
A Unique Perspective on What Hidden Layers and Activation Functions Do
Intuitive guide to handling non-linearity with neural networks.

Everyone knows the objective of an activation function in a neural network.
They let the network learn non-linear patterns.
There is nothing new here, and I am sure you are aware of that too.
However, one thing I have often realized is that most people struggle to build an intuitive understanding of what exactly a neural network consistently tries to achieve during its layer-after-layer transformations.

Today, let me provide you with a unique perspective on this, which would really help you understand the internal workings of a neural network.
I have supported this post with plenty of visuals for better understanding.
Yet, if there’s any confusion, please don’t hesitate to reach out.
Also, for simplicity, we shall consider a binary classification use case.
Let’s begin!
Background
We know that in a neural network, the data undergoes a series of transformations at each hidden layer.
More specifically, this involves the following operations at every layer:
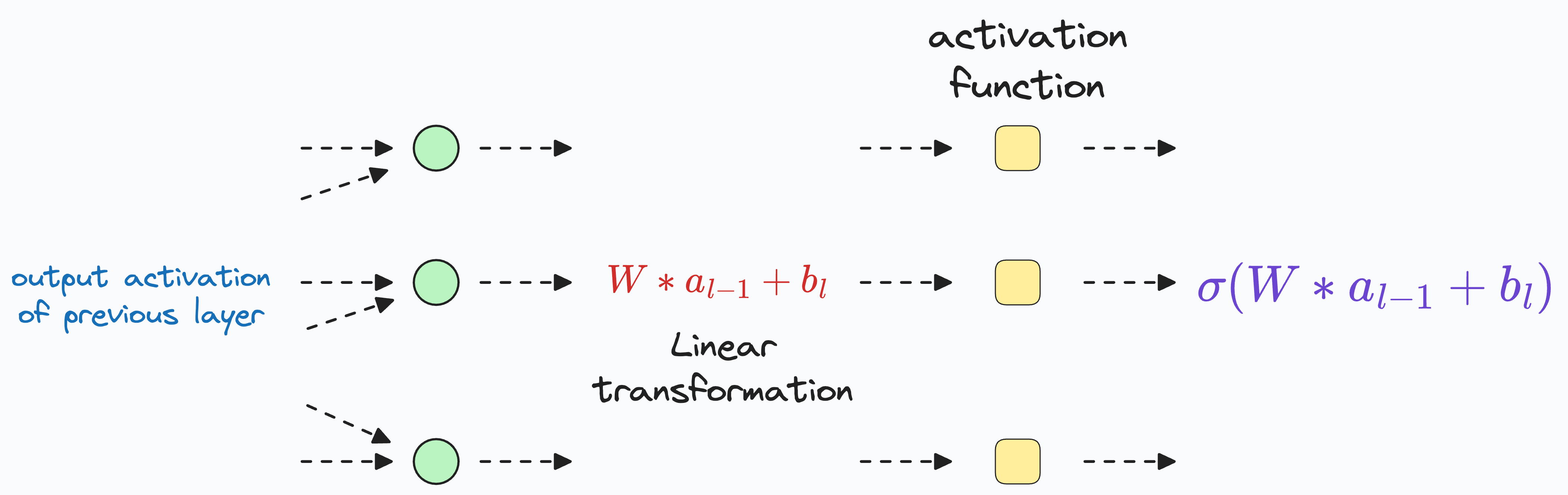
Linear transformation of the data obtained from the previous layer
…followed by a non-linearity using an activation function — ReLU, Sigmoid, Tanh, etc.
The above transformations are performed on every hidden layer of a neural network.
Now, notice something here.
Assume that we just applied the above data transformation on the very last hidden layer of the neural network.
Once we do that, the activations progress toward the output layer of the network for one final transformation, which is entirely linear.

The above transformation is entirely linear because all sources of non-linearity (activations functions) exist on or before the last hidden layer.
And during the forward pass, once the data leaves the last hidden layer, there is no further scope for non-linearity.

