
An Algorithmic Deep Dive into HDBSCAN
The supercharged version of DBSCAN.

Some days back, I briefly discussed the difference between DBSCAN and HDBSCAN in this newsletter.
In the poll, most responders showed interest in a deep dive into HDBSCAN.

So this is what we are discussing in the most recent deep dive: HDBSCAN: The Supercharged Version of DBSCAN — An Algorithmic Deep Dive.

Why care?
Although DBSCAN is typically more robust than KMeans on real-world datasets, the biggest limitation is that it assumes the local density of data points is (somewhat) globally uniform. This is governed by its eps parameter.
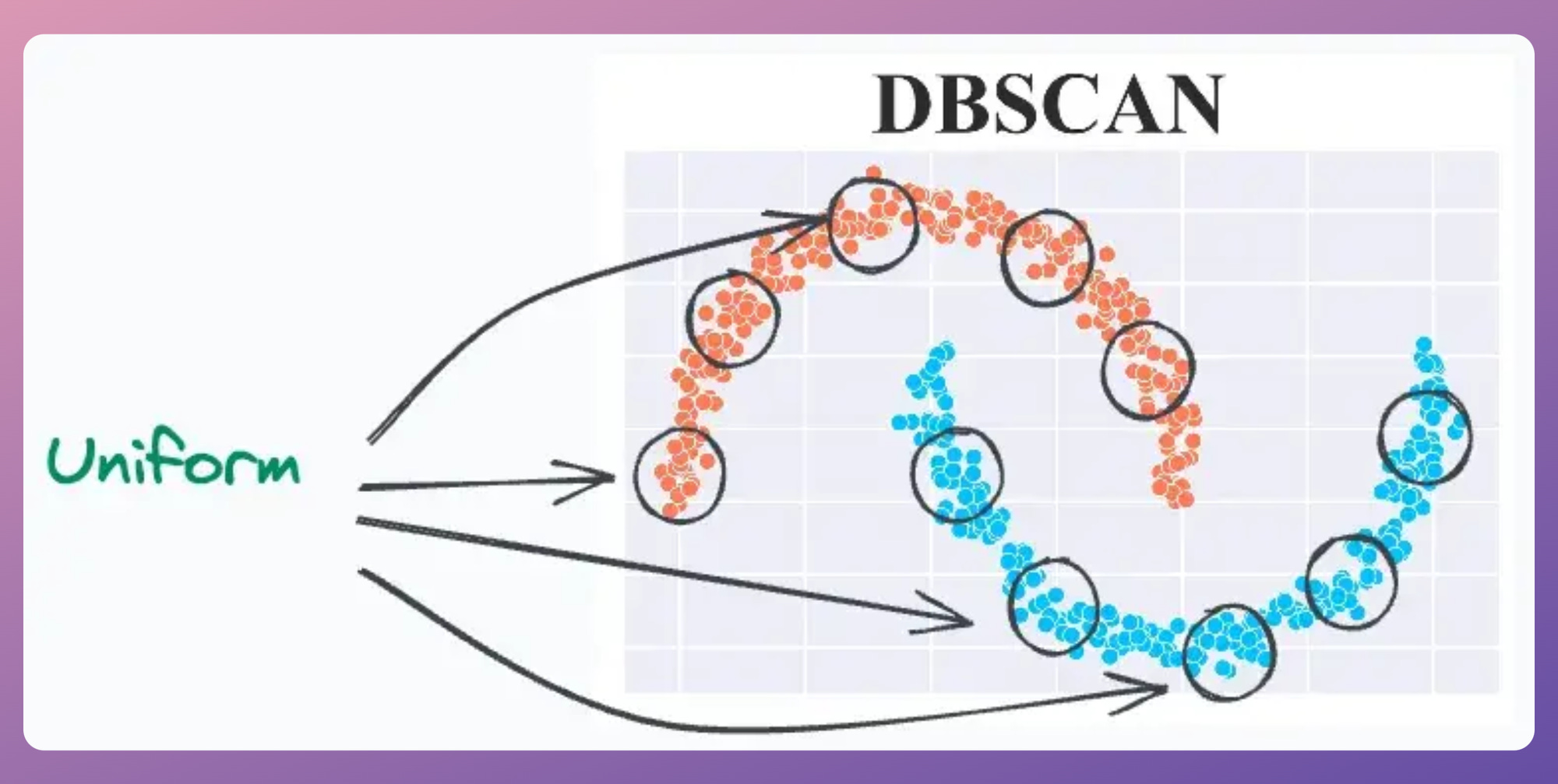
The problem is that validating this assumption to know if we can trust DBSCAN’s output is quite difficult because, at times, we hardly know anything about the data.
In fact, one core reason for using a clustering algorithm in the first place is to discover patterns in the data and explore them before potentially modeling it in some way.
However, an “assumption-driven clustering” creates a paradox because the clustering algorithm is helping us understand the data, but it also requires us to understand the data to trust its results.
This tells us that we need a clustering algorithm that sets as few expectations about the dataset as possible to get useful insights from it.
HDBSCAN is one of them.
We cover the technical aspects of HDBSCAN and understand what makes it so powerful.
For instance, consider the clustering results obtained with DBSCAN on the dummy dataset below, where each cluster has different densities:

