
AI Agent Crash Course—Part 4
...with implementation.

After completing the RAG crash course, we moved to an AI Agent crash course recently.
Part 4 is available here: AI Agents Crash Course—Part 4 (With Implementation).
Just like the RAG crash course, we are covering everything about AI agents in detail as we progress to fully equip you with building agentic systems:
Fundamentals (Why Agents? The Motivation; Create Agents, Tasks, Tools, etc.)
Memory for Agents
Agentic Flows
Guardrails for Agents
Implementing Agentic design patterns.
Agentic RAG
Optimizing Agents for production, and more.
Read here: AI Agents Crash Course—Part 4 (With Implementation).
Why care?
Given the scale and capabilities of modern LLMs, it feels limiting to use them as “standalone generative models” for pretty ordinary tasks like text summarization, text completion, code completion, etc.
Instead, their true potential is only realized when you build systems around these models, where they are allowed to:
access, retrieve, and filter data from relevant sources,
analyze and process this data to make real-time decisions and more.

RAG was a pretty successful step towards building such compound AI systems:
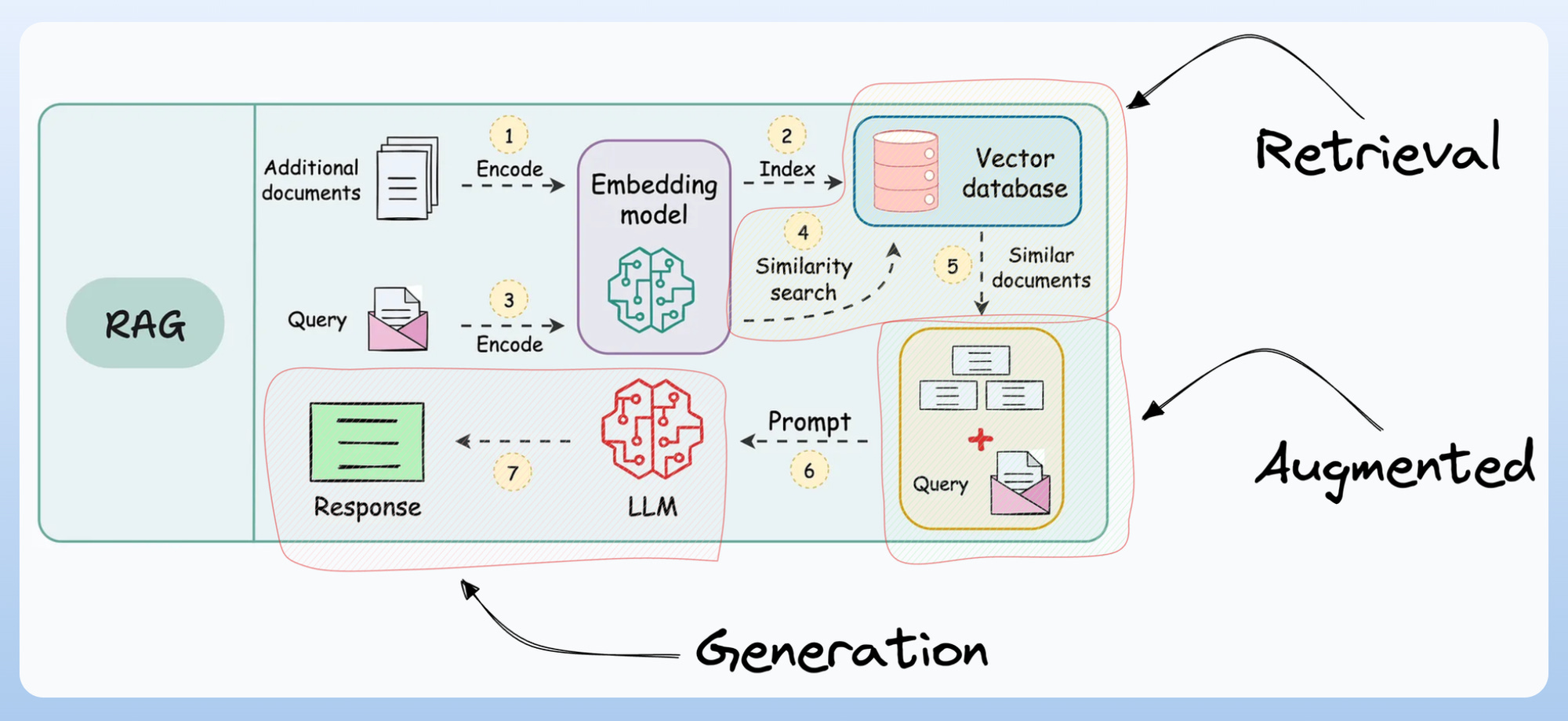
But since most RAG systems follow a programmatic flow (you, as a programmer, define the steps, the database to search for, the context to retrieve, etc.), it does not unlock the full autonomy one may expect these compound AI systems to possess in some situations.
That is why the primary focus in 2024 was (and going ahead in 2025 will be) on building and shipping AI Agents.
These are autonomous systems that can reason, think, plan, figure out the relevant sources and extract information from them when needed, take actions, and even correct themselves if something goes wrong.
In this full crash course, we shall cover everything you need to know about building robust Agentic systems, starting from the fundamentals.
Of course, if you have never worked with LLMs, that’s okay.
We cover everything in a practical and beginner-friendly way.
Thanks for reading!
In case you missed it
#1) Transformer vs. Mixture of Experts
Mixture of Experts (MoE) is a popular architecture that uses different "experts" to improve Transformer models.
The visual below explains how they differ from Transformers.
