
All-Reduce and Ring-Reduce for Model Synchronization in Multi-GPU Training
Two synchronization algorithms for intermediate-ML models.
One of the biggest run-time bottlenecks of multi-GPU training is observed during model synchronization:
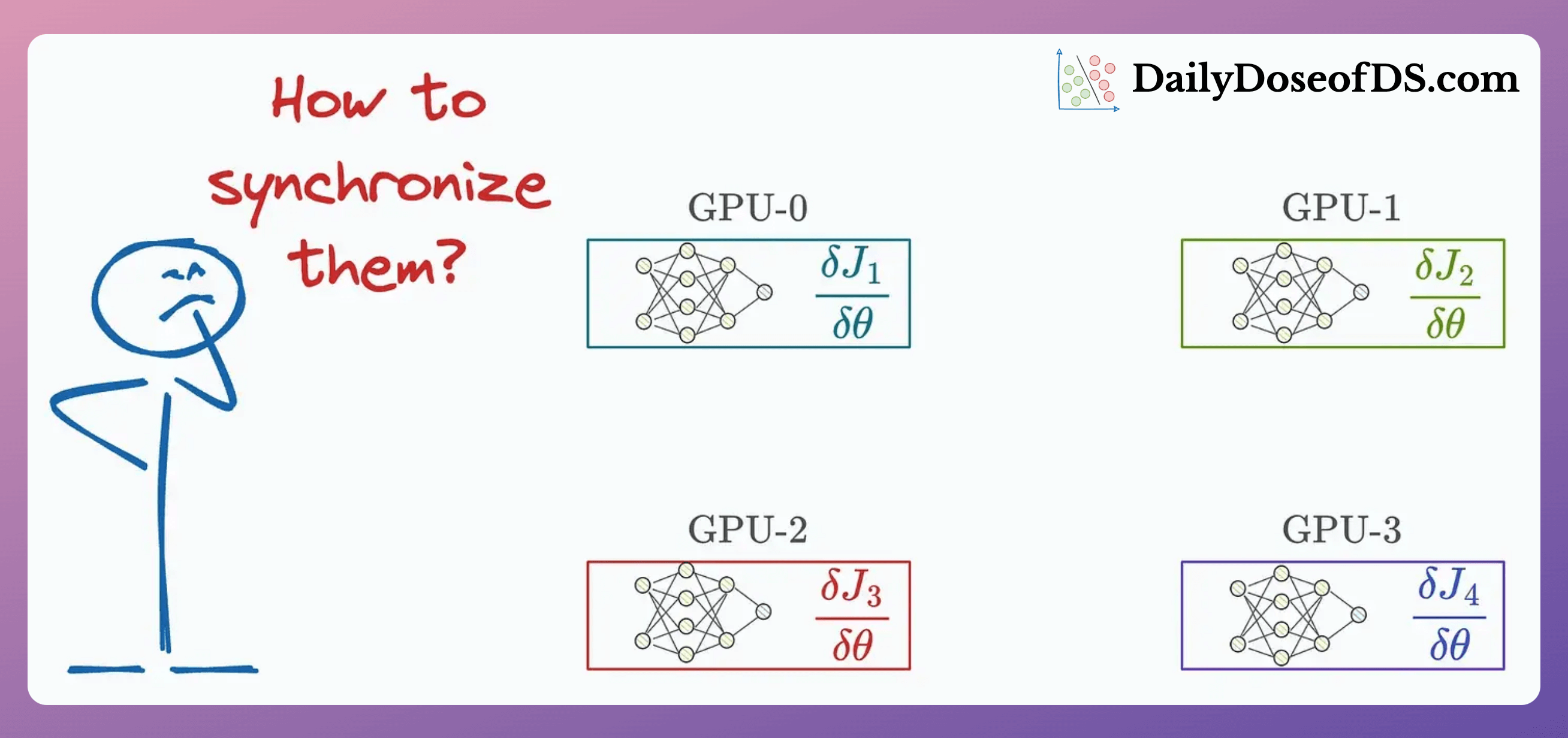
In today’s issue, let’s understand two common strategies to optimize this for intermediate-sized models.
If you want to get into the implementation-related details of multi-GPU training, we covered it here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s begin!
