
An Animated Guide to Bagging and Boosting in Machine Learning
A step-by-step explanation.

Many folks often struggle to understand the core essence of bagging and boosting.
I prepared this animation, which depicts what goes under the hood:
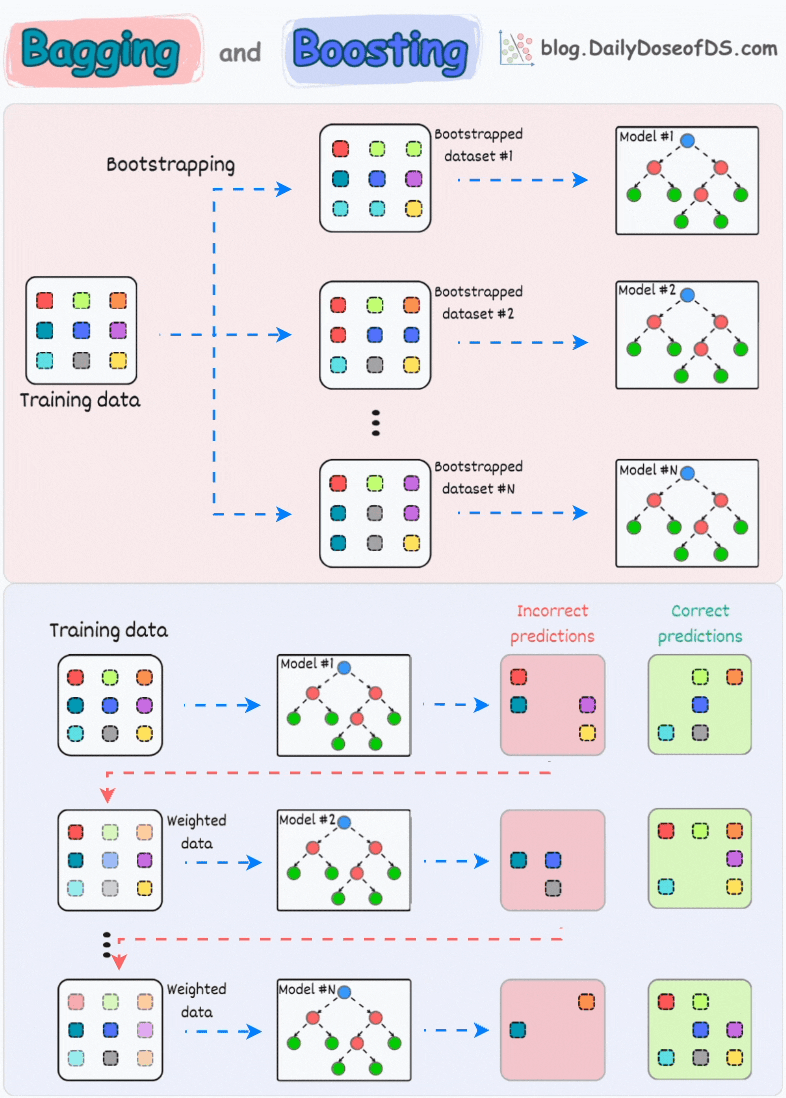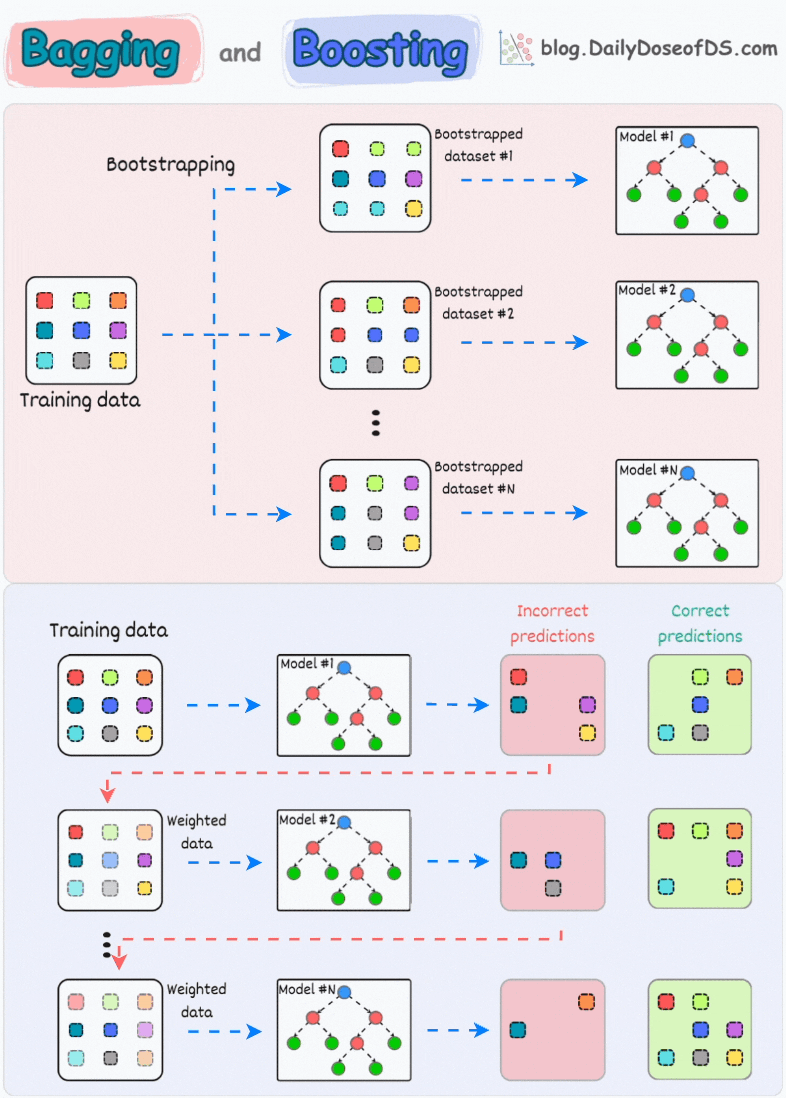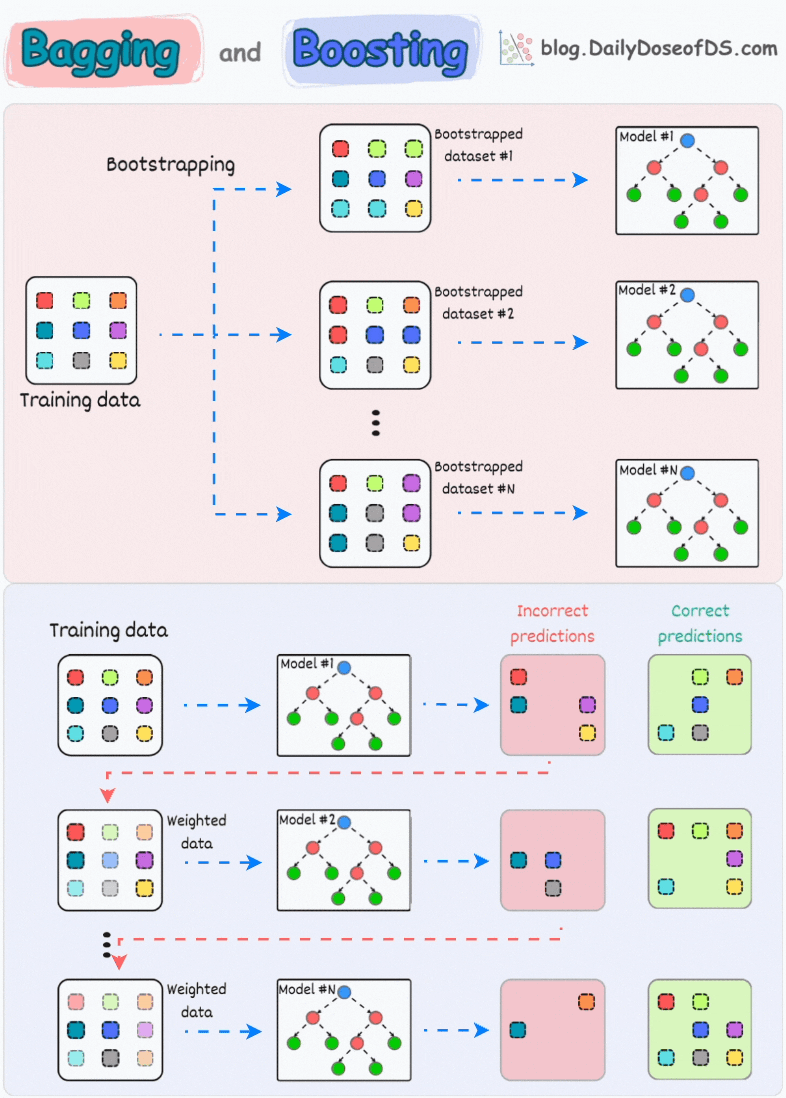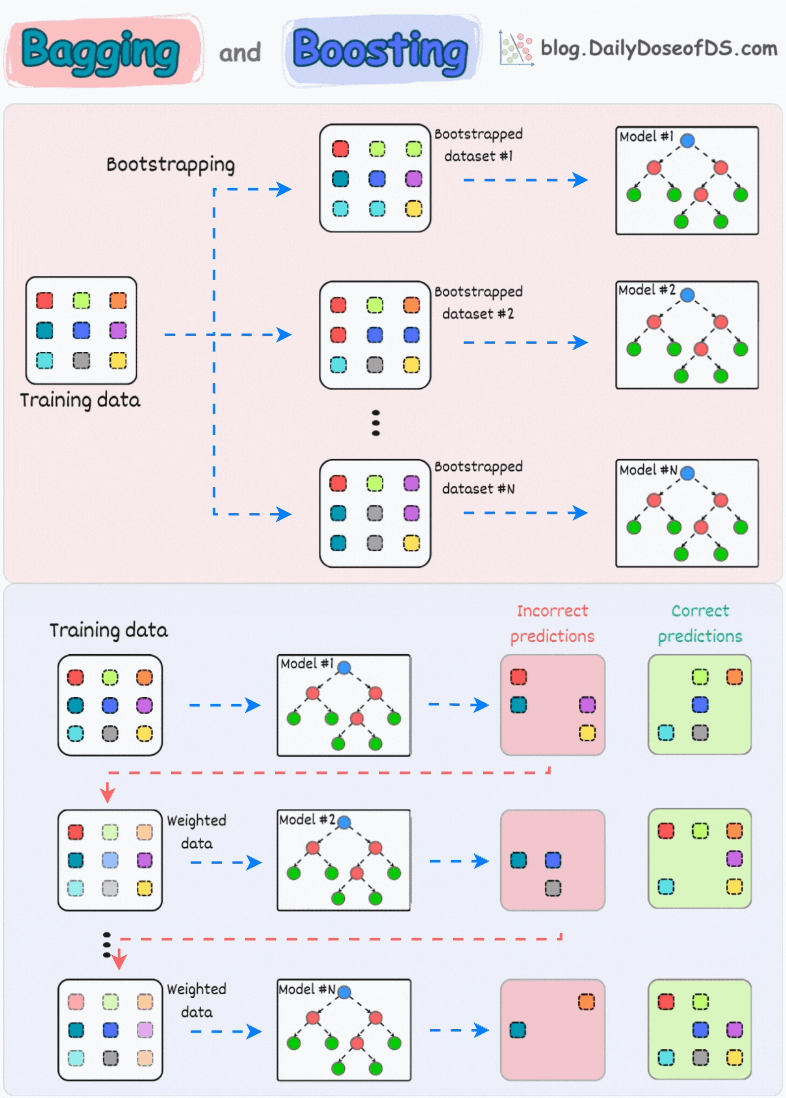
