
Active Learning in ML
Avoid tedious annotation tasks.

Make your RAG application 10x smarter!
ColiVara is a unique document retrieval method that does not need chunking or text processing.
It still feels like RAG but without OCR, text extraction, broken tables, or missing images.

Here’s why it’s powerful:
Vision-based indexing
100+ file format support
Seamless local or cloud quickstart
State-of-the-art multimodal retrieval
APIs & SDKs for both Python/TypeScript
Late-interaction embeddings for extra accuracy
No vector DB management (pgVector under the hood)
Check out the GitHub repo here: ColiVara GitHub.
Thanks to ColiVara for partnering with us on today’s newsletter issue!
Active learning in ML
Data annotation is difficult, expensive and time-consuming.
Active learning is a relatively easy and inexpensive way to build supervised models when you don’t have annotated data to begin with.
As the name suggests, the idea is to build the model with active human feedback on examples it is struggling with.
The visual below summarizes this:
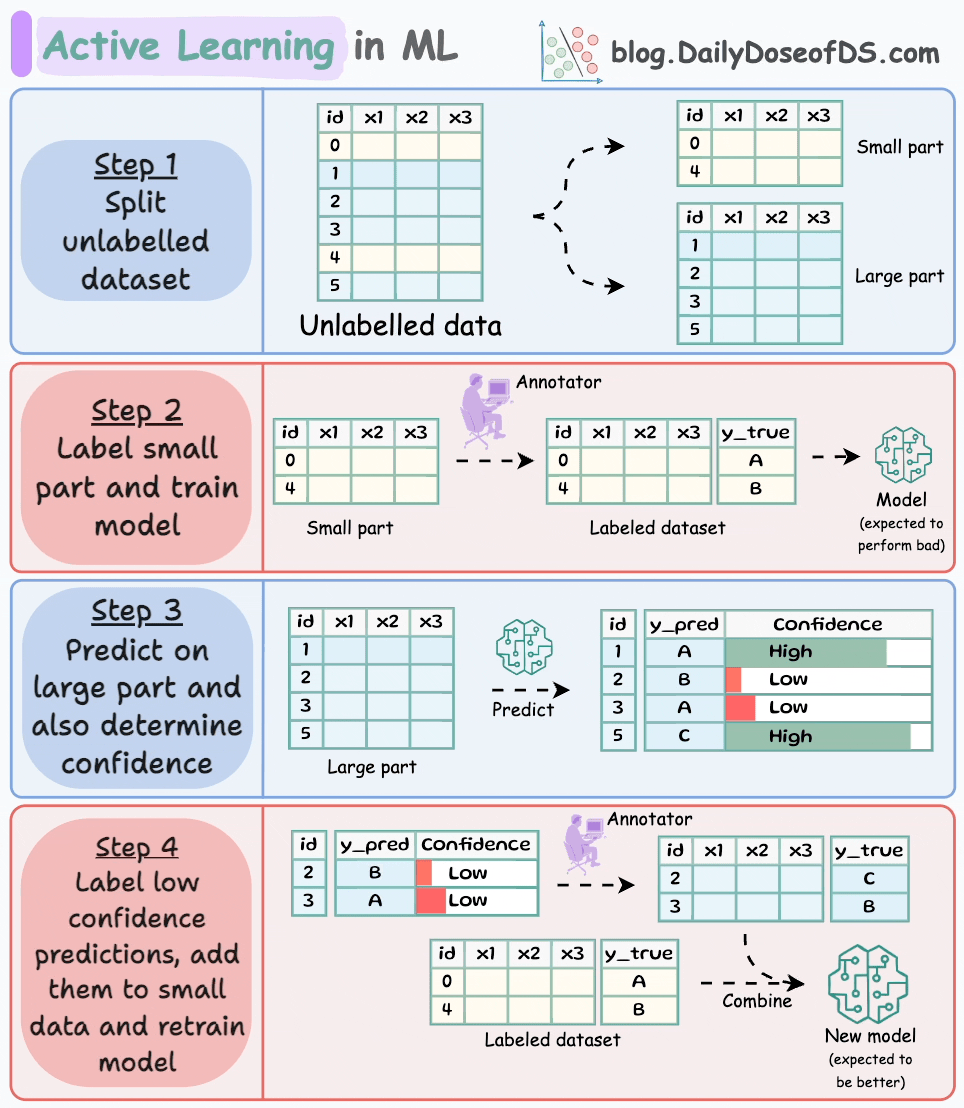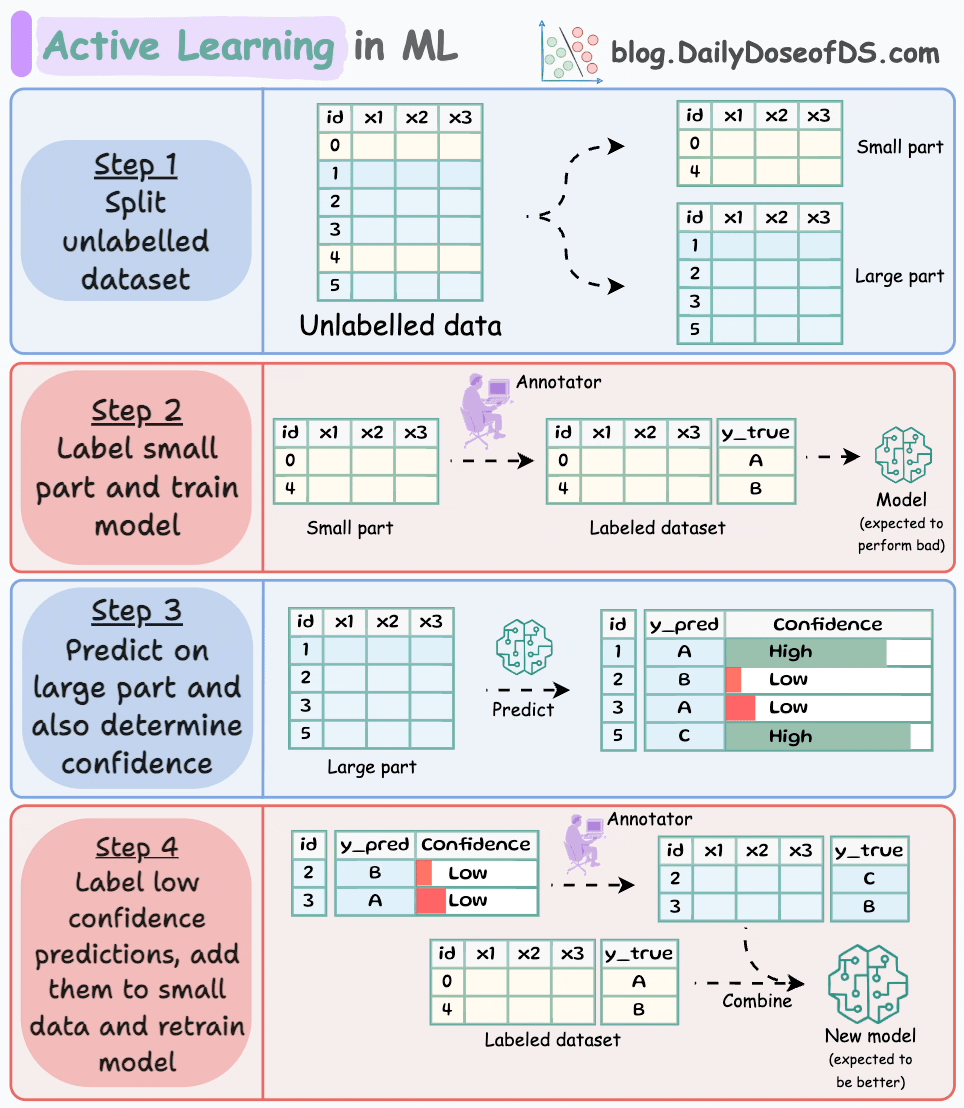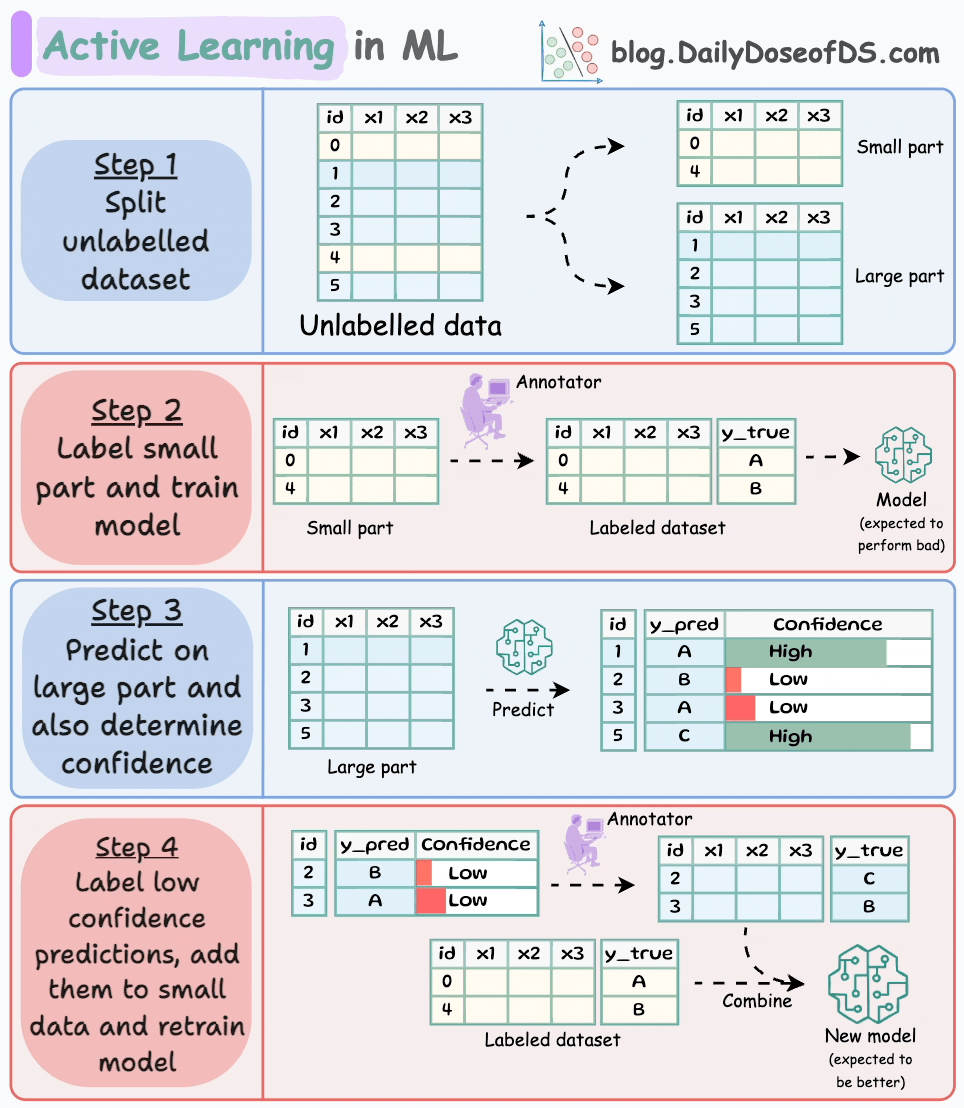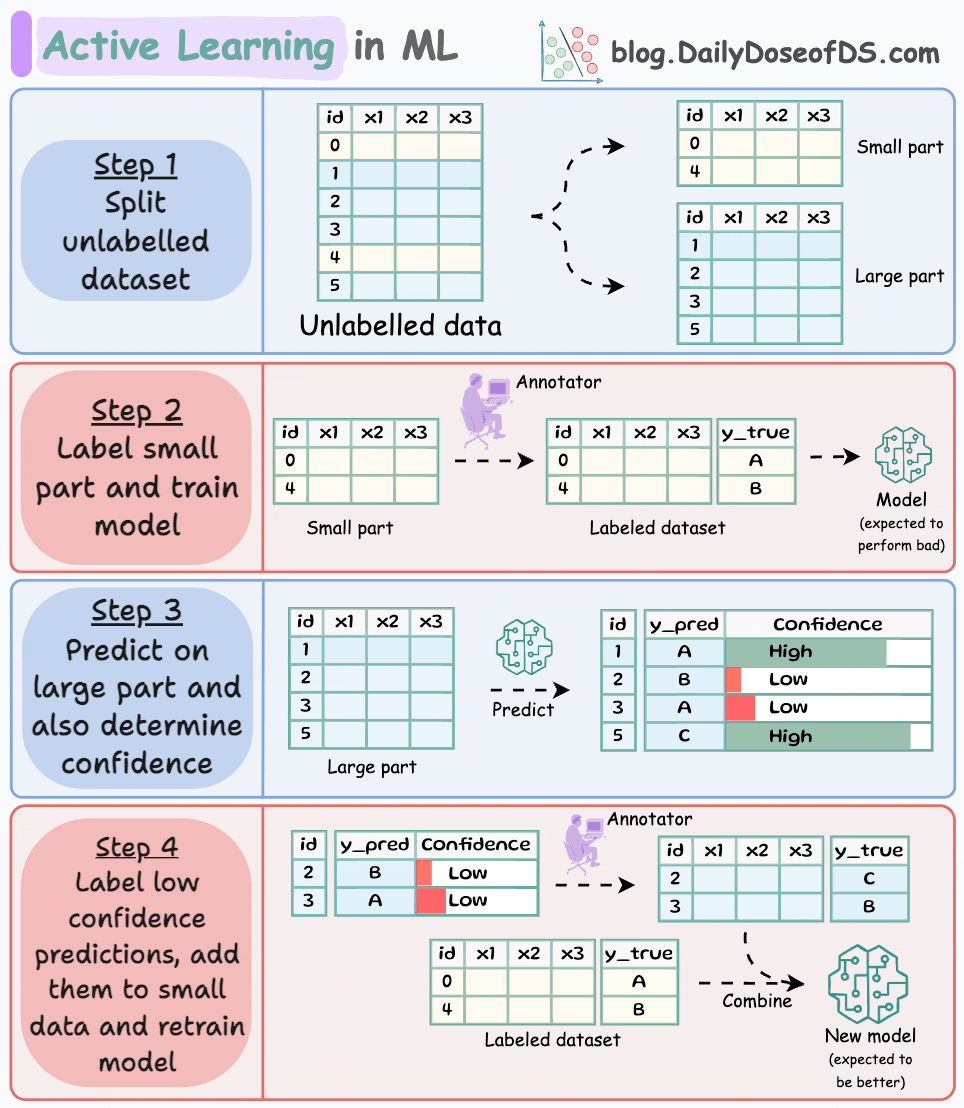
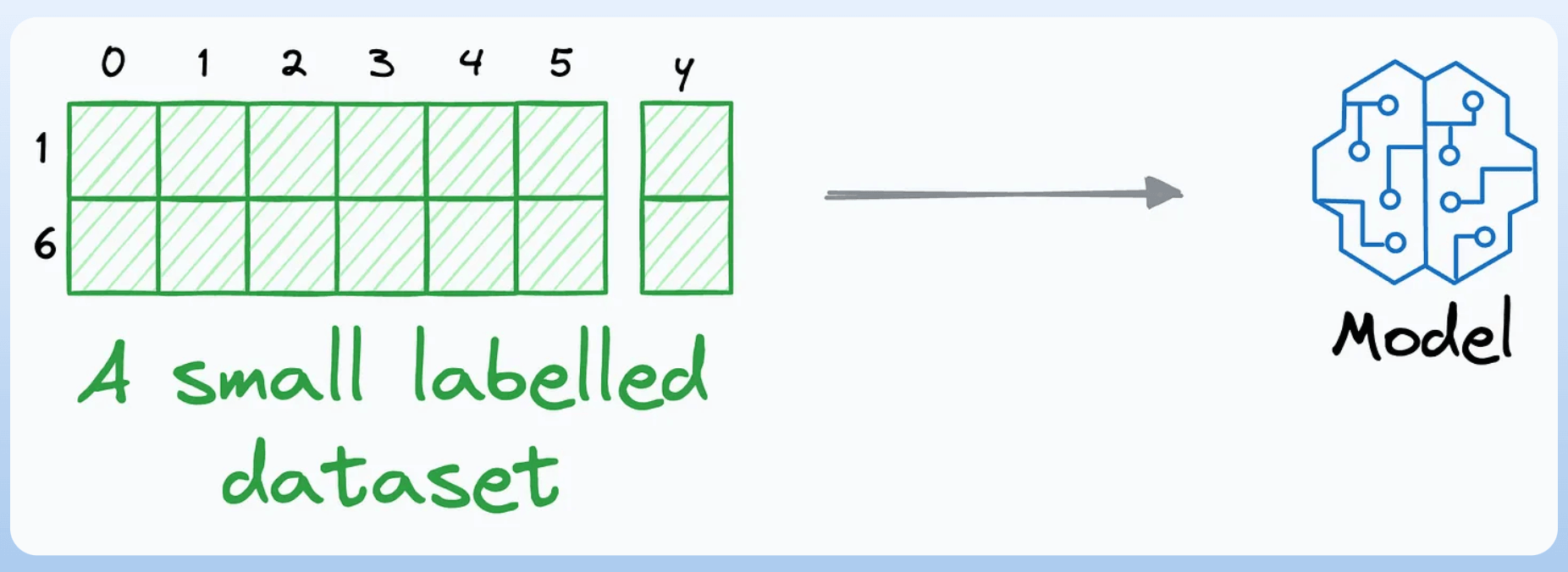
We begin by manually labeling a tiny percentage of the dataset:

I have used active learning (successfully) while labeling as low as ~1% of the dataset, so try something in that range.
Next, build a model on this small labeled dataset. This won’t be a good model, but that’s fine:
Next, generate predictions on the dataset we did not label:

Since the dataset is unlabeled, we cannot determine if these predictions are correct.
That’s why we train a model that can implicitly or explicitly provide a confidence level with its predictions.
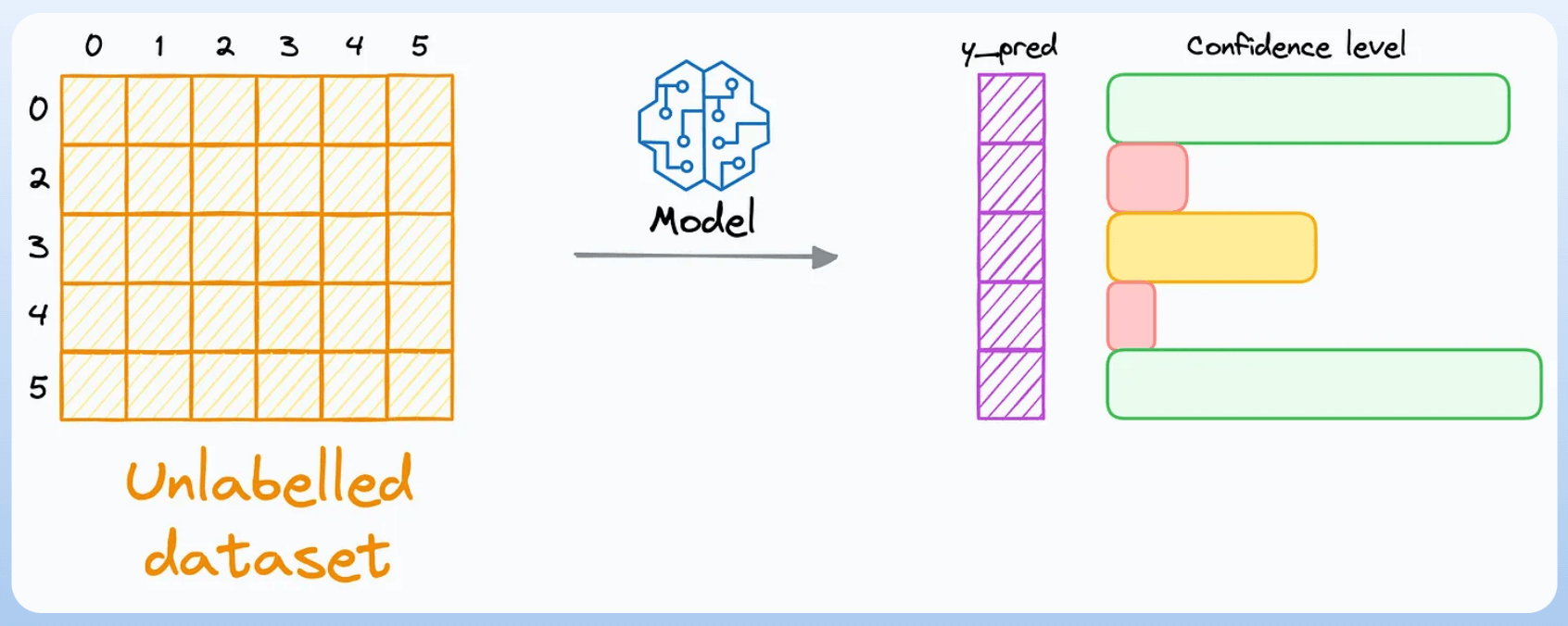
Probabilistic models are a good fit since one can determine a proxy for confidence level from probabilistic outputs.
This is shown below:

In the above two examples, consider the gap between 1st and 2nd highest probabilities:
In example #1, the gap is large. This can indicate that the model is confident in its prediction.
In example #2, the gap is small. This can indicate that the model is NOT confident in its prediction.
After generating the confidence, rank all predictions in order of confidence:

Provide human label to the low-confidence predictions and feed it back to the model with the seed dataset:

There’s no point labeling predictions the model is already confident with. This diagram should help you understand this point:

Repeat the process a few times (train → generate predictions and confidence → label low confidence prediction) and stop when you are satisfied with the performance.
Active learning is a huge time-saver in building supervised models on unlabeled datasets.
The only thing that you have to be careful about is generating confidence measures.
If you mess this up, it will affect every subsequent training step.
Also, while combining the low-confidence data with the seed data, we can use the high-confidence data. The labels would be the model’s predictions.

This variant of active learning is called cooperative learning.
👉 Over to you: Do you like cooperative learning or active learning?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.