Consider data parallelism, which:
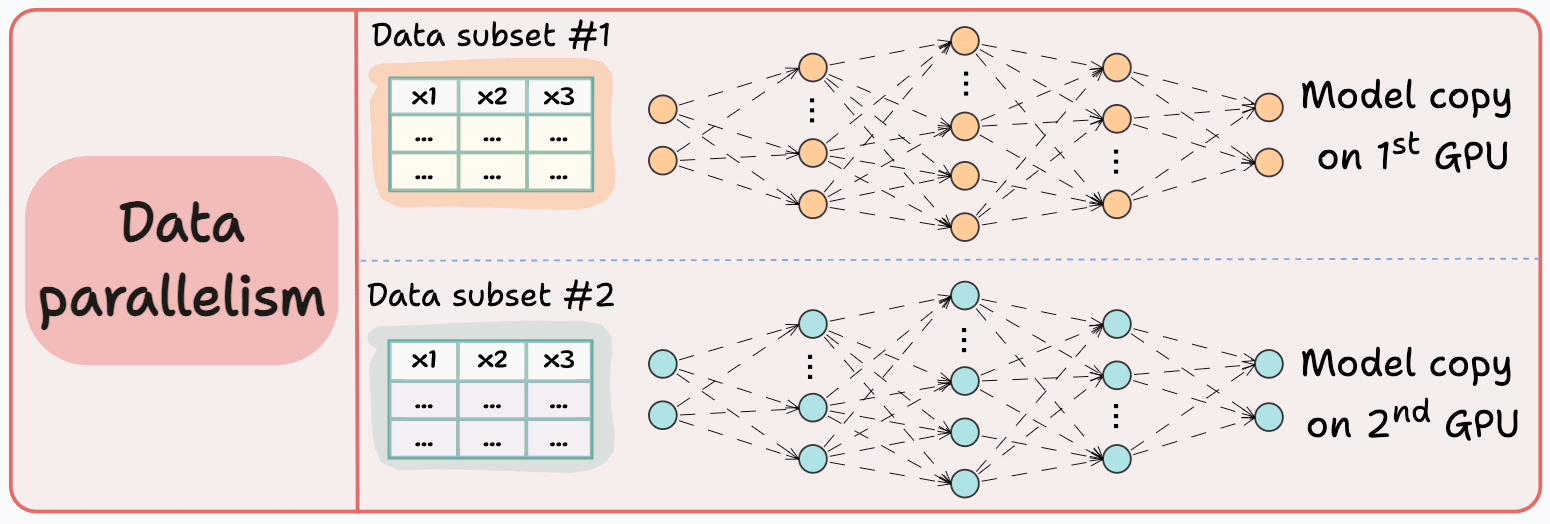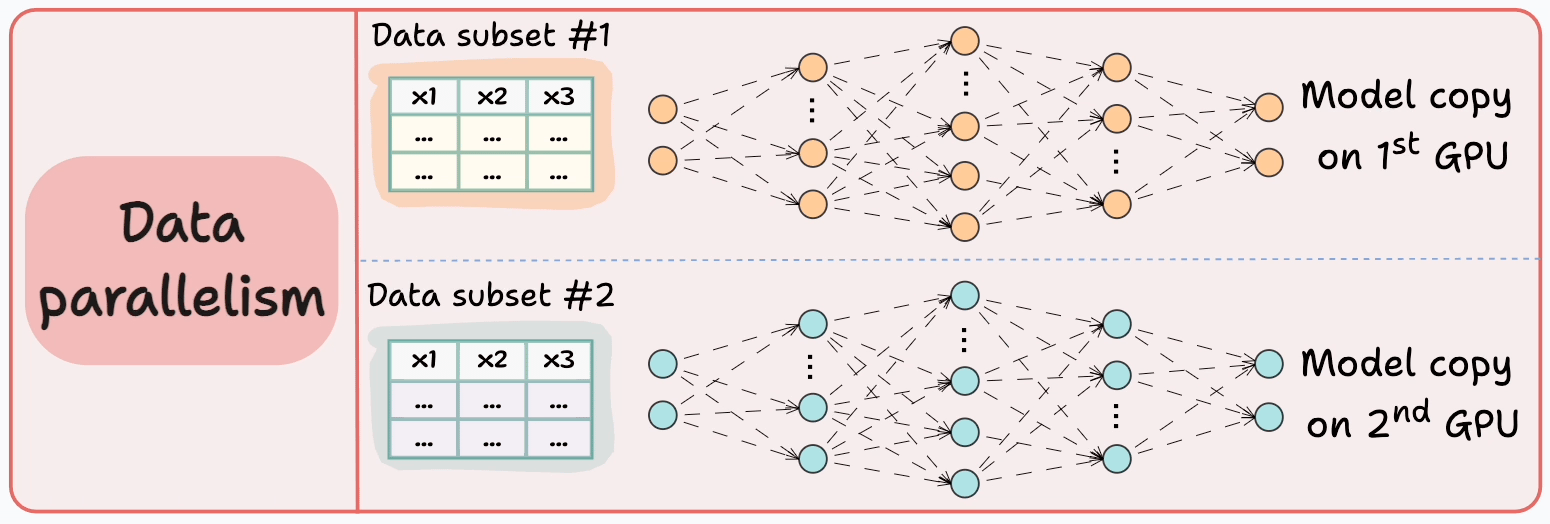