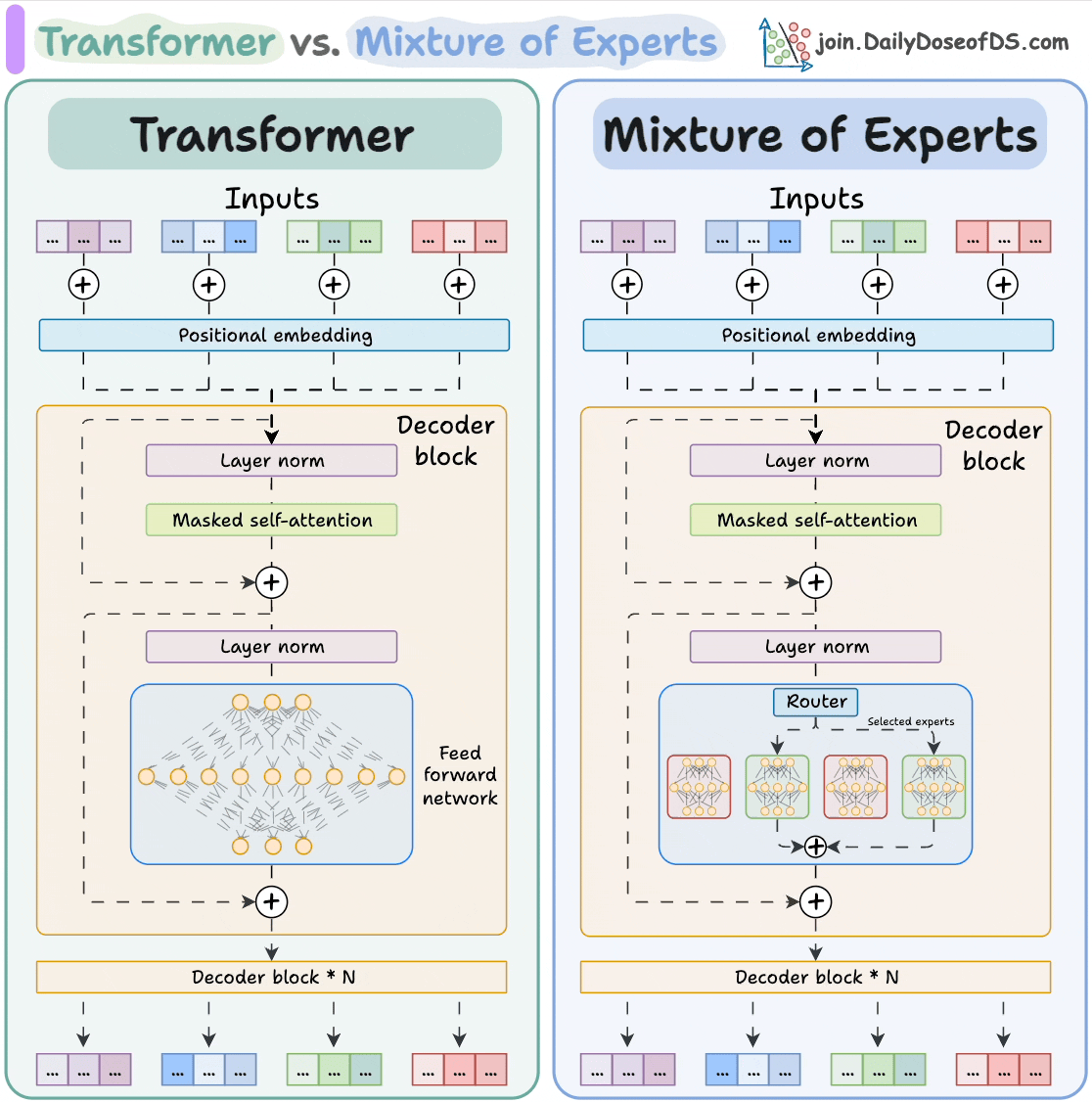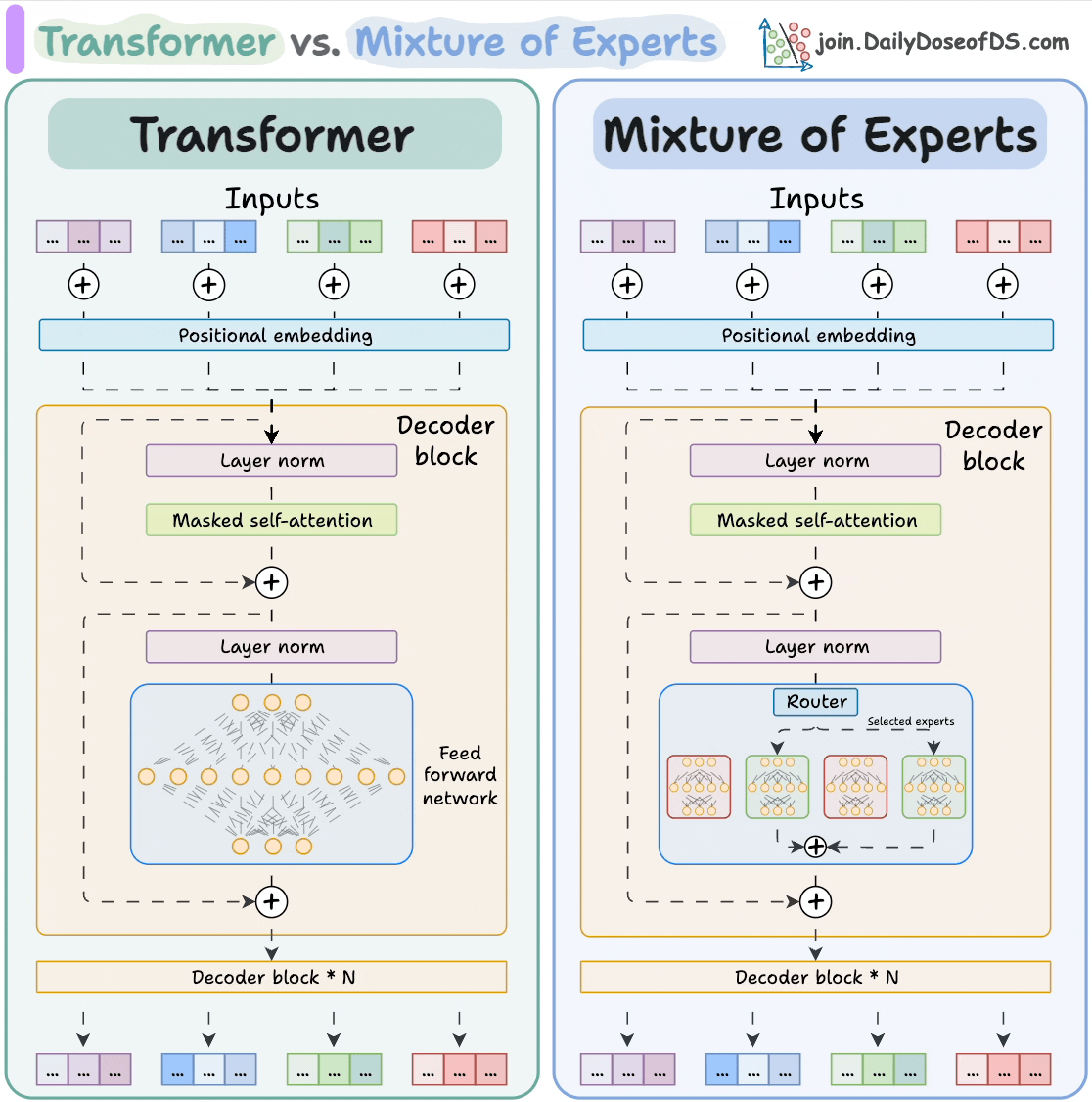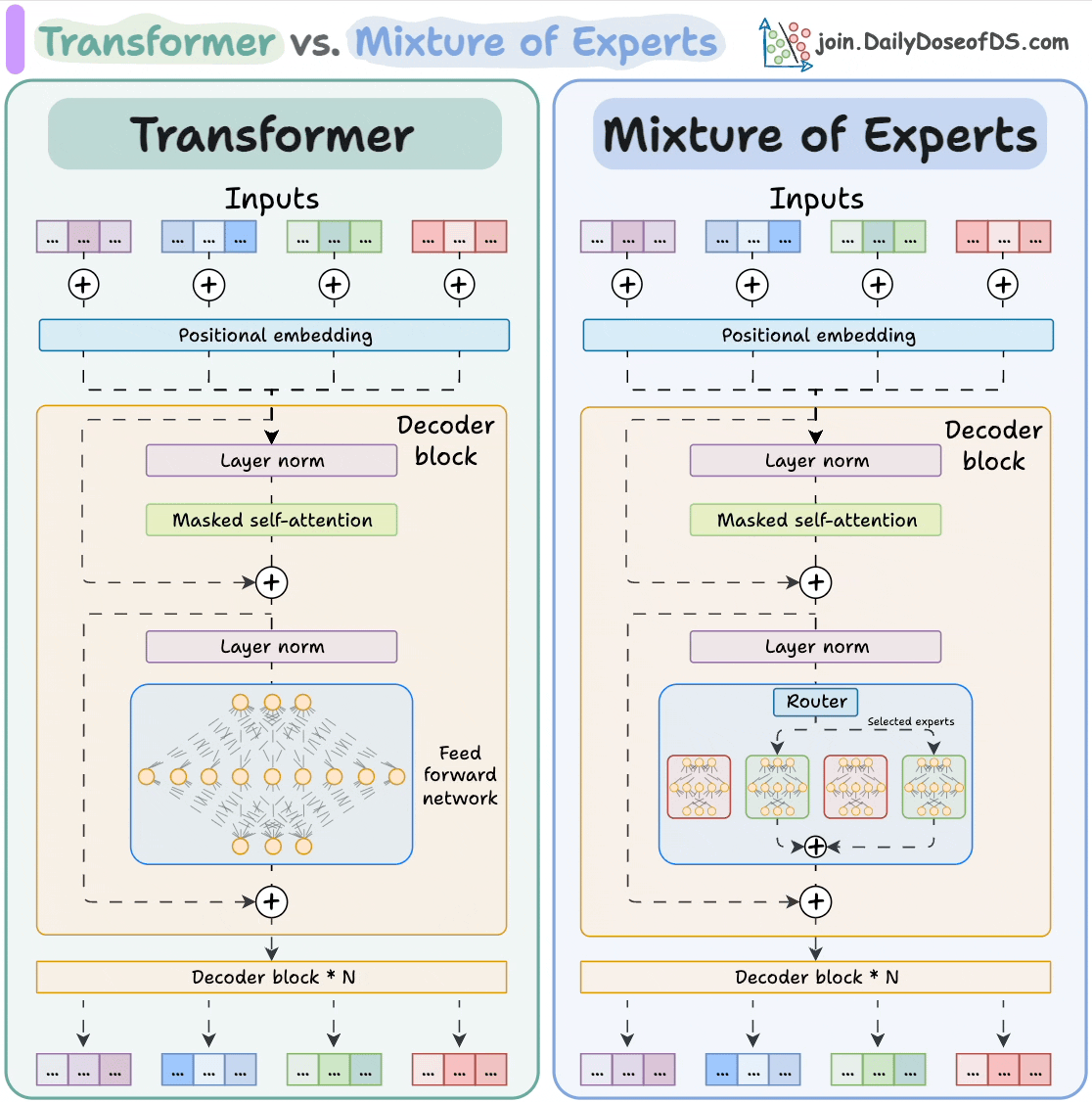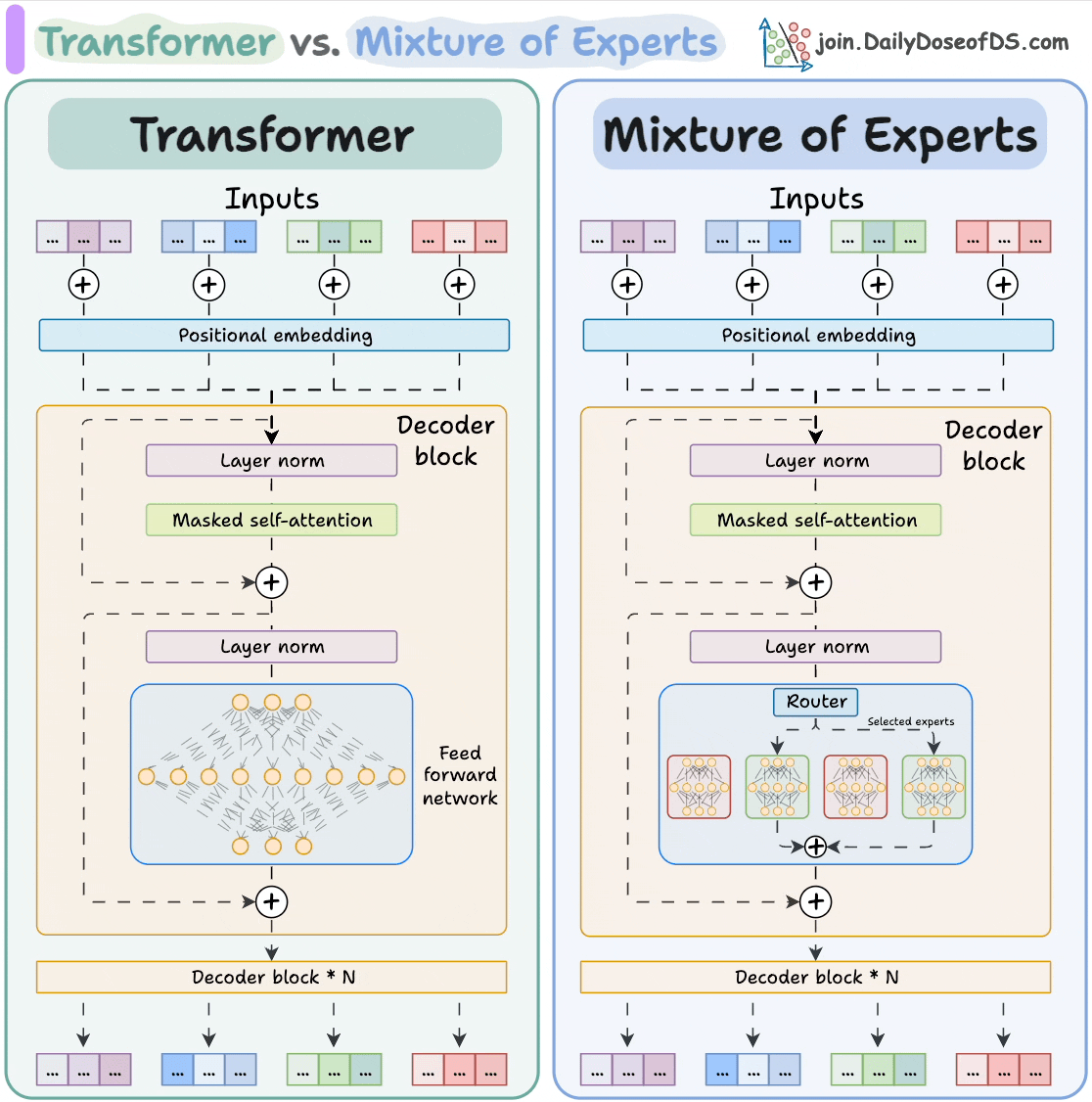
MoEs have more parameters to load. However, a fraction of them are activated since we only select some experts.