In a gist, an ensemble combines multiple models to build a more powerful model.
They are fundamentally built on the idea that by aggregating the predictions of multiple models, the weaknesses of individual models can be mitigated.
Whenever I wish to intuitively illustrate their immense power, I use the following image:

Ensembles are primarily built using two different strategies:
Bagging
Boosting
1) Bagging (short for Bootstrapped Aggregation):
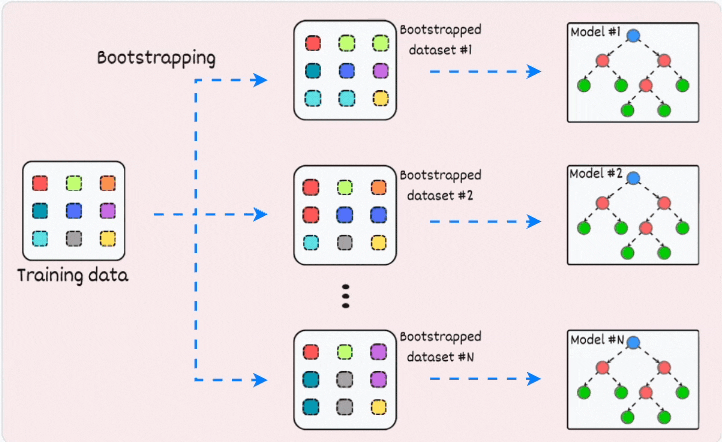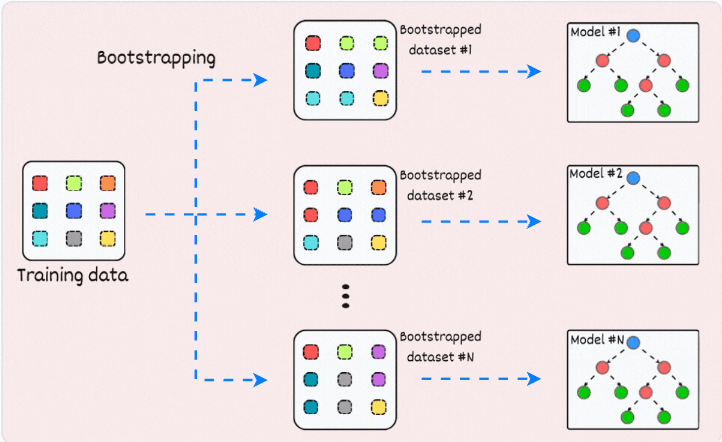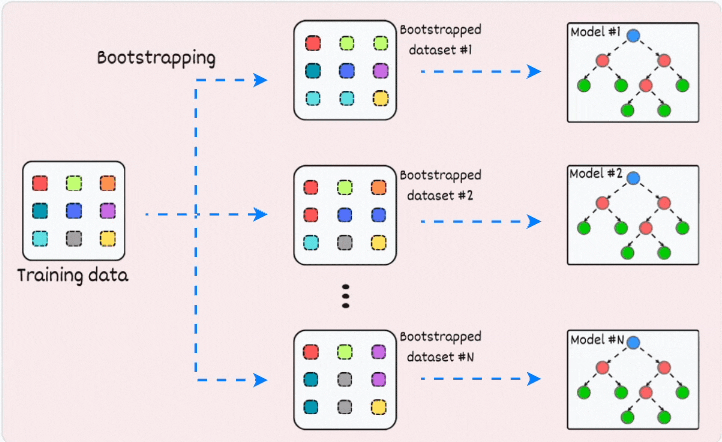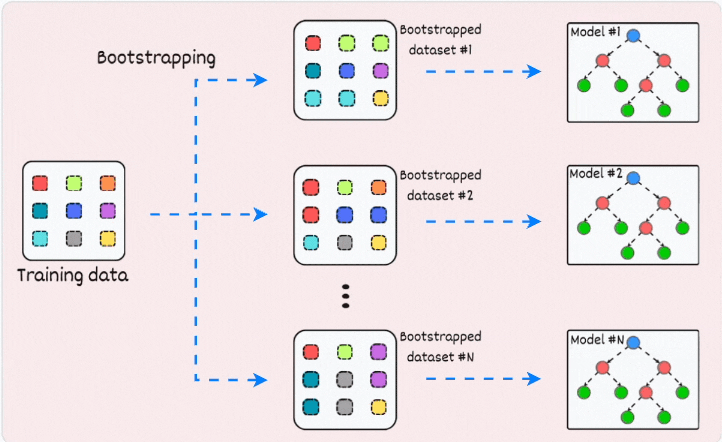
creates different subsets of data with replacement (this is called bootstrapping)
Why “with replacement and why bagging is extremely effective?”