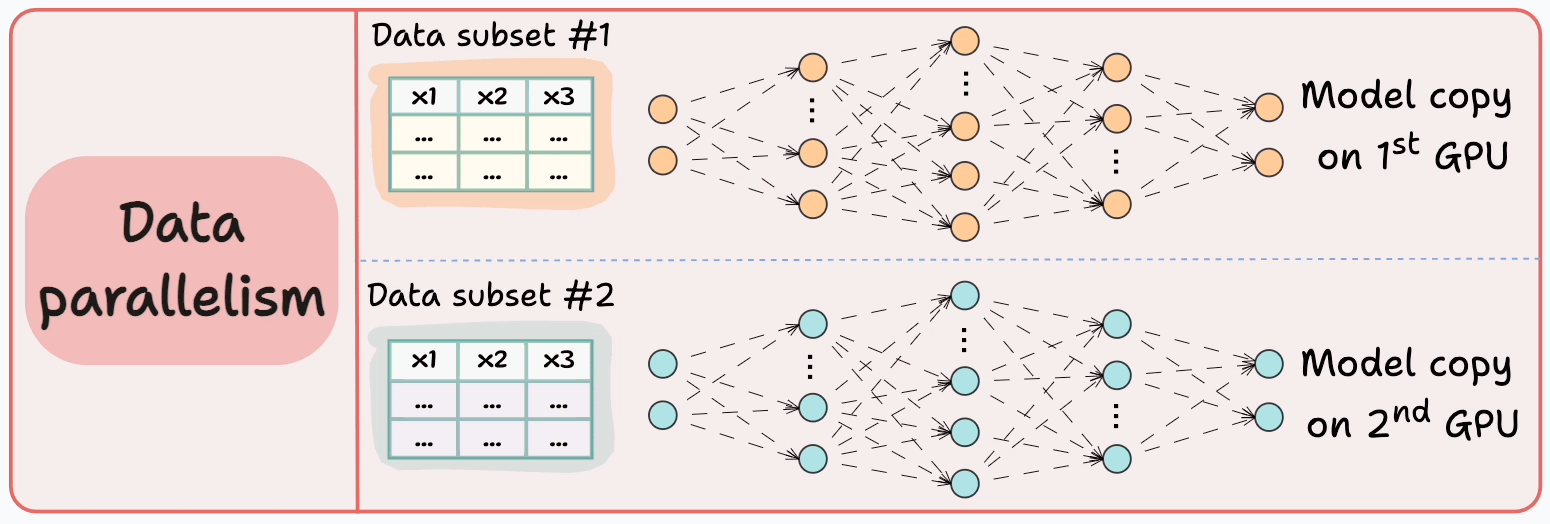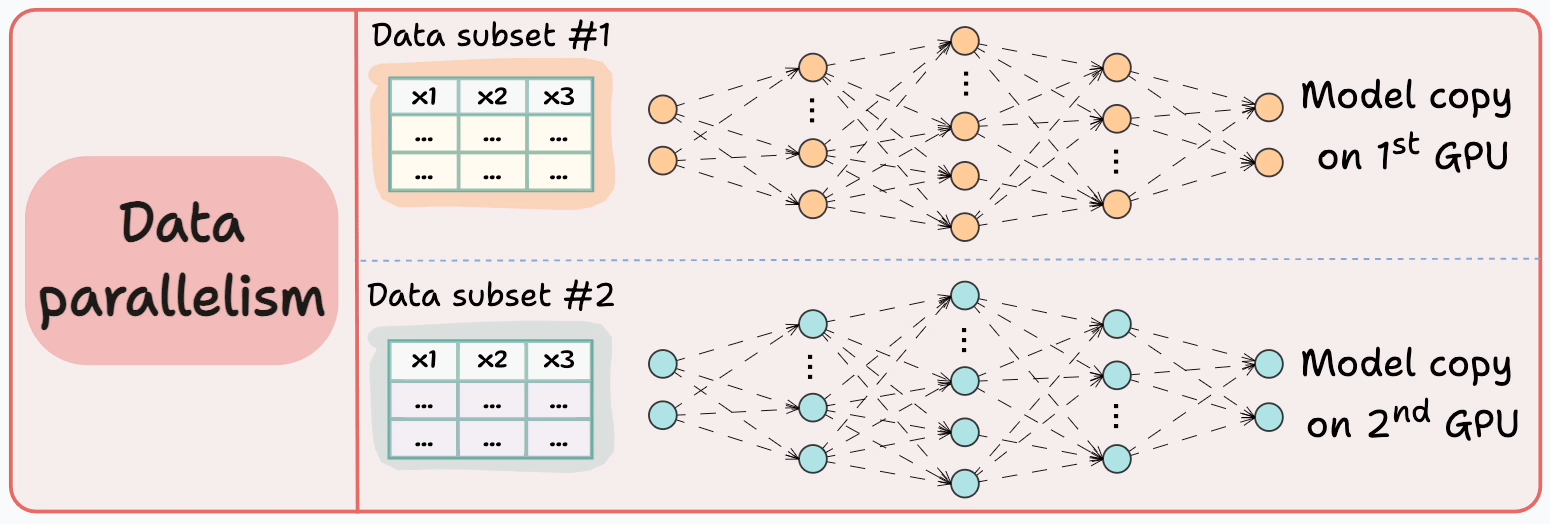
Replicates the model across all GPUs.