This leads to faster inference. Mixtral 8x7B by MistralAI is one famous LLM that is based on MoE.
But of course, there are challenges in training them.
We covered them in a recent newsletter issue here →
#2) RAG vs. Agentic RAG
RAG has some issues:
It retrieves once and generates once. If the context isn’t enough, it cannot dynamically search for more info.
It cannot reason through complex queries.
The system can’t modify its strategy based on the problem.
Agentic RAG attempts to solve this.
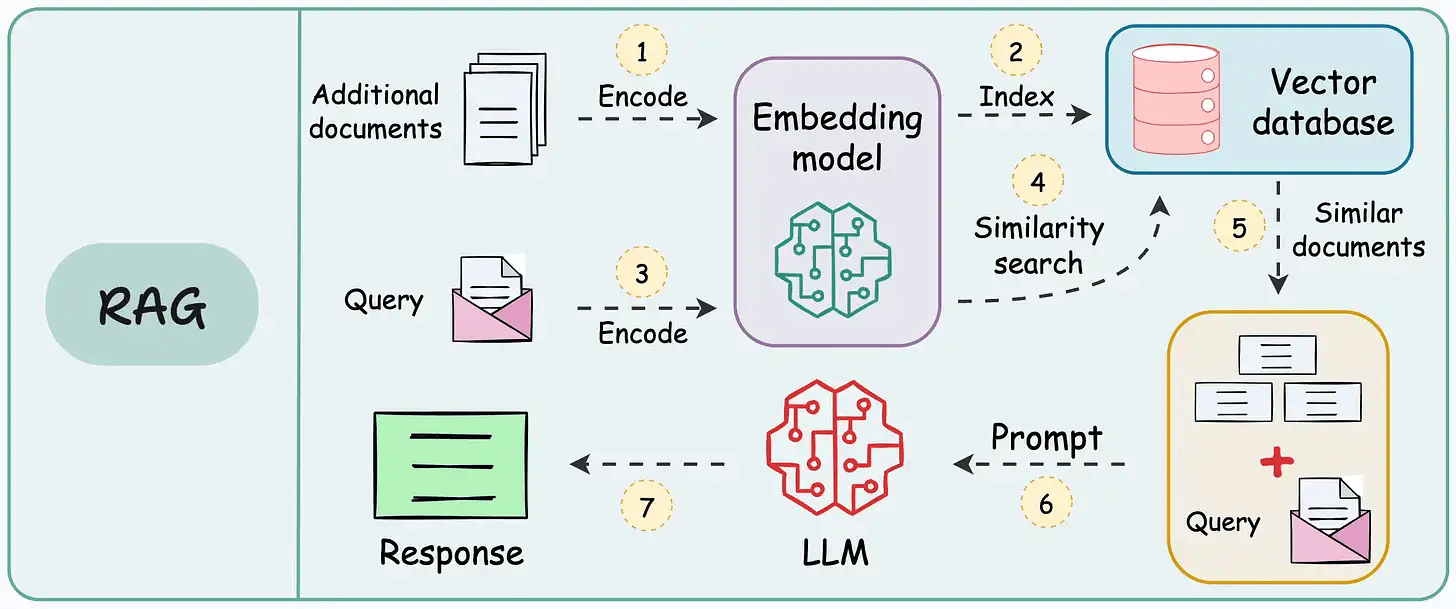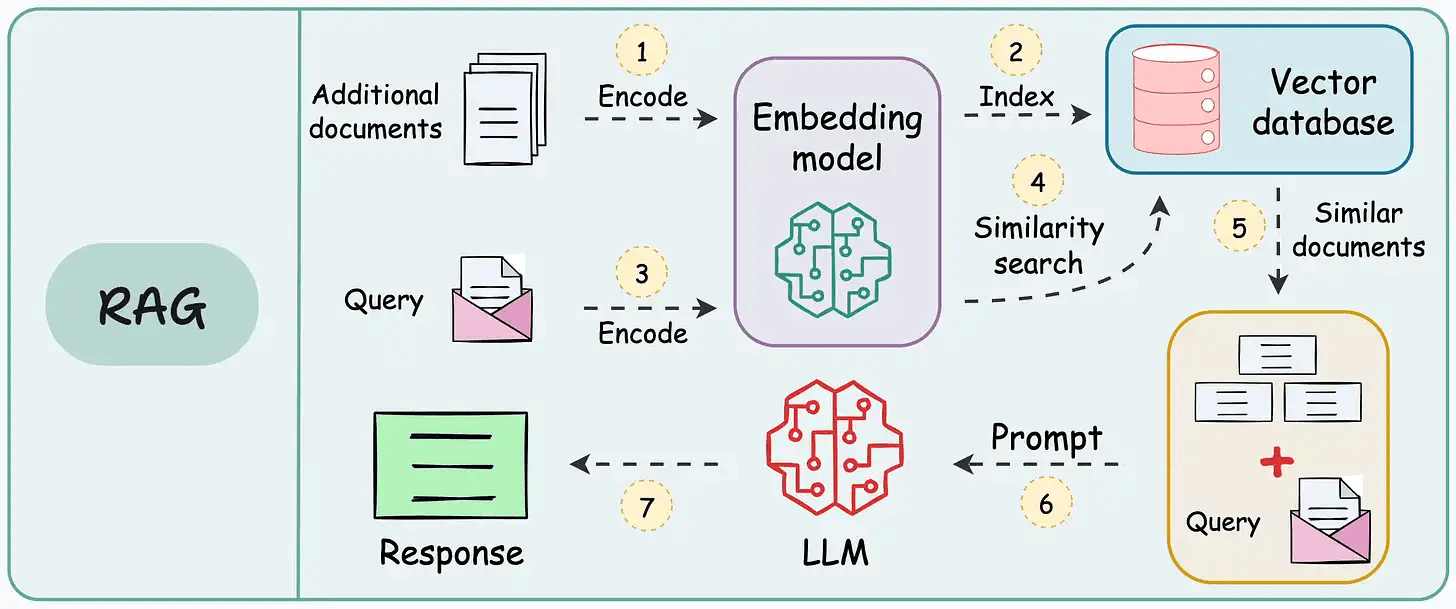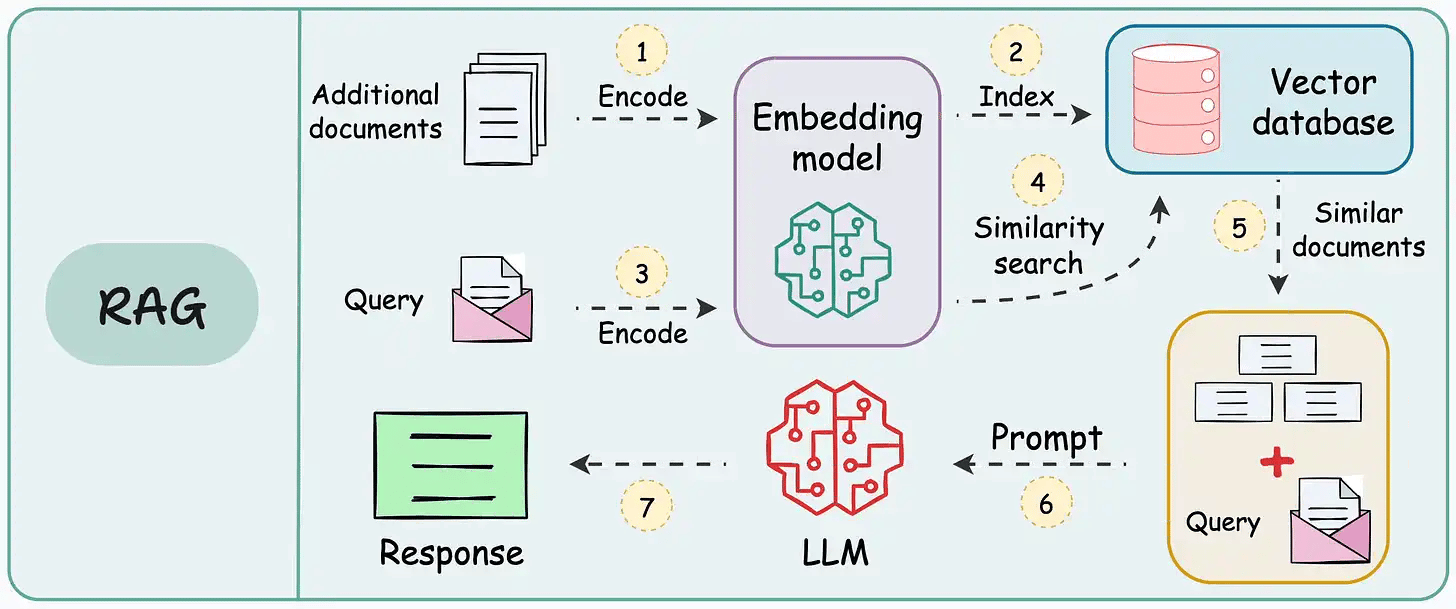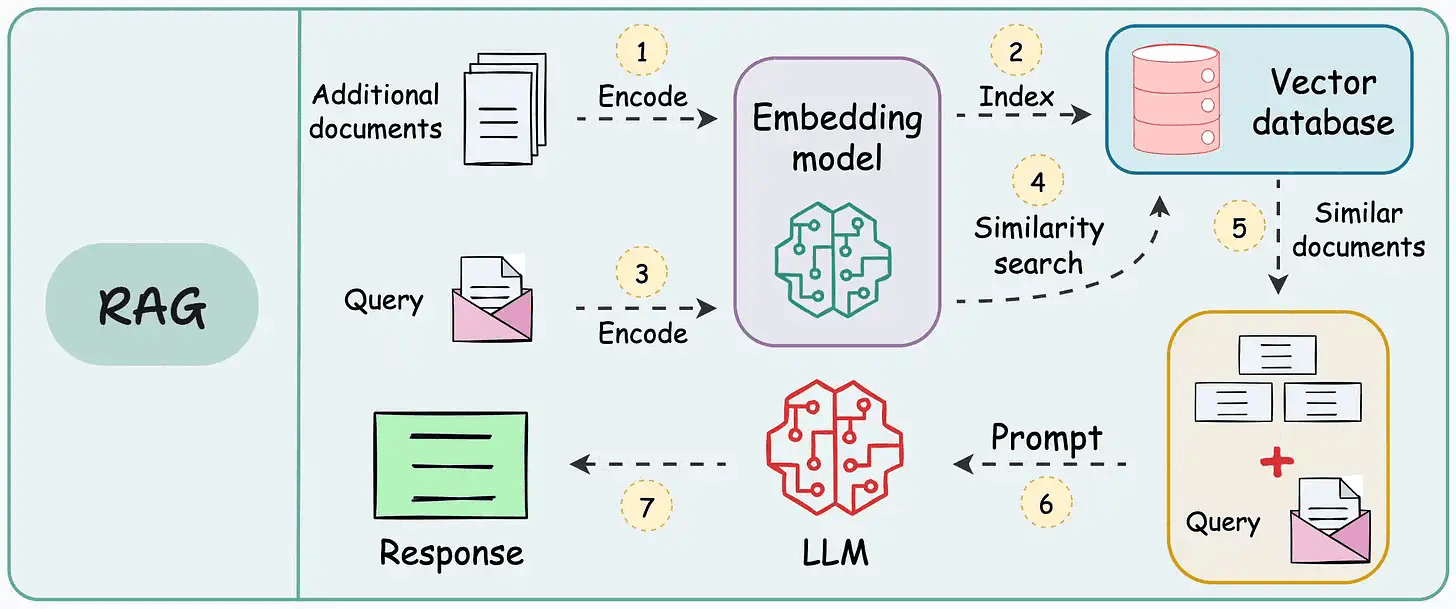
