
AI Agent Deployment Strategies
...covered with usage in production.

Top AI/ML competitions for developers in 2025
We compiled this list of AI/ML competitions that are happening between October and December 2025:
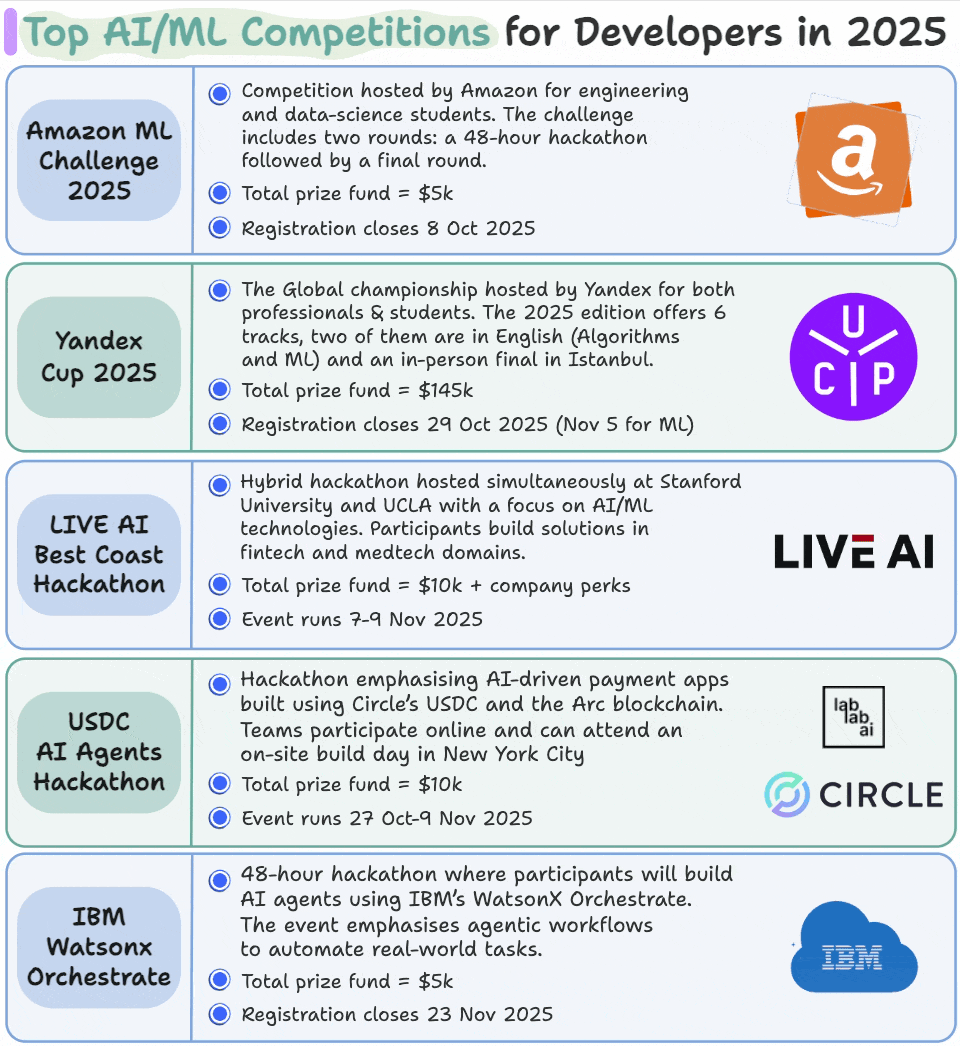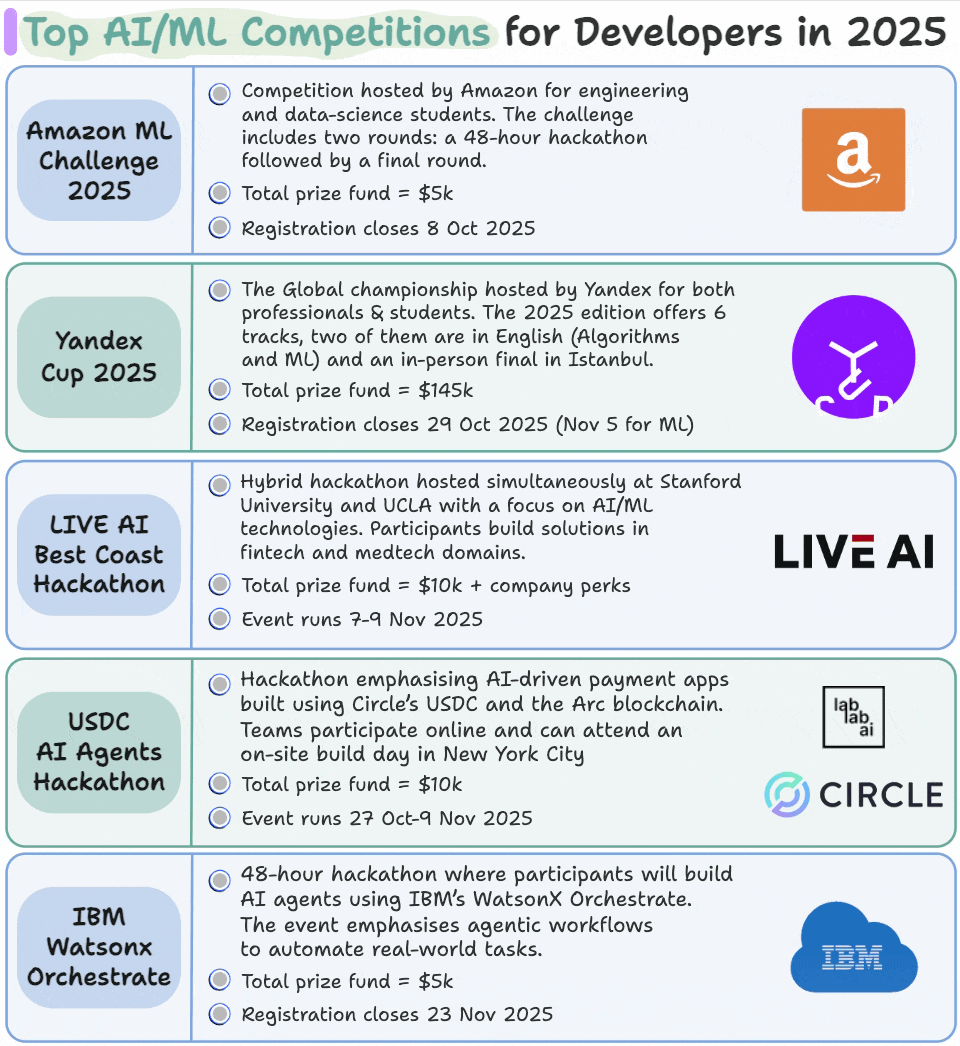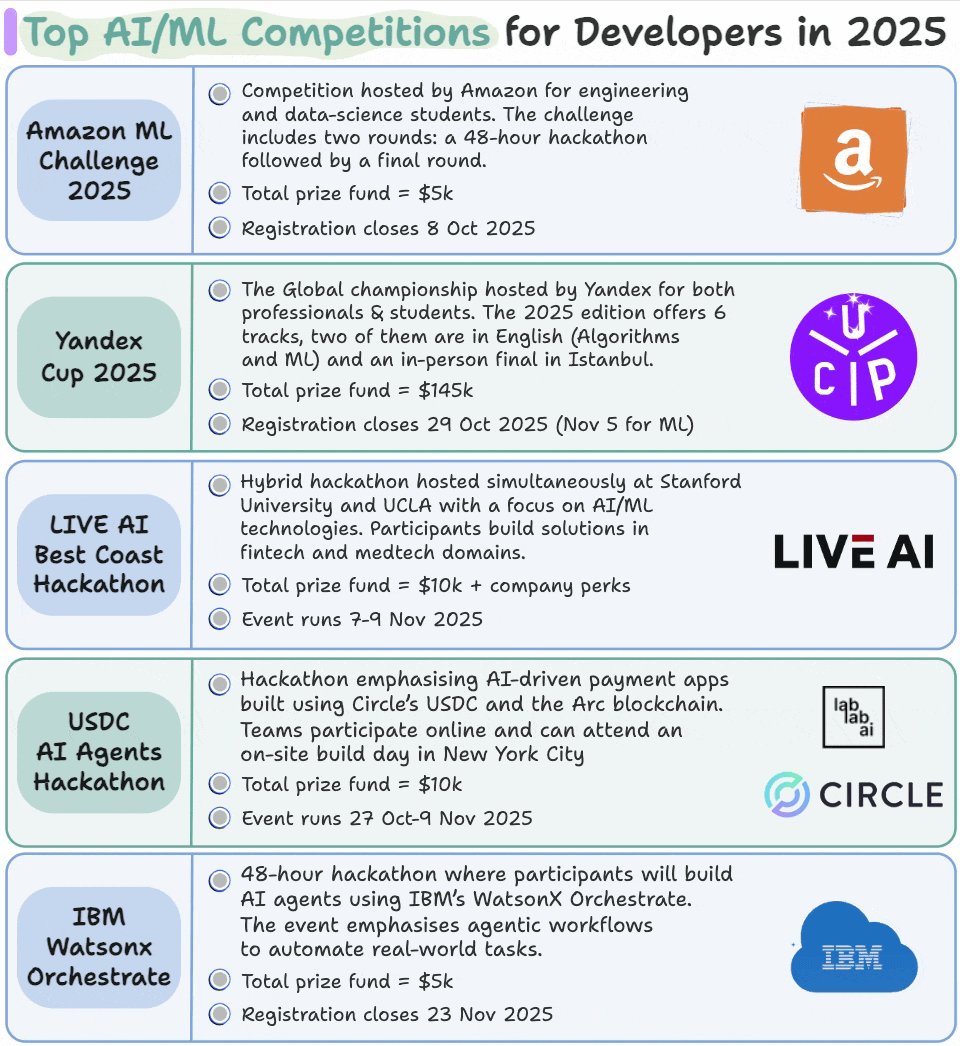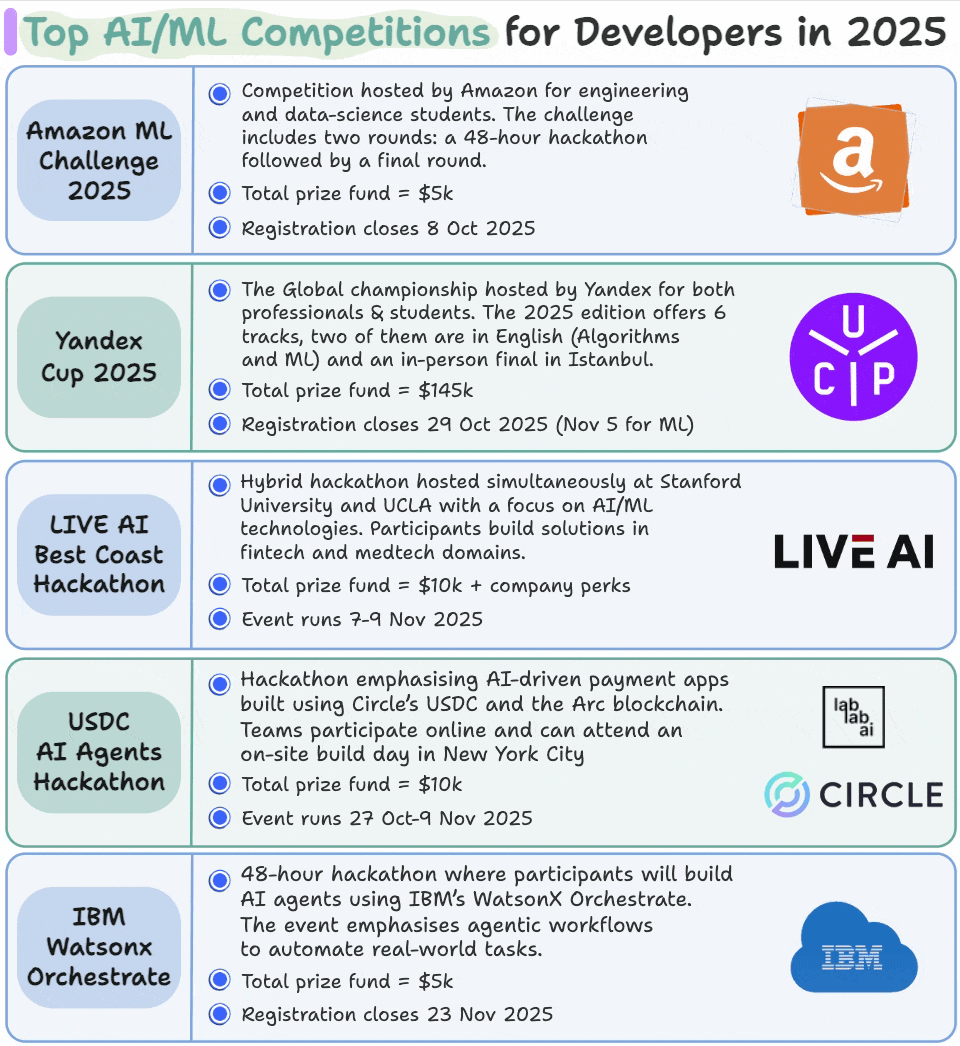
We feel such competitions are one of the fastest ways to grow as an AI/ML professional because:
You get to tackle real-world problems under time constraints.