It is clear that DBSCAN produces bad clustering results.
Now compare it with HDBSCAN results depicted below:
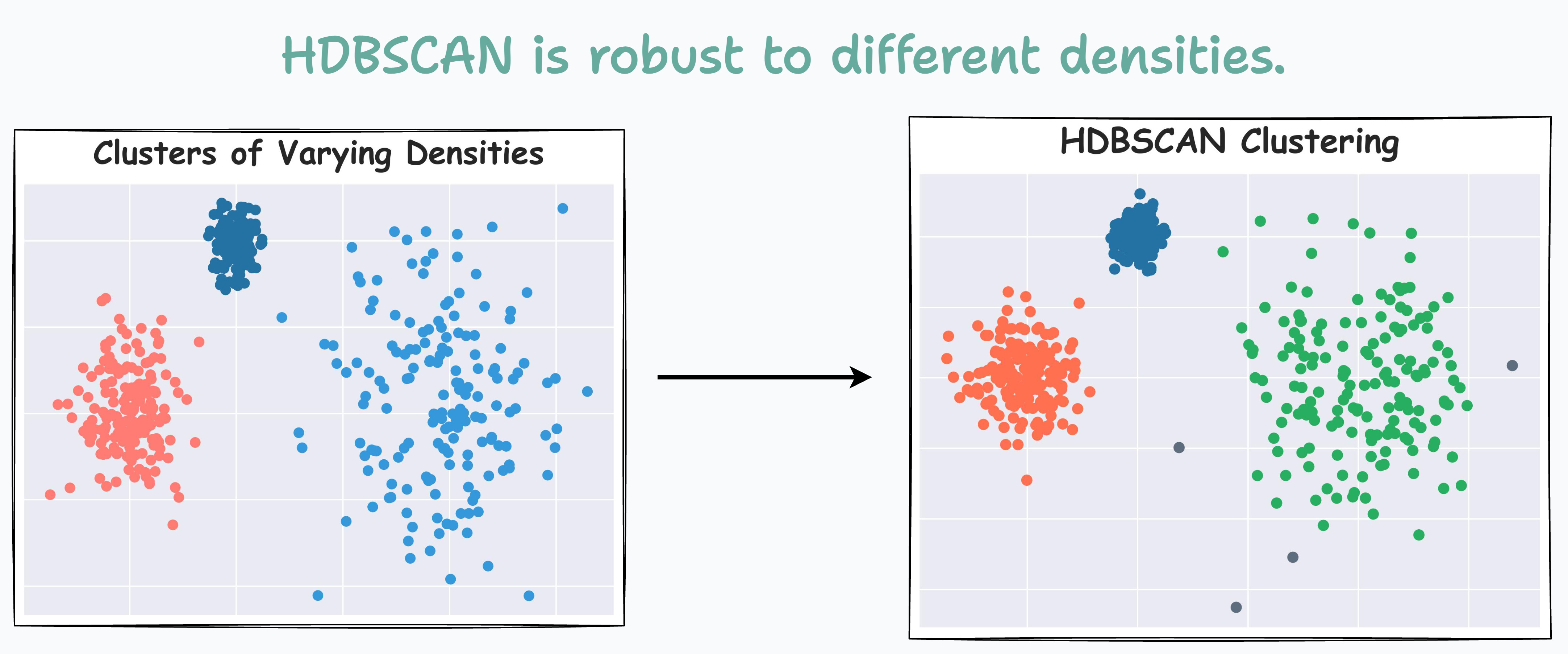
On a dataset with three clusters, each with varying densities, HDBSCAN is found to be more robust.
Read it here: HDBSCAN: The Supercharged Version of DBSCAN — An Algorithmic Deep Dive.
Have a good day!
Avi