Divides the available data into smaller batches, and each batch is processed by a separate GPU.
Computes the gradients on each GPU and then communicates them to every other GPU.
In other words, since every GPU processes a different chunk of the dataset, the gradients will also be different across devices:

Thus, before updating the model parameters on each GPU device, we must communicate these gradients to all other devices.
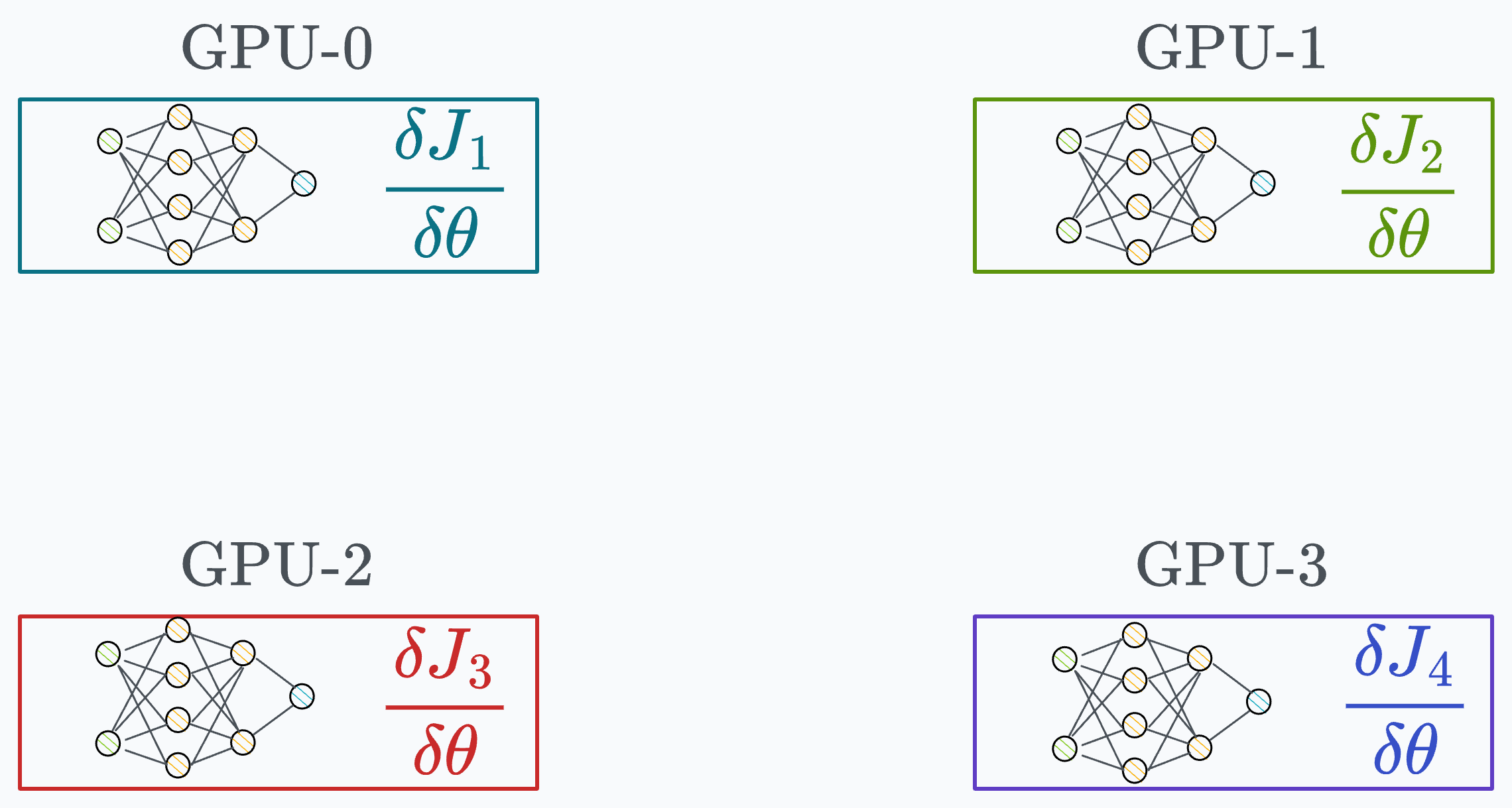
So, how can we communicate these gradients?
