
Accuracy Can Be Deceptive
...when improving probabilistic multiclass models.

If some technique improves the model, we can say it was effective:

But at times, you may be making good progress in improving the model, but “Accuracy” is not reflecting that (yet).
I have seen this when building probabilistic multiclass-classification models.
Let's understand!
On a side note, in addition to the discussion below, we covered:
Pitfall of Accuracy
In probabilistic multiclass classification models, Accuracy is determined using the highest probability output label:
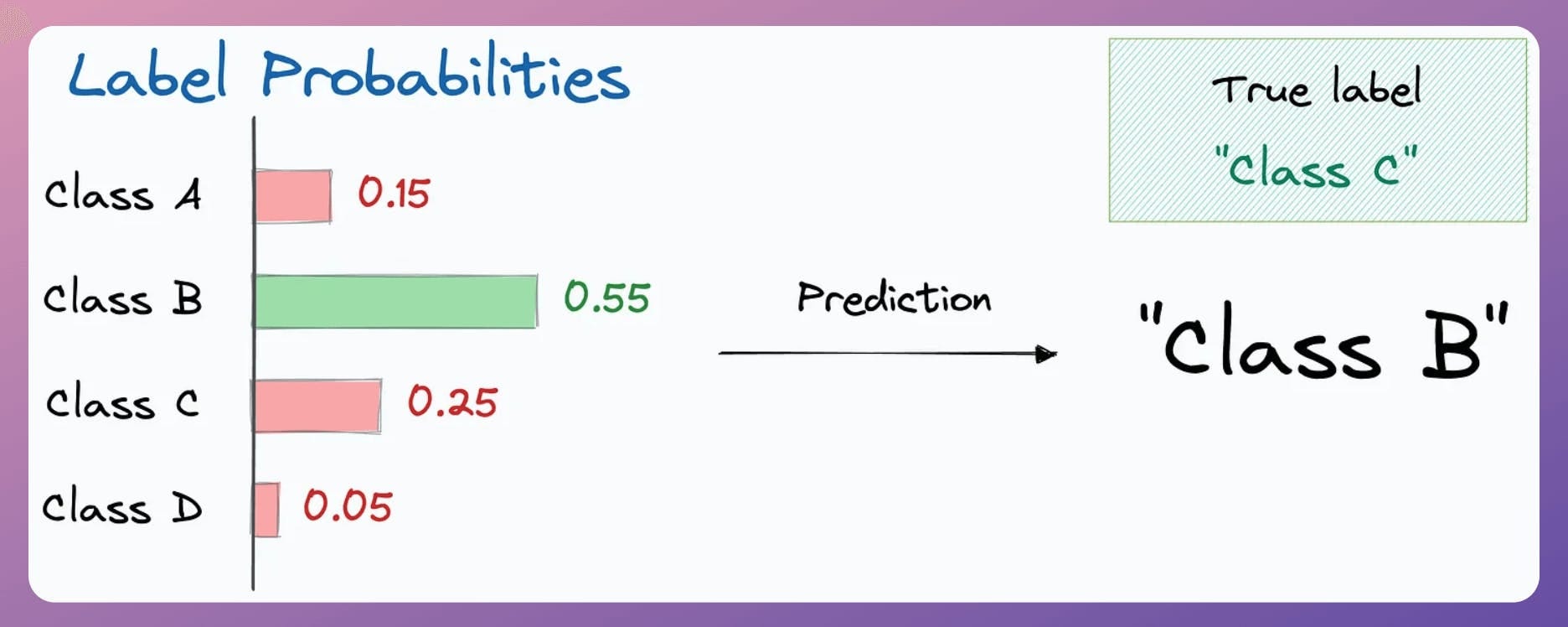
Now imagine this:
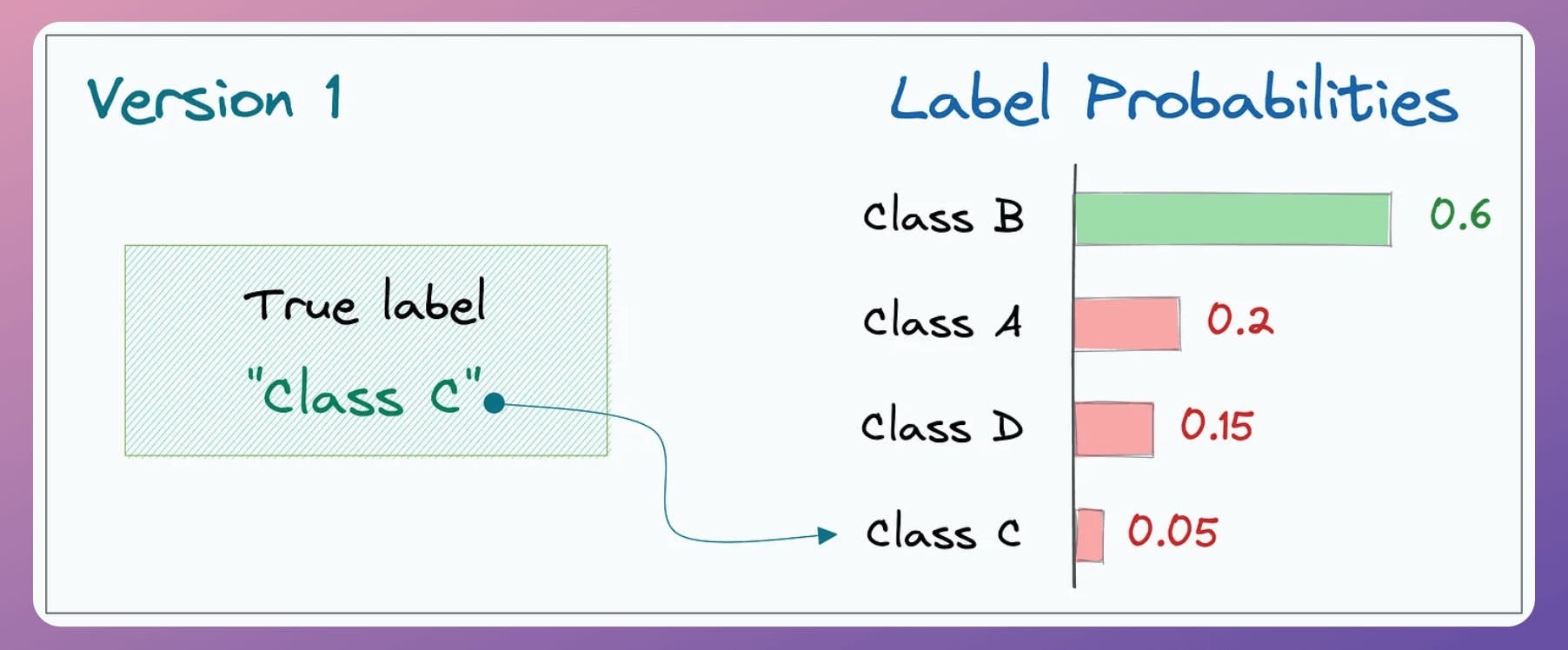
