
A Visual Guide To Sampling Techniques in Machine Learning
Never overlook your sampling technique.


When you are dealing with large amounts of data, it is often preferred to draw a relatively smaller sample and train a model. But any mistakes can adversely affect the accuracy of your model.
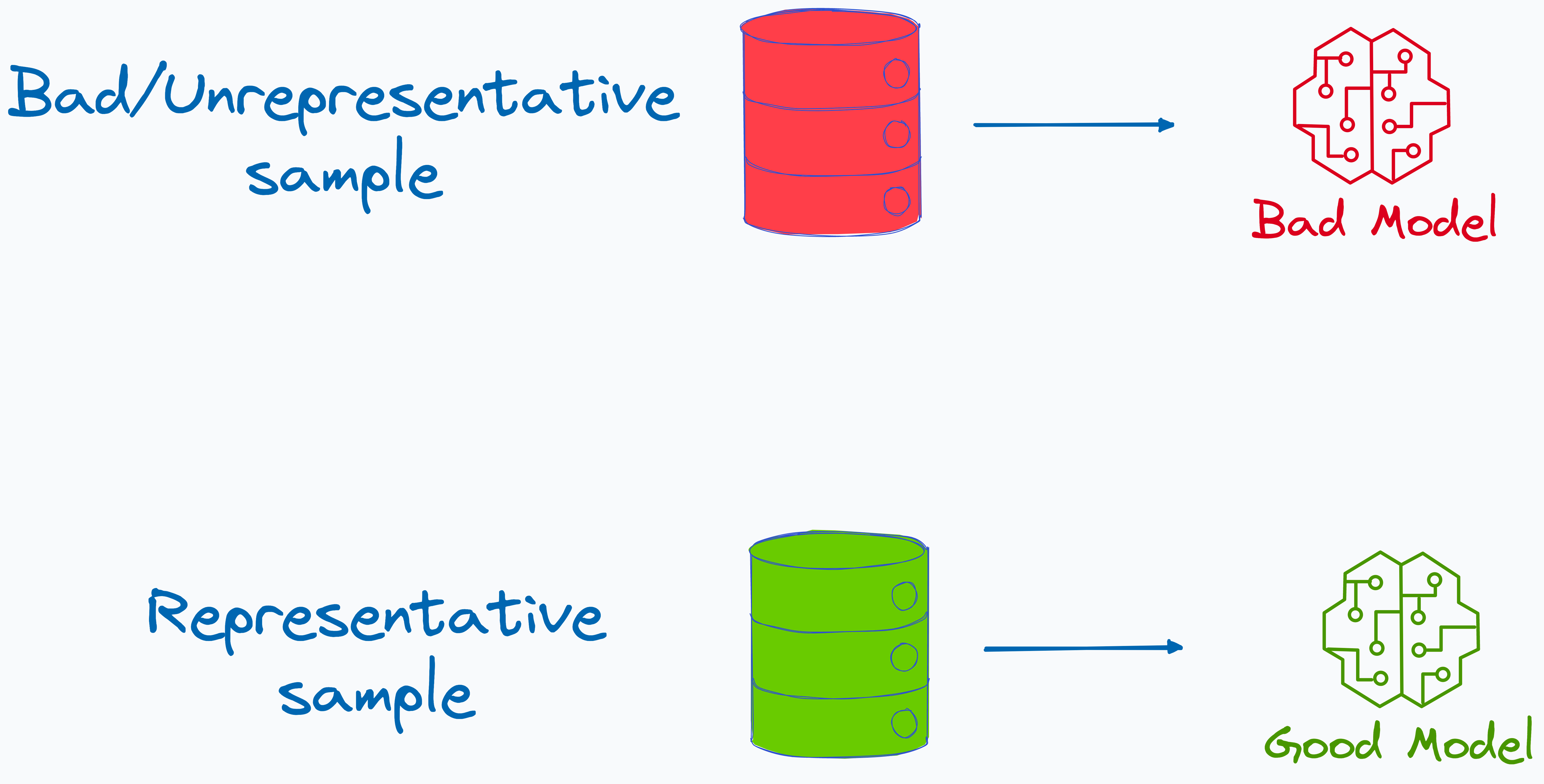
This makes sampling a critical aspect of training ML models.
Here are a few popularly used techniques that one should know about:
🔹 Simple random sampling: Every data point has an equal probability of being selected in the sample.

🔹 Cluster sampling (single-stage): Divide the data into clusters and select a few entire clusters.

🔹 Cluster sampling (two-stage): Divide the data into clusters, select a few clusters, and choose points from them randomly.

🔹 Stratified sampling: Divide the data points into homogenous groups (based on age, gender, etc.), and select points randomly.

What are some other sampling techniques that you commonly resort to?
👉 Read what others are saying about this post on LinkedIn.
👉 If you love reading this newsletter, feel free to share it with friends!
Hey There!
I frequently notice that much less than 1% of readers like these posts. Please understand that it takes quite an effort to gather insights and summarize them with visuals in one-to-two-minute daily reads.
So I would really urge you to react. It will NEVER take more than a couple of seconds. The button is located towards the bottom of this email:

This prompts Substack to recommend it to more readers and also largely increases the discoverability of the newsletter on this platform.
Thanks for understanding :)
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Under which conditions would you choose one sampling method over another?
Good Post