Algorithm #1) All-reduce
One of the most obvious ways is to send the gradients from one GPU device to all other GPU devices and then average them on every device:

This way, we can synchronize the weight across all devices:
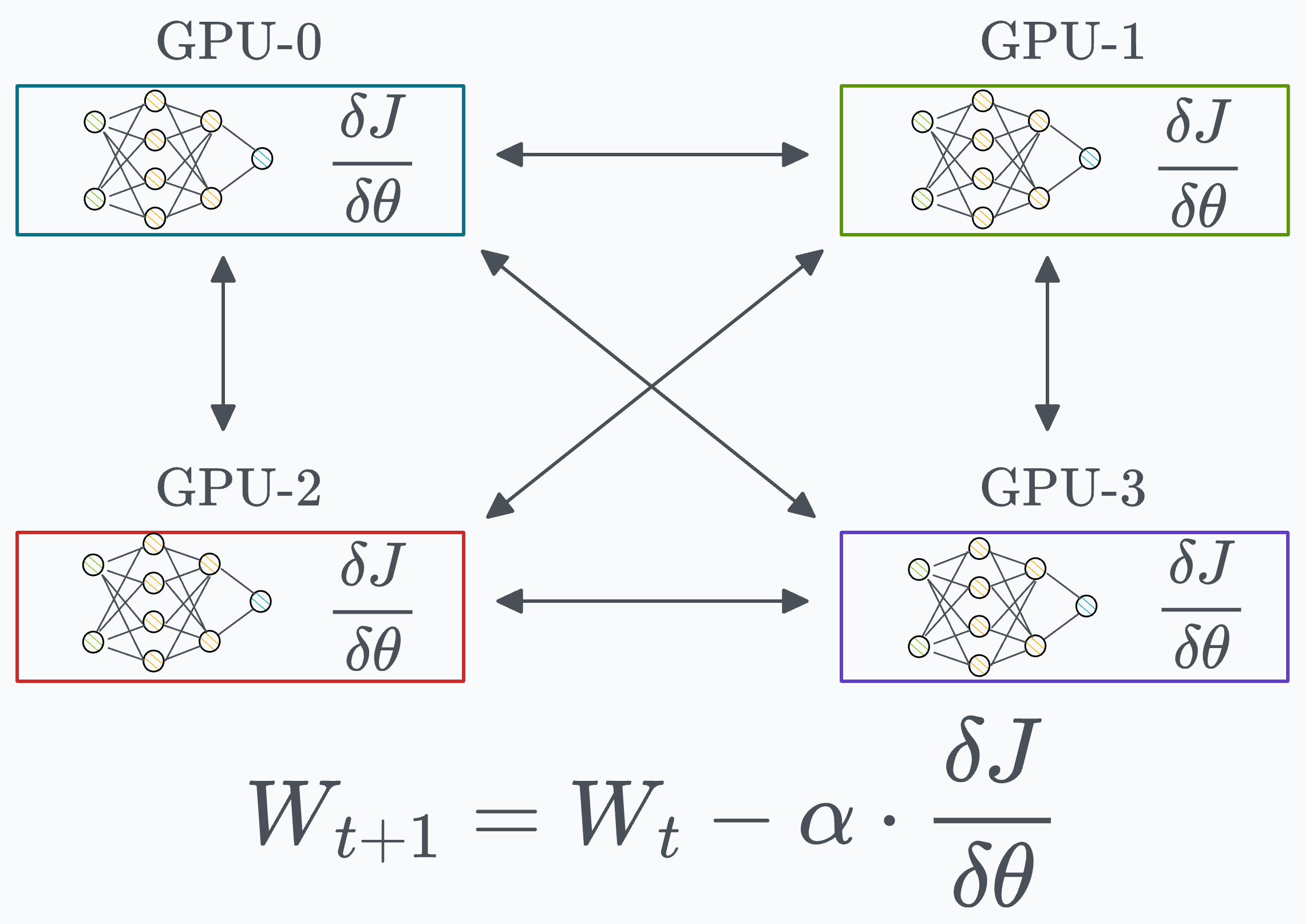
However, this approach is not ideal as it utilizes too much bandwidth.