In version 1 of the model, the output probability of “Class C” (the true label) was the lowest, as depicted below:
But in version 2 of the same model, the output probability of “Class C” (the true label) was 2nd highest, as depicted below:
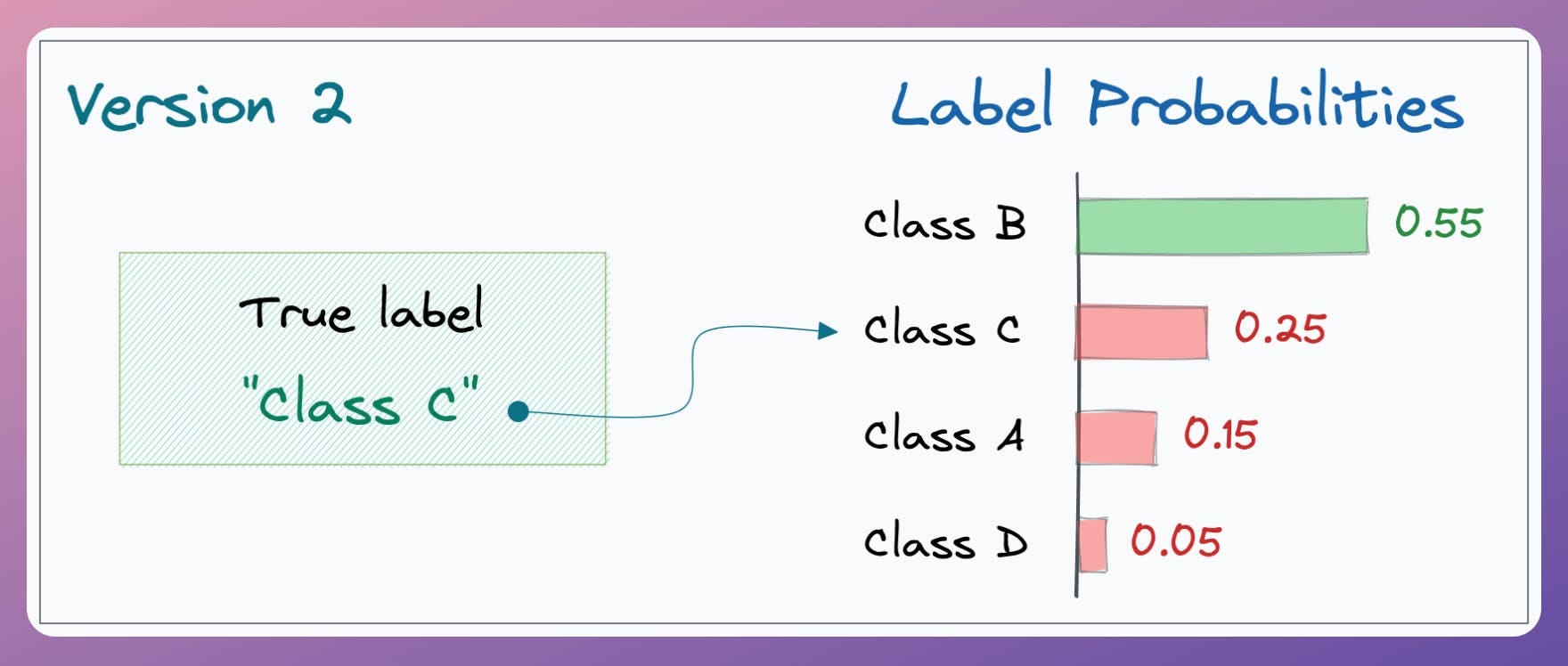
In both cases, the final prediction is incorrect, which is okay.
However, going from “Version 1” to “Version 2” did improve the model.
Nonetheless, Accuracy does not consider this since it only cares about the final prediction.
Solution
If you are iteatively improving a probabilistic multiclass classification model, always use the top-k accuracy score.
It computes whether the correct label is among the top “k” labels predicted probabilities or not.
As you may have guessed, the top-1 accuracy is the traditional accuracy.
This is a better indicator for assessing model improvement efforts.
For instance, if the top-3 accuracy score increases from 75% to 90%, this tells us we are headed in the right direction:
Earlier, the correct prediction was in the top 3 labels only 75% of the time.
But now, the correct prediction is in the top 3 labels 90% of the time.
That said, you use it to assess the model improvement efforts since true predictive power is determined using traditional accuracy.