A strong performance in events like the Amazon ML Challenge or Yandex Cup gives you concrete, demonstrable achievements for your portfolio.
You get to meet peers, mentors, and industry leaders.
Many hackathons and competitions push participants to use modern stacks, like agentic AI, cloud AI services
You can register for them below:
AI Agent deployment strategies!
Deploying AI agents isn’t one-size-fits-all. The architecture you choose can make or break your agent’s performance, cost efficiency, and user experience.
Here are the 4 main deployment patterns you need to know:
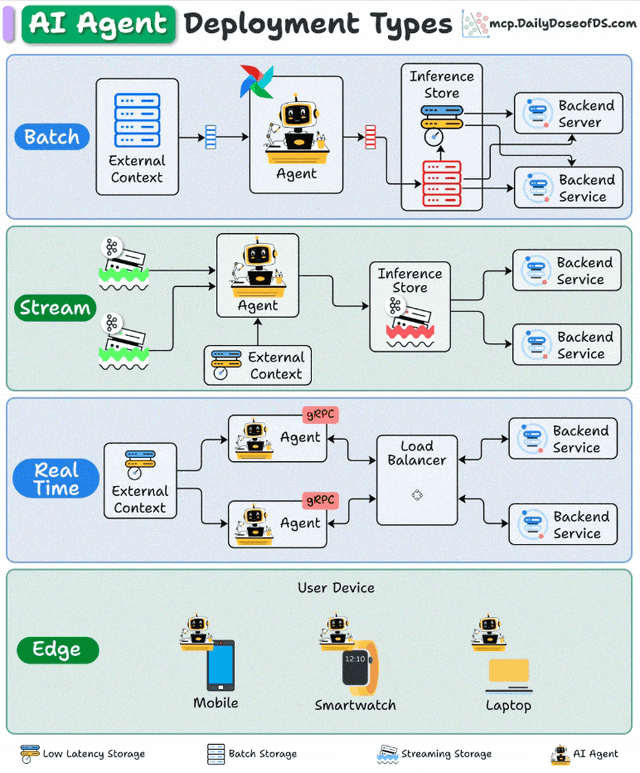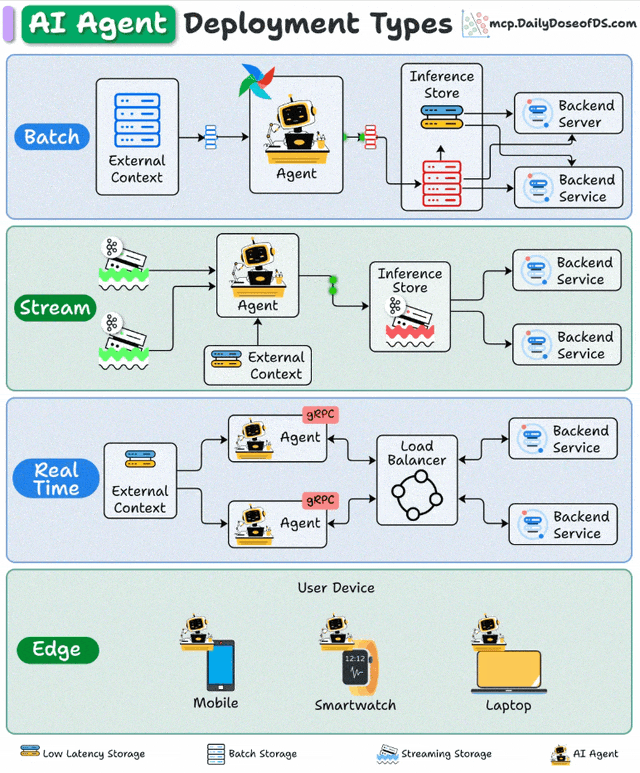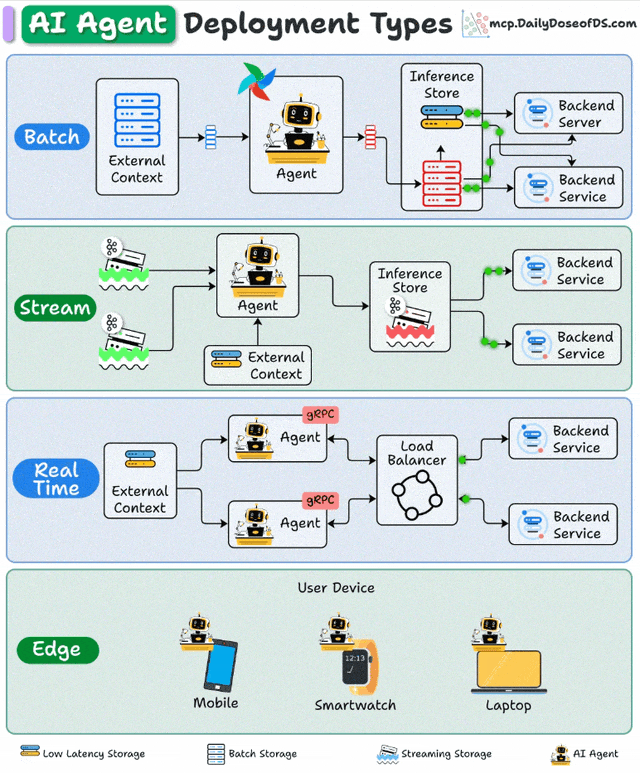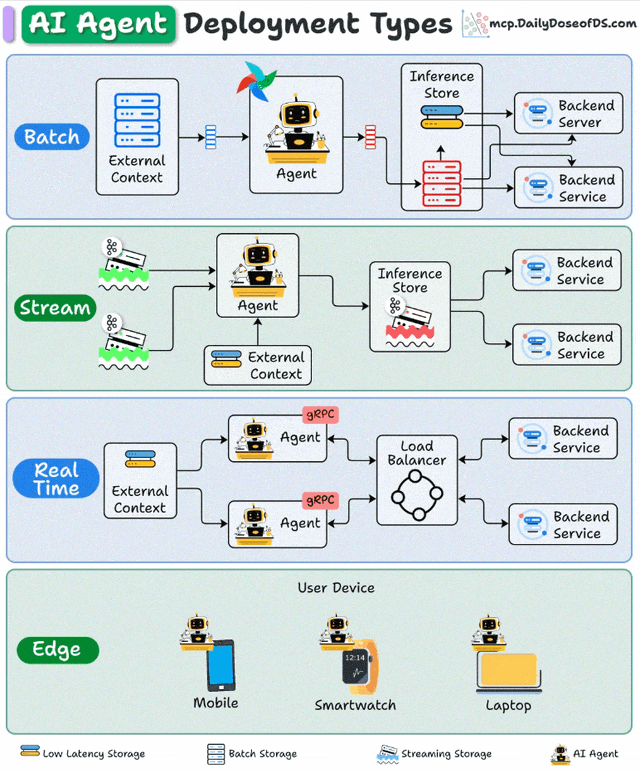
1️⃣ Batch deployment
You can think of this as a scheduled automation.