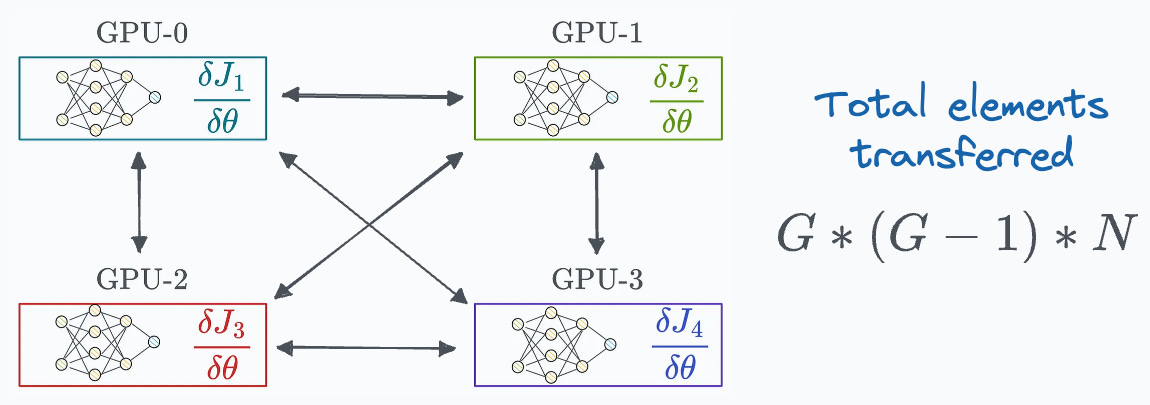
To estimate the number of gradient values transferred, consider that every GPU has a single matrix with “N” elements:
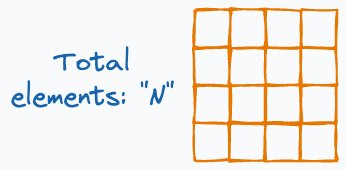
Since every GPU transfers “N” elements to every other GPU, this results in a total transfer of (assuming “G” is the total number of GPUs):
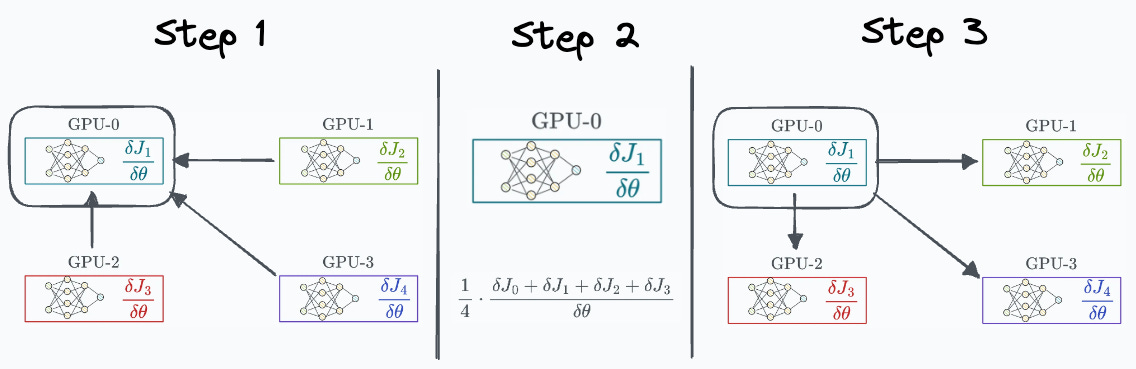
One way to optimize this is by transferring all the elements to one GPU, computing the average, and communicating the average back to all other GPUs:
The number of elements transferred is:
Step 1:
(G-1)GPUs transfer “N” elements to the 1st GPU.Step 3: 1st GPU transfers “N” elements to
(G-1)GPUs.
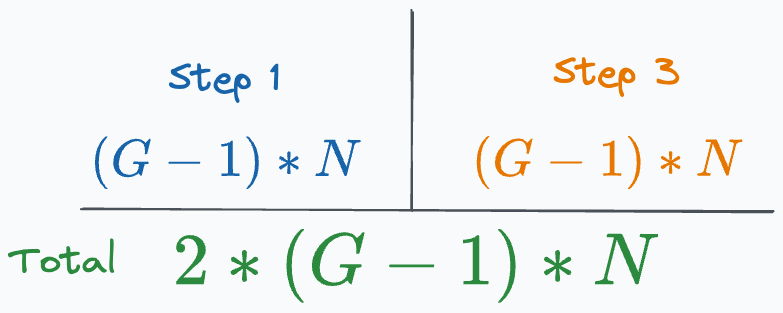
In this case, the total transfers are significantly lower than we had earlier. But we run into a major issue:
Since a single GPU is responsible for receiving, computing, and communicating back the gradients, it does not scale pretty well.
