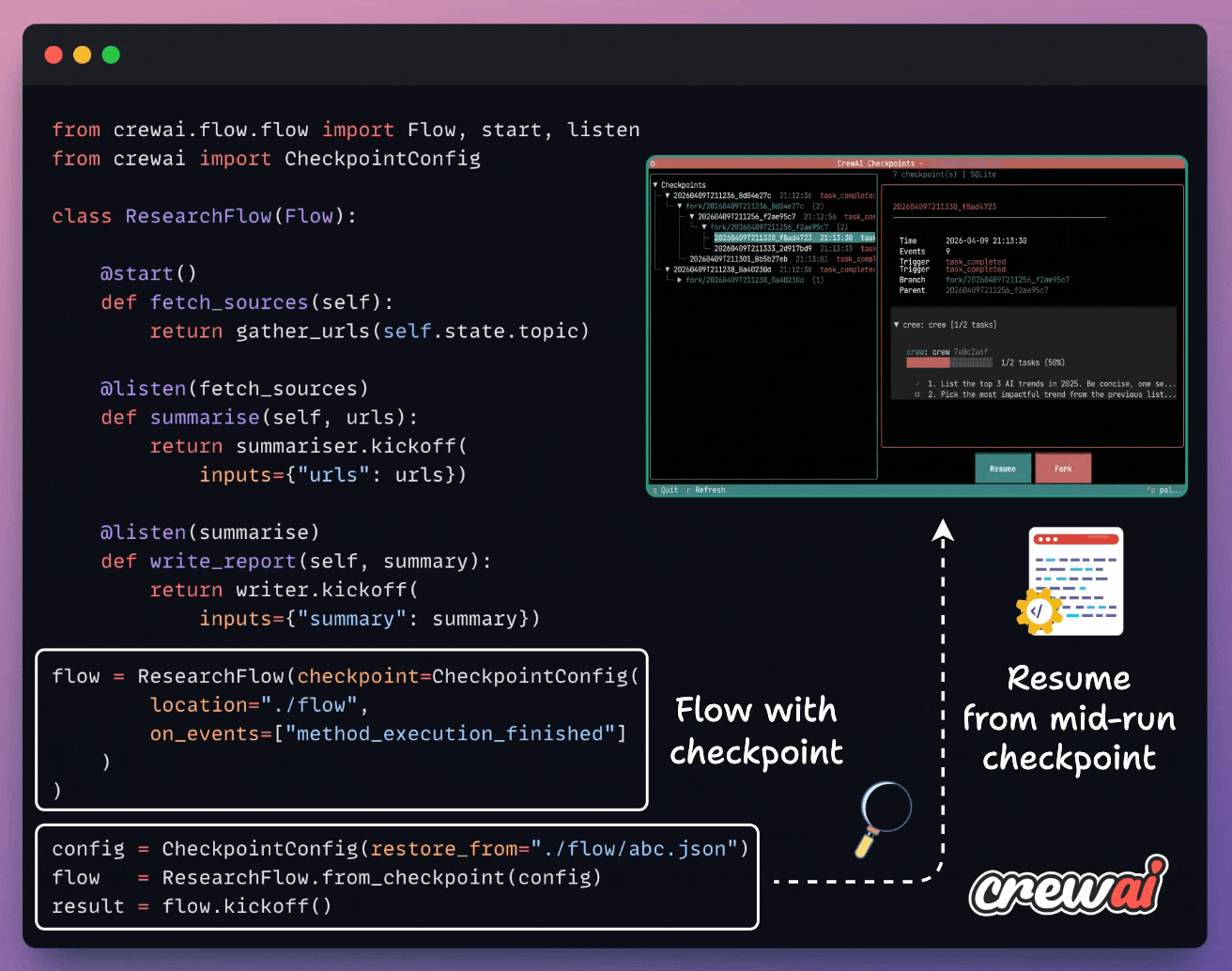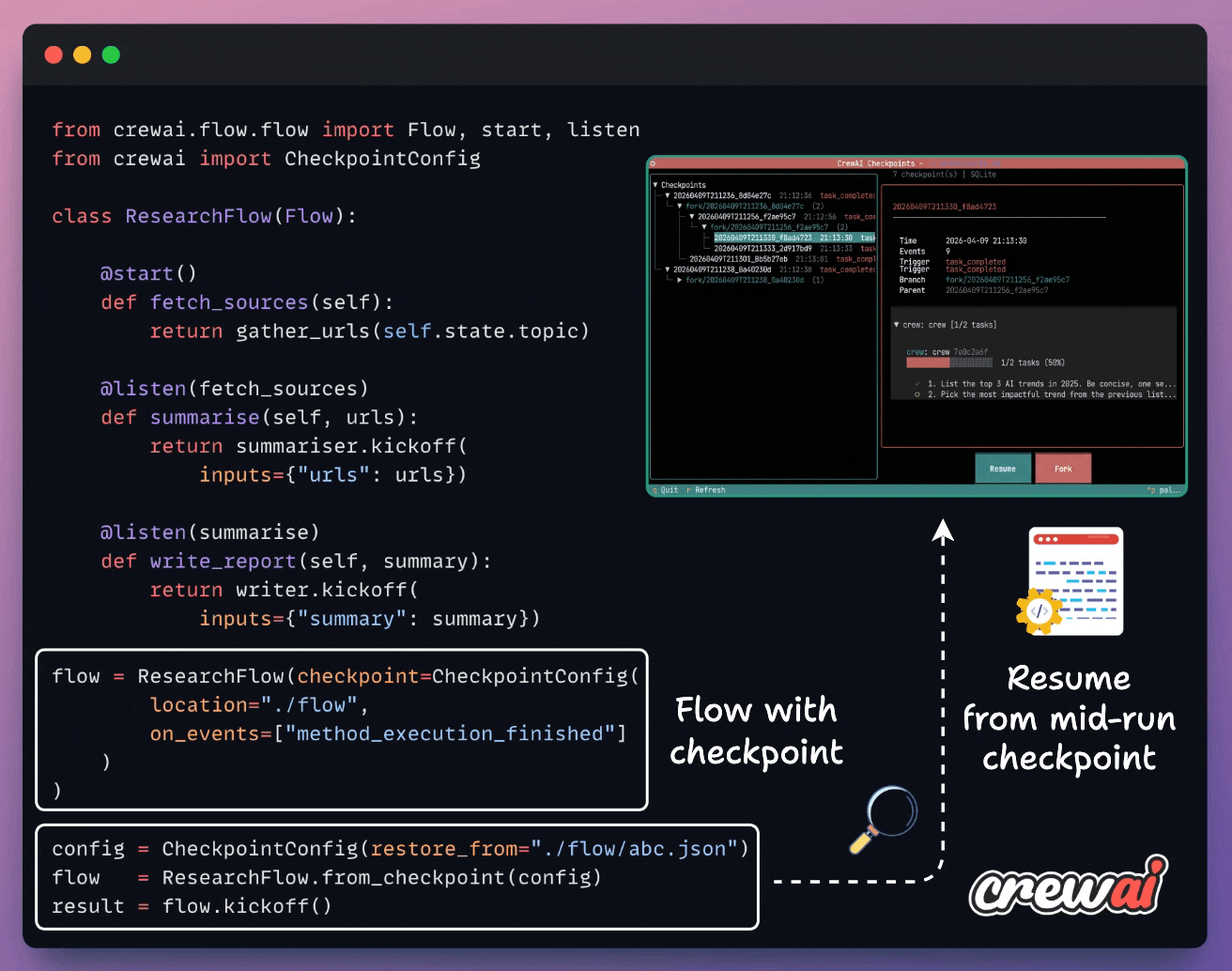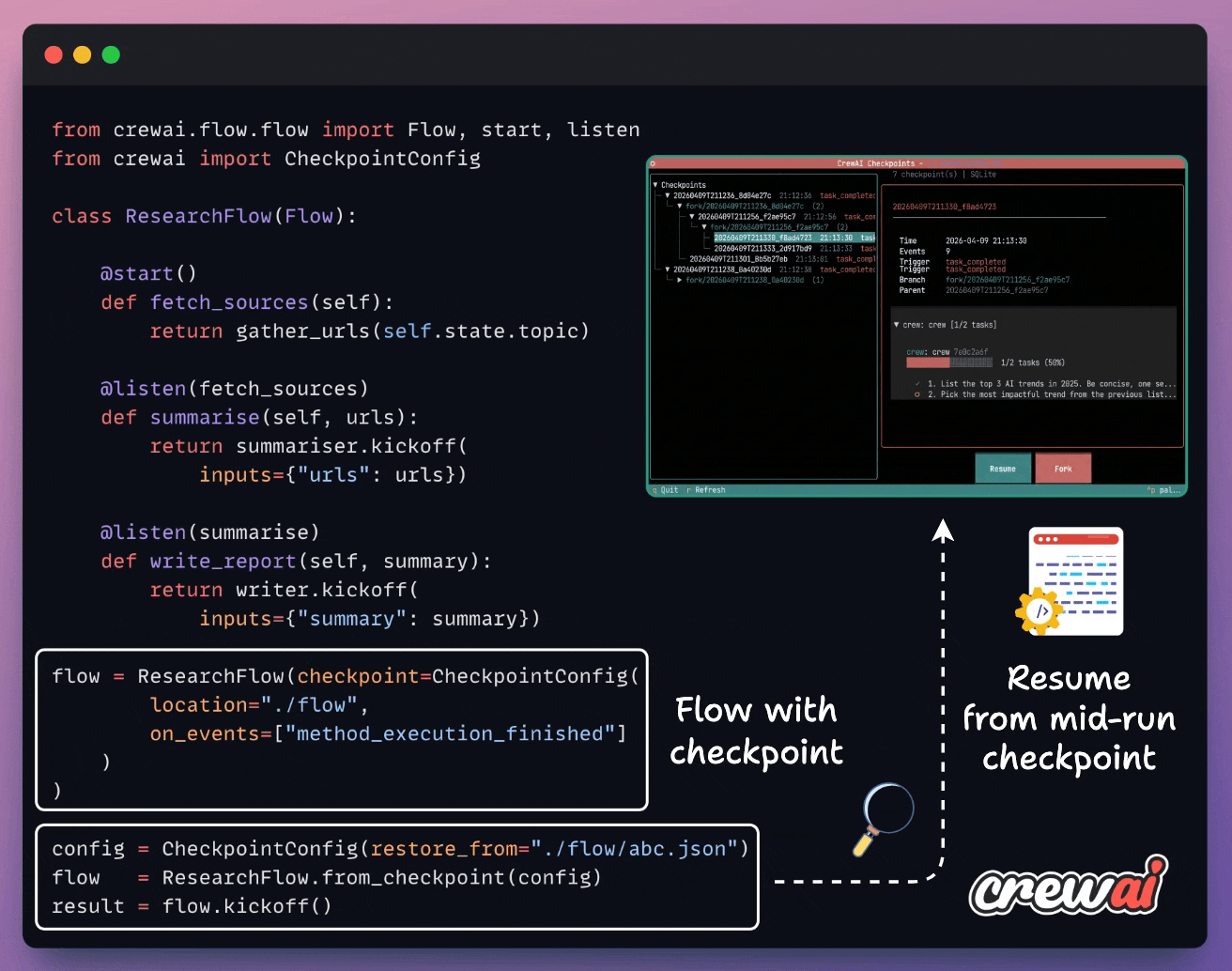
You can resume in one line and fork from any saved state into a new branch with full lineage tracking. An async TUI lets you browse checkpoints, inspect events, and resume or fork from the UI.
The pipelines become resumable, inspectable, and branchable processes, with zero extra infra.
You can find the CrewAI repo here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.