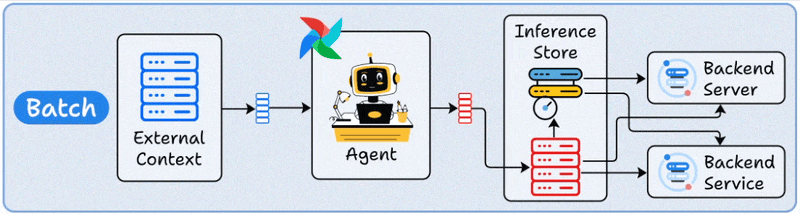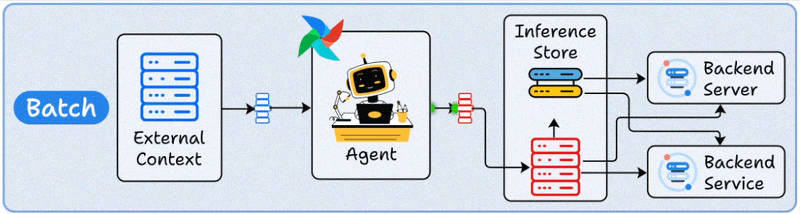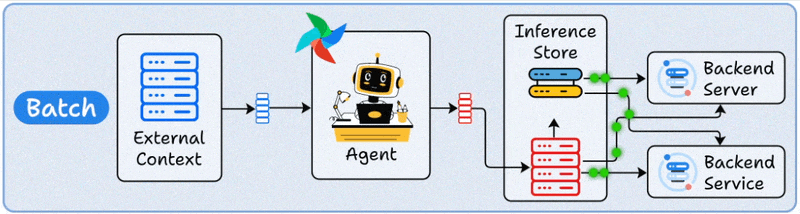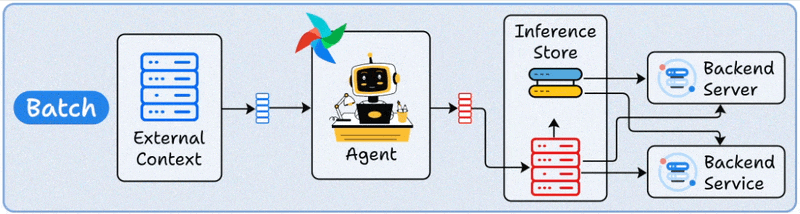
The Agent runs periodically, like a scheduled CLI job.
Just like any other Agent, it can connect to external context (databases, APIs, or tools), process data in bulk, and store results.
This typically optimizes for throughput over latency.
This is best for processing large volumes of data that don’t need immediate responses.
2️⃣ Stream deployment
Here, the Agent becomes part of a streaming data pipeline.
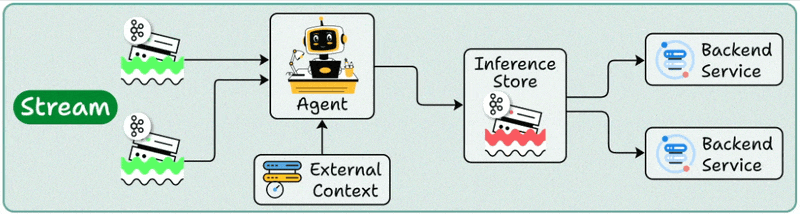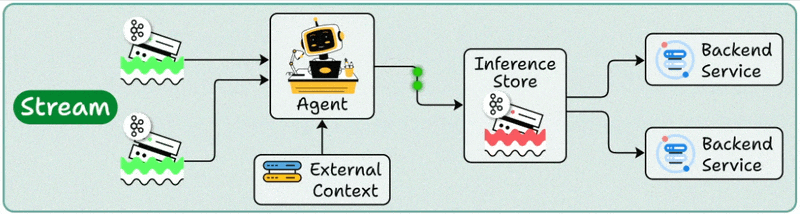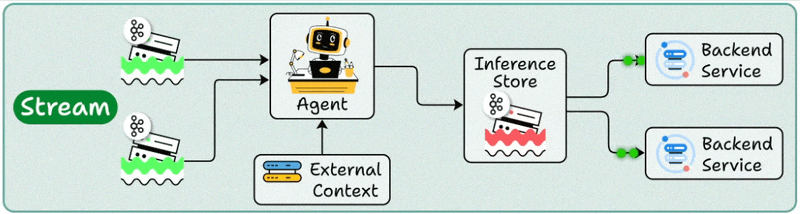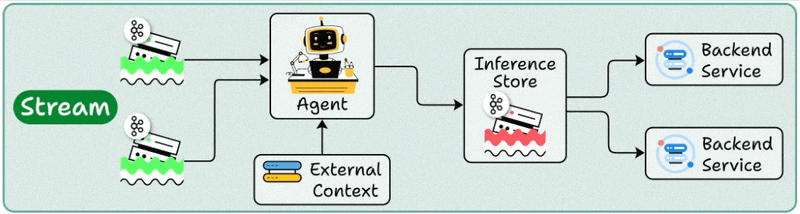
It continuously processes data as it flows through systems.
