
Activation Pruning in Neural Network
Get rid of useless neurons.

Build LLM apps on audio data with AssemblyAI LeMUR
AssemblyAI LeMUR is a framework that allows you to build LLM apps on speech data in <2 minutes and <10 lines of code.
This can include summarizing the audio, extracting some specific insights from the audio, doing Q&A on the audio, etc. A demo on Andrew Ng’s podcast is shown below:
First, transcribe the audio, which generates a
transcriptobject.

Next, prompt the transcript to generate an LLM output.

LeMUR can ingest over 1,000,000 tokens (~100 hours of audio) in a single API call.
Try LeMUR in AssemblyAI’s playground below:
Thanks to AssemblyAI for sponsoring today’s issue.
Activation pruning
Once we complete network training, we are almost always left with plenty of useless neurons — ones that make nearly zero contribution to the network’s performance, but they still consume memory.
In other words, there is a high percentage of neurons, which, if removed from the trained network, will not affect the performance remarkably:
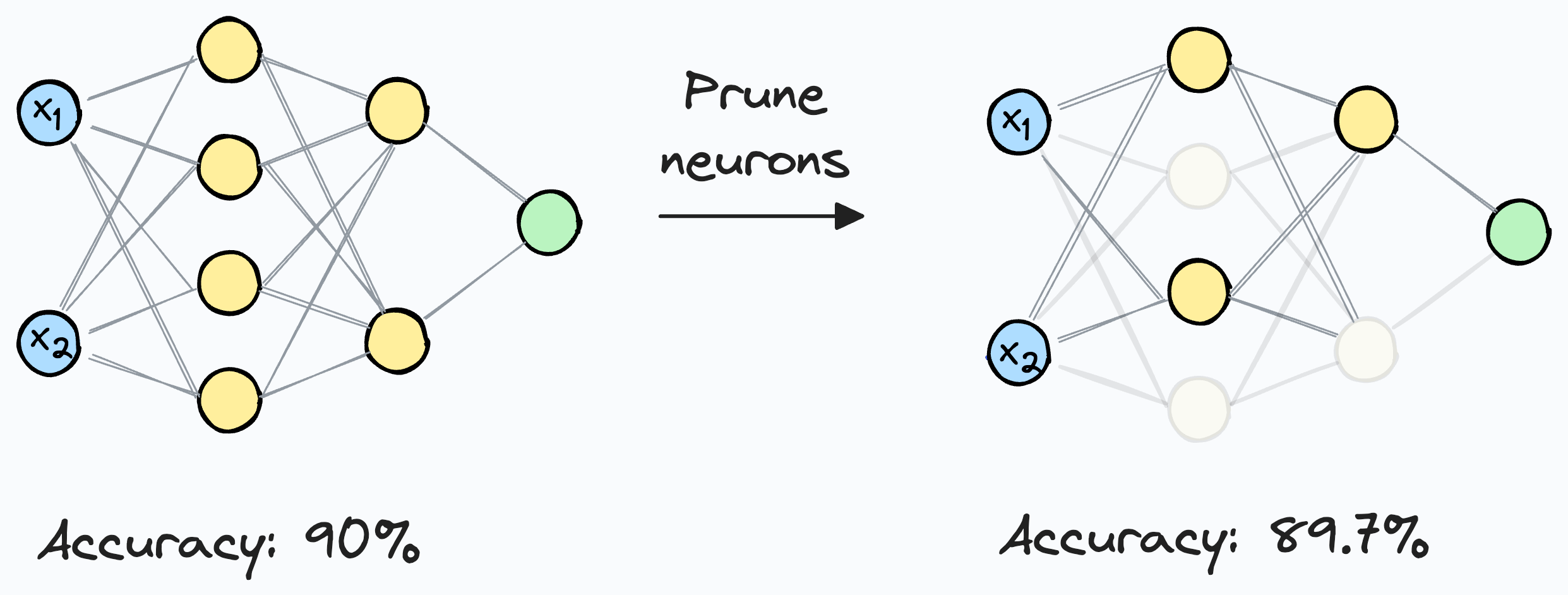
This is something I have experimentally verified over and over across my projects.
Here’s the core idea.
After training is complete, we run the dataset through the model (no backpropagation this time) and analyze the average activation of individual neurons.
Here, we often observe that many neuron activations are always close to near-zero values.

Thus, they can be pruned from the network, as they will have very little impact on the model’s output.
For pruning, we can decide on a pruning threshold (λ) and prune all neurons whose activations are less than this threshold.
More specifically, if a neuron rarely possesses a high activation value, then it is fair to assume that it isn’t contributing to the model’s output, and we can safely prune it.
This makes intuitive sense as well.
The following table compares the accuracy of the pruned model with the original (full) model across a range of pruning thresholds (λ):

Notice something here.
At a pruning threshold λ=0.4, the validation accuracy of the model drops by just 0.62%, but the number of parameters drops by 72%.

That is a huge reduction, while both models being almost equally good!
Of course, there is a trade-off because we are not doing as well as the original model.
But in many cases, especially when deploying ML models, accuracy is not the only metric we optimize for.
Instead, several operational metrics like efficiency, speed, memory consumption, etc., are also a key deciding factor.

That is why model compression techniques are so crucial in such cases.
If you want to learn more about model compression, with implementation, we discussed them in this deep dive: Model Compression: A Critical Step Towards Efficient Machine Learning.
While we only discussed one such technique today (activation pruning), the article discusses 6 model compression techniques, with PyTorch implementation.
Moreover, here’s a production/deployment roadmap for you to upskill if these ideas intimidate you:
First, you would have to compress the model and productionize it. Read these guides:
Model Compression: A Critical Step Towards Efficient Machine Learning.
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
If you use sklearn, here’s a guide that teaches you to optimize models like decision trees with tensor operations: Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Next, you move to deployment. Here’s a beginner-friendly hands-on guide that teaches you how to deploy a model, manage dependencies, set up model registry, etc.: Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
Although you would have tested the model locally, it is still wise to test it in production. There are risk-free (or low-risk) methods to do that. Read this to learn them: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Everything is covered in a detailed and beginner-friendly manner, with implementations.
👉 Over to you: What are some other ways to make ML models more production-friendly?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 105k+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.