
A Subtle Trick to Optimize Neural Network Training
A technique I accidentally discovered.

I don’t think I have ever been excited about implementing (writing code) a neural network — defining its layers, writing the forward pass, etc.
In fact, this is quite a monotonous task for most machine learning engineers.
For me, the real challenge and fun lies in squeezing every bit of the GPU memory through optimization.

Today, I want to share something I accidentally discovered a couple of years ago while optimizing the training procedure.
What I am about to share will sound quite obvious when you learn about it, but still, I feel many people don’t realize how subtle it is.
Let’s begin!
Note: While writing this newsletter, I attempted to replicate the exact procedure I used back then to show you some visuals. However, I was unable to do so due to the deprecation of a couple of features in PyTorch. Nonetheless, I vividly remember everything, so I will replace them with self-created visuals instead.
What was I doing?
I was working on an image classification task—consider MNIST for simplicity.
Normalizing the pixel values is a common technique to stabilize model training.
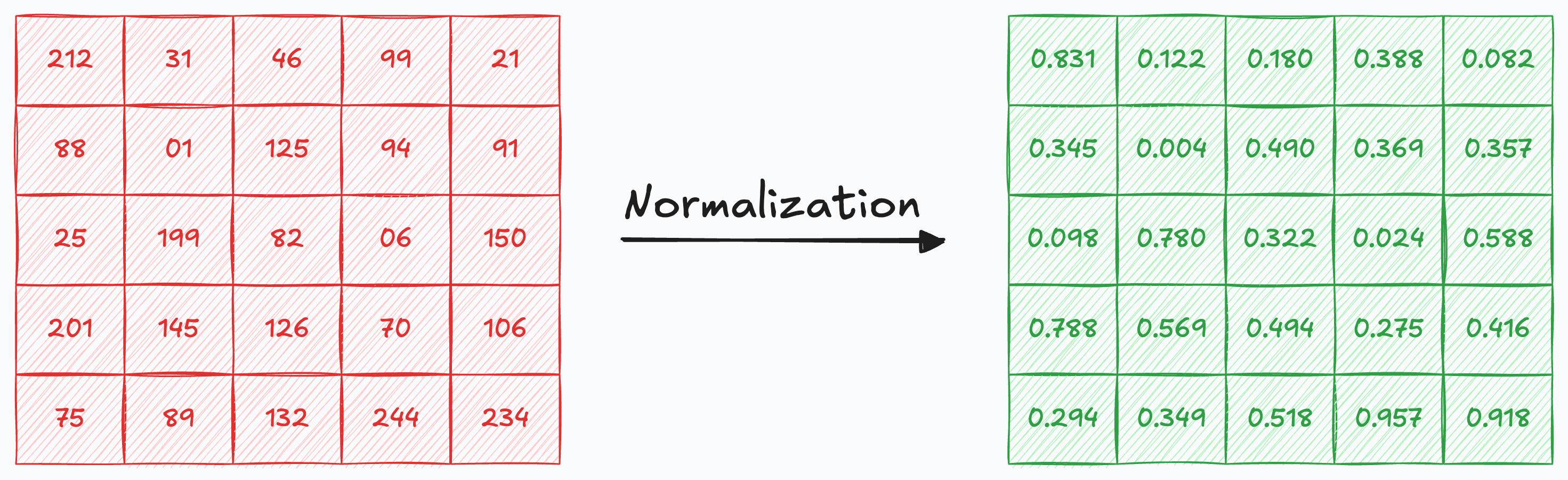
So here’s what my code looked like:
First, I loaded the dataset, transformed it, defined the model, etc.

Next, I had the regular training loop where I transferred the data to GPU before the training iteration, as shown below:

Here’s what the profiler looked like:

Most of the time/resources were allocated to the kernel (the actual training code).
However, a significant amount of time was dedicated to data transfer from CPU to GPU (
Memcpyindicates that).
At first look, it appears that we can’t do much to optimize this since it’s the data, right? We have to transfer it anyway, and there isn’t any workaround to optimize it.

But here’s the trick.
Recall that the original dataset was composed of pixel values, which are 8-bit integers, and we normalized them to 32-bit floats:

Next, we transferred these 32-bit floating point tensors to the GPU, which meant normalizing the data led to more data being transferred.
That is when I had my Aha moment!
I realized that moving the normalization step after the data transfer will solve this since we shall be transferring 8-bit integers instead of 32-bit floats:

As a result, I noticed a significant drop in the Memcpy step, which makes total intuitive sense.

I had trained several models before that, but it never occurred to me that there could be such a subtle way to optimize model training.
Of course, this technique doesn’t apply to all neural network use cases, like NLP, where we inherently deal with 32-bit float embeddings.
However, whenever I have identified any possibility to use this trick, I have experienced noticeable gains from it.
Isn’t that a neat trick?
If you want to get into more detail about the internal of GPU programming, how threads work, what model.cuda() does under the hood, etc., we covered it in this detailed guide here: Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming.
We covered the end-to-end details of CUDA and did a hands-on demo on CUDA programming by implementing parallelized implementations of various operations we typically perform in deep learning.
Quantization is another topic you will love reading about, and it is a must-know skill for ML engineers to reduce model footprint and inference time: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
👉 Over to you: What are some lesser-known ways of optimizing model training that you are aware of?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 87,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
No doubt that contents are of high quality. But more than content I like look and feel of fonts you use and simple but effective info graphics. If you don't mind can you please tell which tool you use for info graphics.