Can we do better?
Algorithm #2) Ring All-reduce (or Ring-reduce)
As the name suggests, it has something to do with a ring formation. There are two phases:
Share-reduce
Share-only
Here’s how each of them works.
Phase #1) Share-reduce
Gradients are divided into G segment on every GPU (G = total number of GPUs):

Every GPU communicates a segment to the next GPU in a ring fashion, as demonstrated below:

GPU-0 sends a₁ to GPU-1, where it gets added to b₁.
GPU-1 sends b₂ to GPU-2, where it gets added to c₂.
GPU-2 sends c₃ to GPU-3, where it gets added to d₃.
GPU-3 sends d₄ to GPU-0, where it gets added to a₄.
Before the start of the next iteration, the state of every GPU looks like this:

In the next iteration, a similar process is carried out again:
GPU-0 sends (d₄+a₄) to GPU-1, where it gets added to b₄.
GPU-1 sends (a₁+b₁) to GPU-2, where it gets added to c₁.
GPU-2 sends (b₂+c₂) to GPU-3, where it gets added to d₂.
GPU-3 sends (c₃+d₃) to GPU-0, where it gets added to a₃.
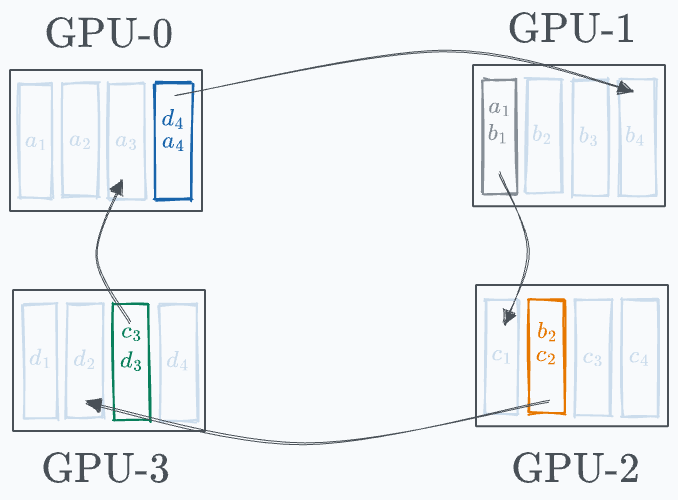
Before the start of the next iteration, the state of every GPU looks like this:

In the final iteration, the following segments are transferred to the next GPU:

Done!
This leads to the following state on every GPU:
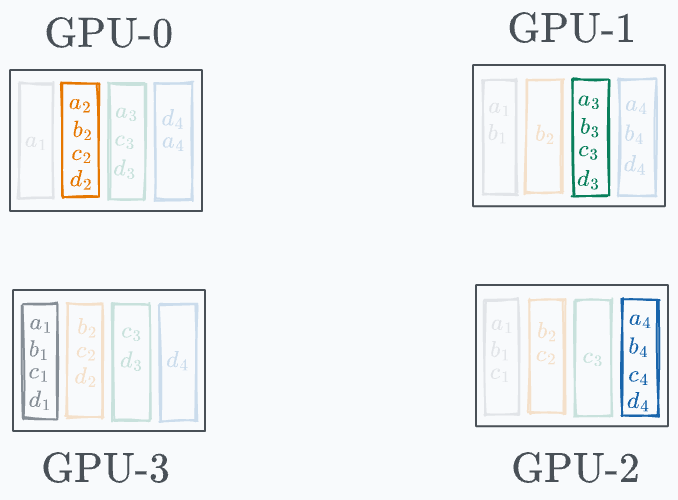
As the above diagram shows, every GPU has one entire segment.
Now, our objective is to transfer these complete segments to all other GPUs, which takes us to the next phase.
Phase #2) Share-only
The process is similar to what we discussed above, so we won’t go into full detail.