Your agent stays active, handling concurrent streams while accessing both streaming storage and backend services as needed.
Multiple downstream applications can then make use of these processed outputs.
Best for: Continuous data processing and real-time monitoring
3️⃣ Real-Time deployment
This is where Agents act like live backend services.
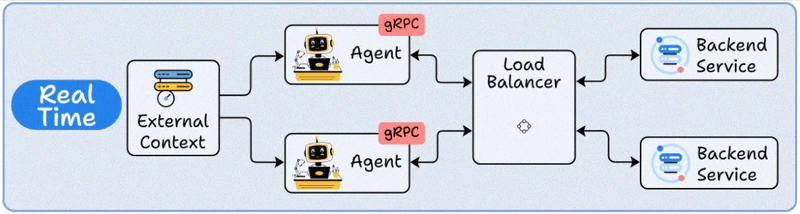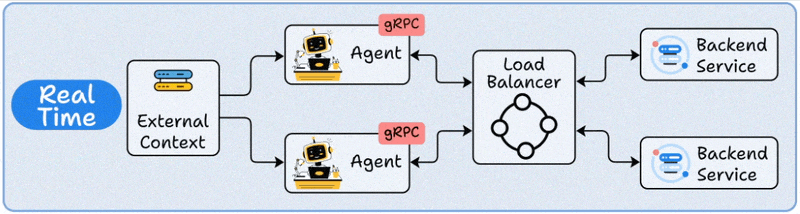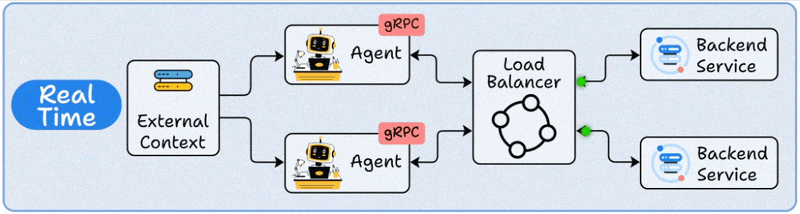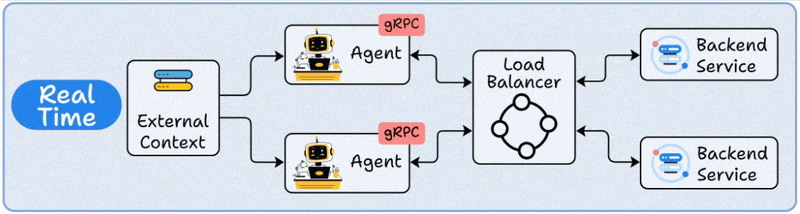
The Agent runs behind an API (REST or gRPC).
When a request arrives, it retrieves any needed context, reasons using the LLM, and responds instantly.
Load balancers ensure scalability across multiple concurrent requests.
This is your go-to for chatbots, virtual assistants, and any application where users expect sub-second responses.
4️⃣ Edge deployment
The agent runs directly on user devices: mobile phones, smartwatches, and laptops so no server round-trip is needed.
The reasoning logic lives inside your mobile, smartwatch, or laptop.
Sensitive data never leaves the device, improving privacy and security.
Useful for tasks that need to work offline or maintain user confidentiality.
Best for: Privacy-first applications and offline functionality
To summarize:
Batch = Maximum throughput
Stream = Continuous processing
Real-Time = Instant interaction
Edge = Privacy + offline capability
Each pattern serves different needs. The key is matching your deployment strategy to your specific use case, performance requirements, and user expectations.
We will cover these in more detail in the ongoing MLOps/LLMOps crash course. In the meantime, here’s what we have covered so far in 11 parts:
Part 3 covered reproducibility and versioning for ML systems →
Part 4 also covered reproducibility and versioning for ML systems →
Part 7 covered Spark, and orchestration + workflow management →
Part 8 covered the modeling phase of the MLOps lifecycle from a system perspective →
Part 9 covered fine-tuning and model compression/optimization →
Part 10 expanded on the model compression discussed in Part 9 →
Part 11 covered the deployment phase of the MLOps lifecycle →
👉 Over to you: What deployment pattern are you using for your AI agents? Or are you combining multiple approaches?
Thanks for reading!