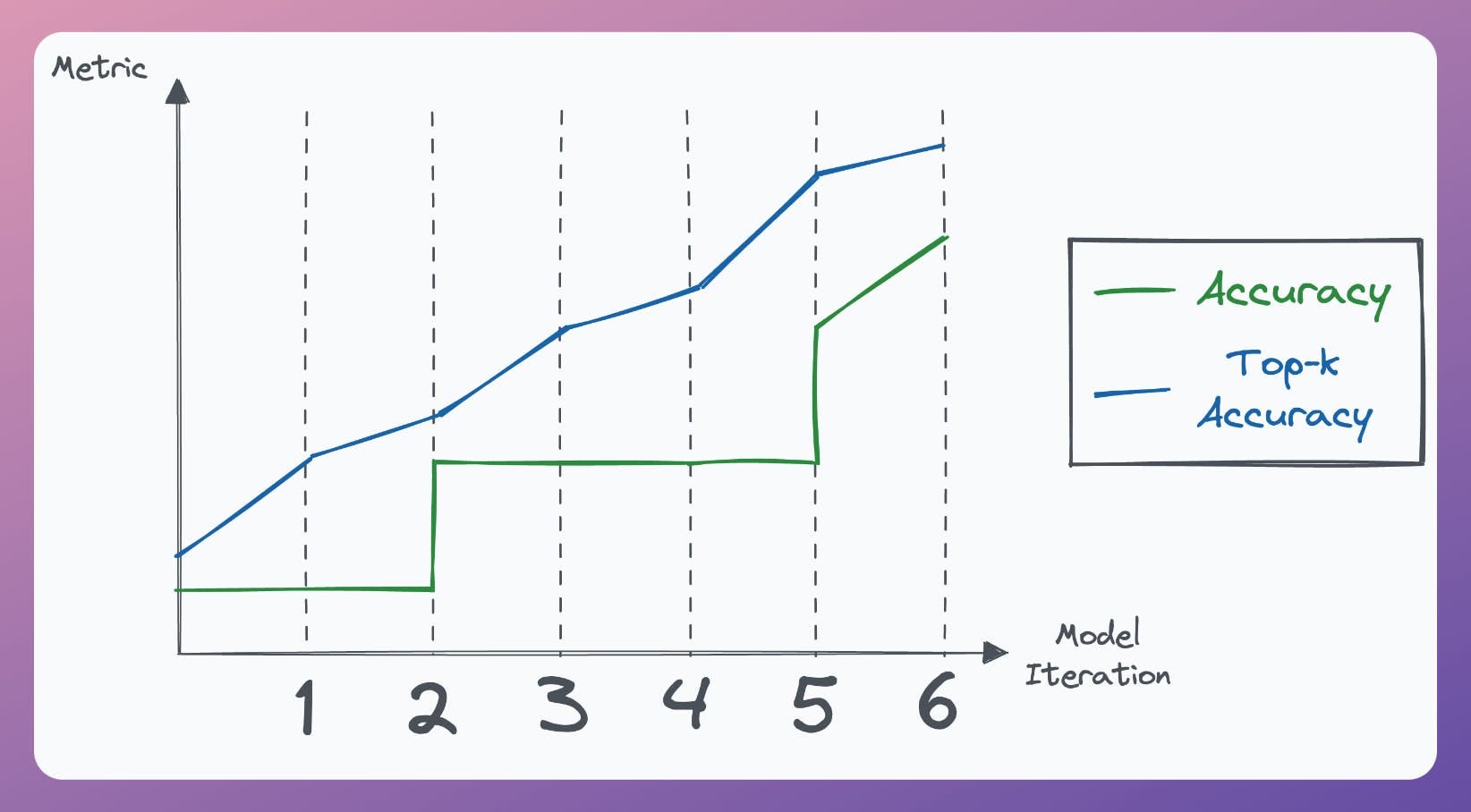
Ideally, “Top-k Accuracy” will increase with iterations. But Accuracy can stay the same, as depicted below:
Top-k accuracy score is also available in Sklearn here.
Isn’t that a great way to assess your model improvement efforts?
If you are looking for more, we covered:
👉 Over to you: What are some other ways to assess model improvement efforts?
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 450k+ data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.