Iteration 1 is shown below:
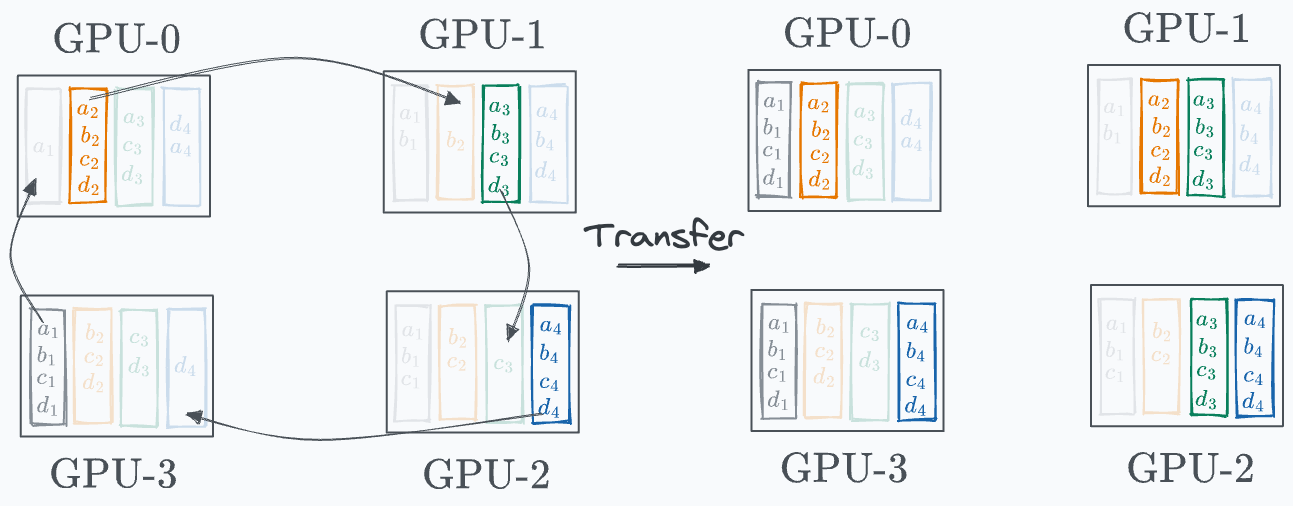
Iteration 2 is shown below:

Finally, iteration 3 is shown below:
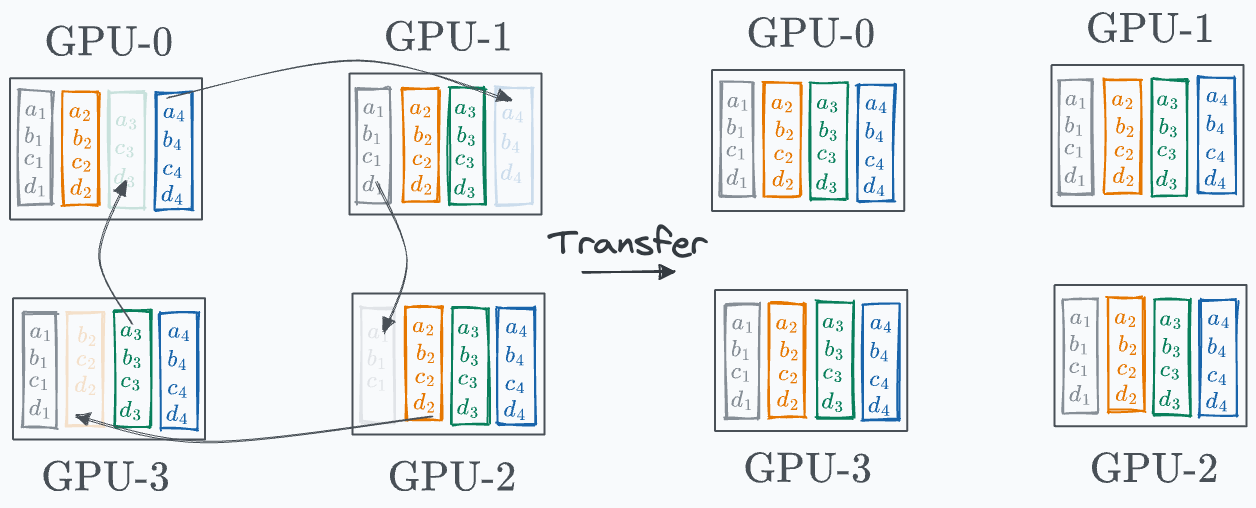
And there you go!
Model weights across GPUs have been synchronized:

Of course, if you notice closely, the number of elements transferred is still the same as we had in the “single-GPU-master” approach.
However, this approach is much more scalable since it does not put the entire load on one GPU for communication.
That’s a clever technique, isn’t it?
If you want to get into the implementation-related details of multi-GPU training, we covered it here: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, methods like ring-reduce are only suitable for small and intermediate models.
We discussed many more advanced methods for large models here: A Practical Guide to Scaling ML Model Training.
👉 Over to you: Can you optimize ring-reduce even further?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Would it be wise to first allow each GPU to train its own version of the model independently on it's given data sunset and cross validate using the rest of the data set?
I'm thinking this would be a sanity check of sorts to see if the chosen model is worth further training.