Thus, to make accurate predictions, the data received by the output layer from the last hidden layer MUST BE linearly separable.
To summarize….
While transforming the data through all its hidden layers and just before reaching the output layer, a neural network is constantly hustling to project the data to a space where it somehow becomes linearly separable.
If it does, the output layer becomes analogous to a logistic regression model, which can easily handle this linearly separable data.
In fact, we can also verify this experimentally.
To visualize the input transformation, we can add a dummy hidden layer with just two neurons right before the output layer and train the neural network again.
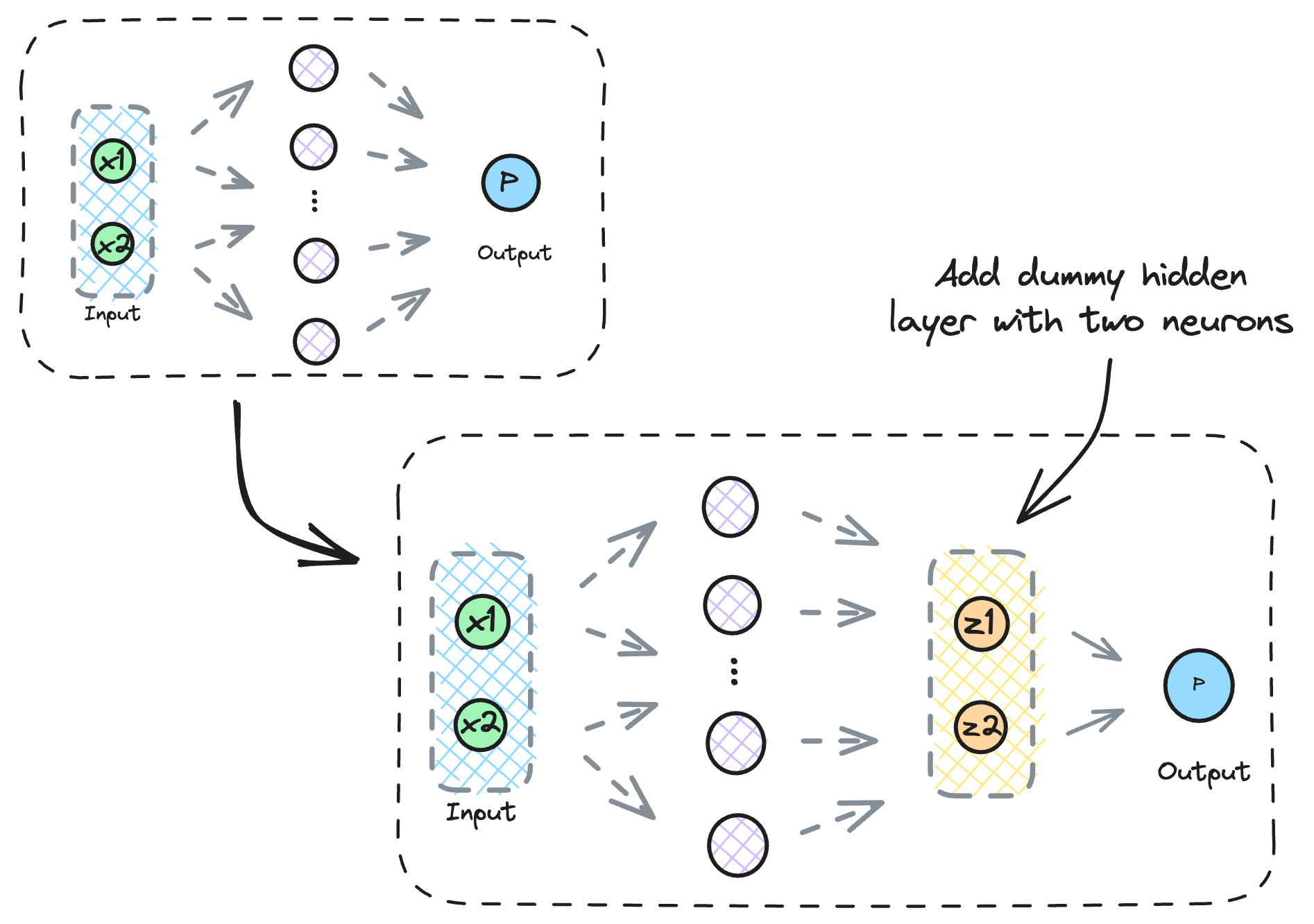
Why do we add a layer with just two neurons?
This way, we can easily visualize the transformation.
We expect that if we plot the activations of this 2D dummy hidden layer, they must be linearly separable.
The below visual precisely depicts this.

As we notice above, while the input data was linearly inseparable, the input received by the output layer is indeed linearly separable.
This transformed data can be easily handled by the output classification layer.
And this shows that all a neural network is trying to do is transform the data into a linearly separable form before reaching the output layer.
Hope that helped!
That said, KANs are another recently introduced neural network paradigm that challenges the traditional neural network design and offers an exciting new approach to design and train them.

We understood and implemented them from scratch here: Implementing KANs From Scratch Using PyTorch.
👉 Over to you: While this discussion was for binary classification, can you tell what a neural network would do for regression?
1 Referral: Unlock 450+ practice questions on NumPy, Pandas, and SQL.
2 Referrals: Get access to advanced Python OOP deep dive.
3 Referrals: Get access to the PySpark deep dive for big-data mastery.
Get your unique referral link:
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 79,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.