The following visual depicts how it differs from traditional RAG.
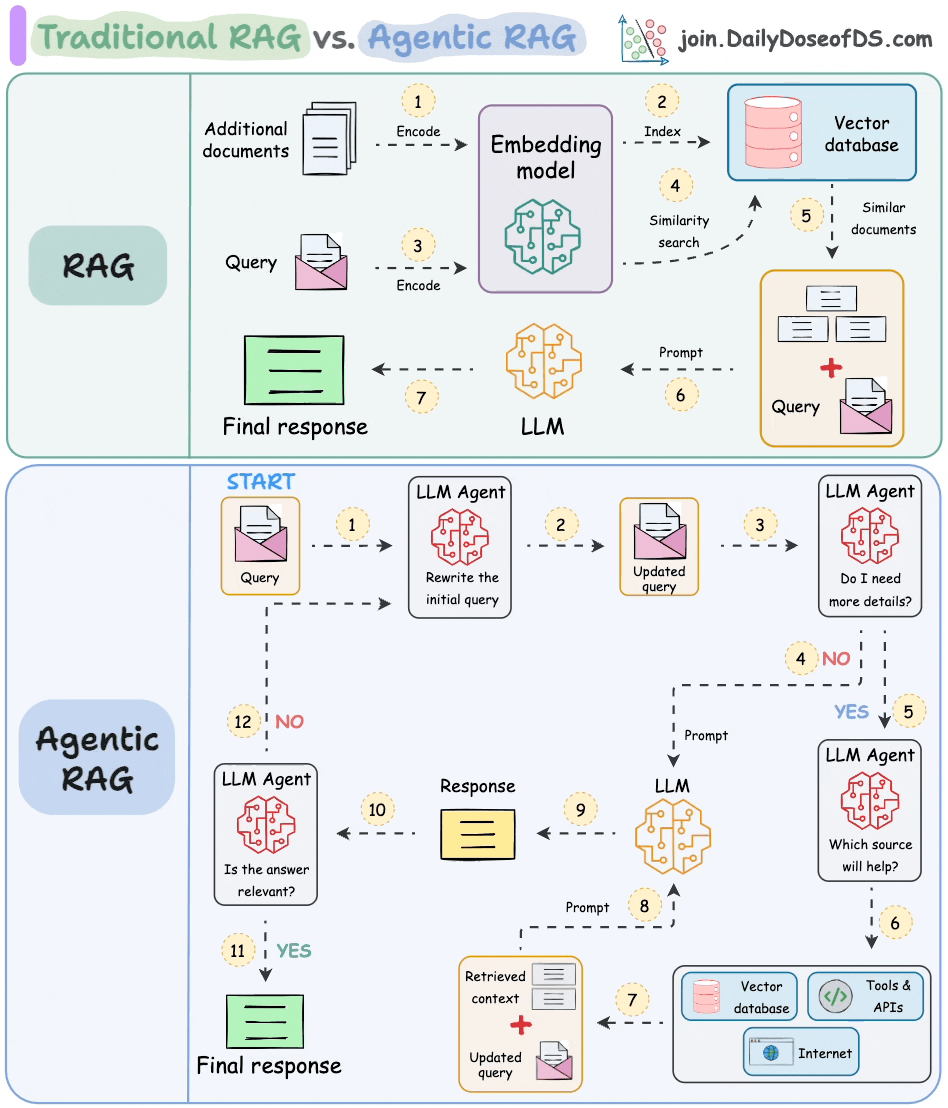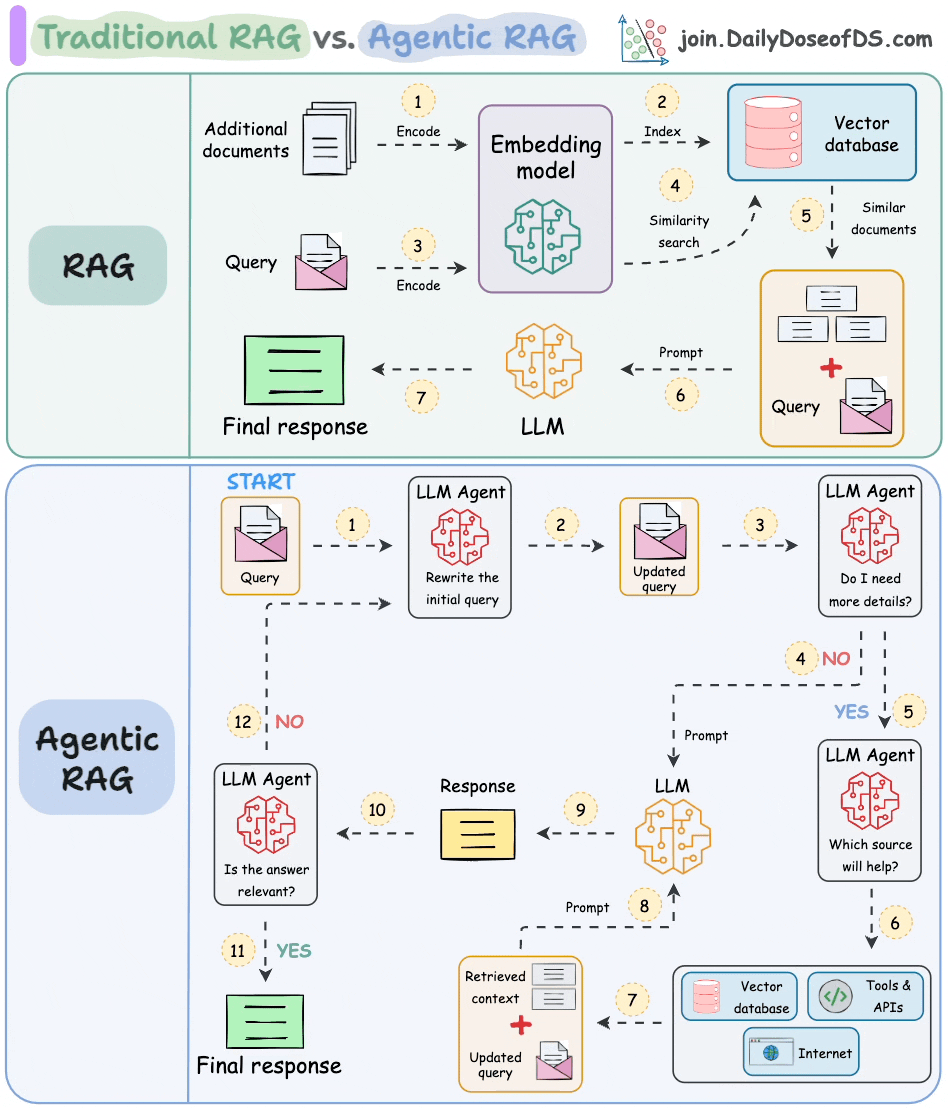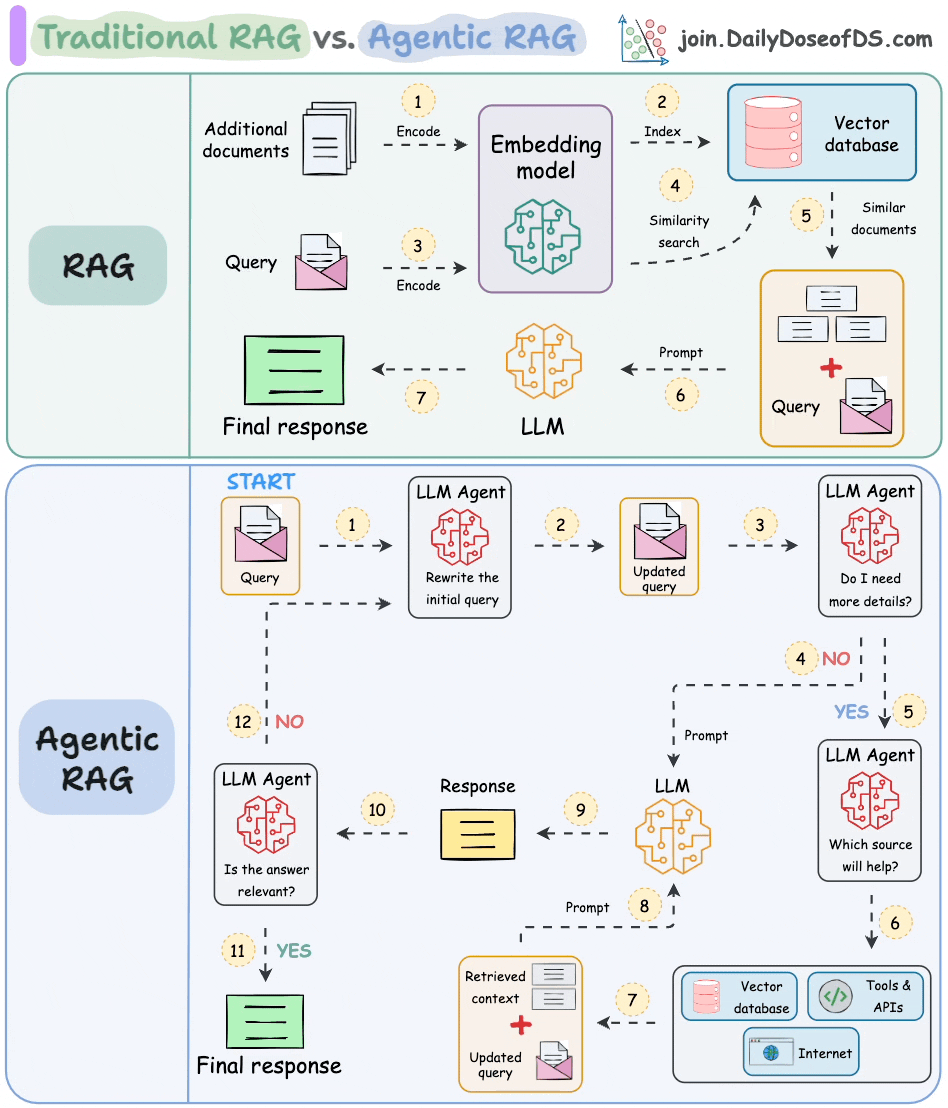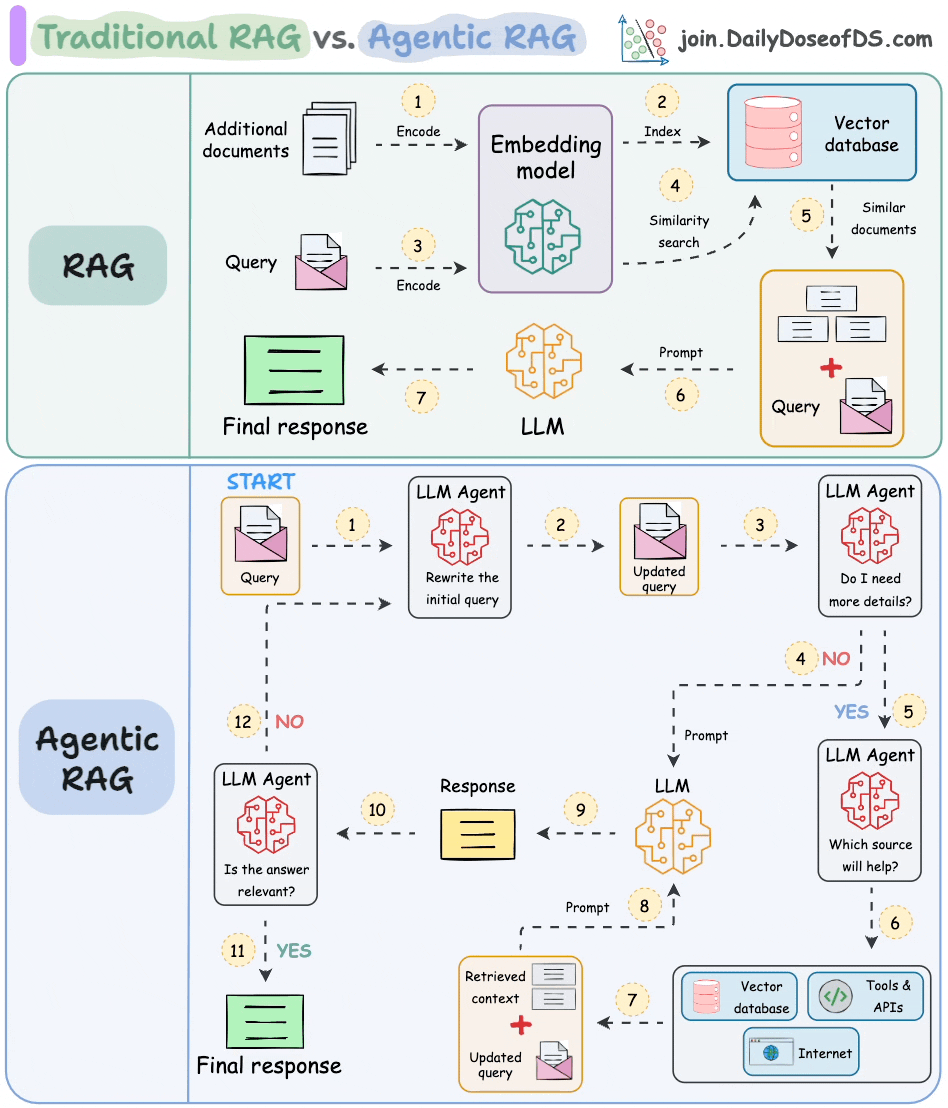
The core idea is to introduce agentic behaviors at each stage of RAG.
Steps 1-2) An agent rewrites the query (removing spelling mistakes, etc.)
Step 3-8) An agent decides if it needs more context.
If not, the rewritten query is sent to the LLM.
If yes, an agent finds the best external source to fetch context, to pass it to the LLM.
Step 9) We get a response.
Step 10-12) An agent checks if the answer is relevant.
If yes, return the response.
If not, go back to Step 1.
This continues for a few iterations until we get a response or the system admits it cannot answer the query.
This makes RAG more robust since agents ensure individual outcomes are aligned with the goal.
That said, the diagram shows one of the many blueprints an agentic RAG system may possess.
You can adapt it according to your specific use case.
Soon, we shall cover Agentic RAG and many more related techniques to building robust RAG systems.
In the meantime, make sure you are fully equipped with everything we have covered so far like:
Thanks for reading!