I have a full article on this if you are interested in learning more: Why Bagging is So Ridiculously Effective At Variance Reduction?
trains one model per subset
aggregates all predictions to get the final prediction
Some common models that leverage bagging are:
Random Forests
Extra Trees
2) Boosting:
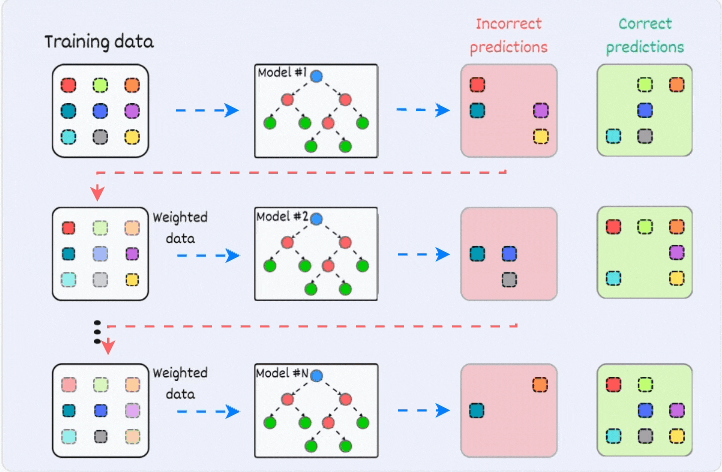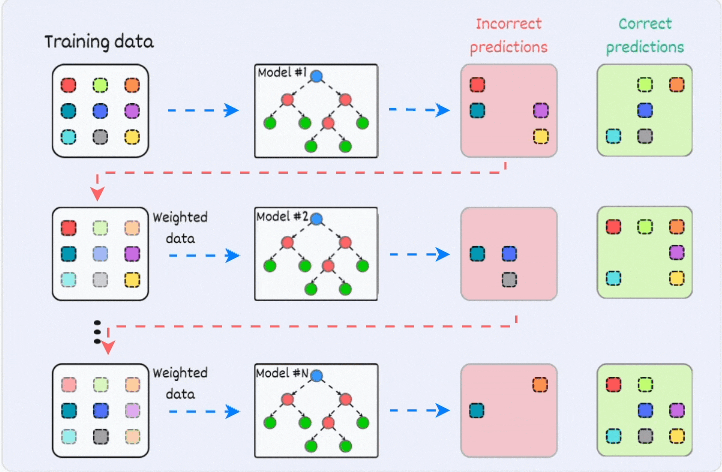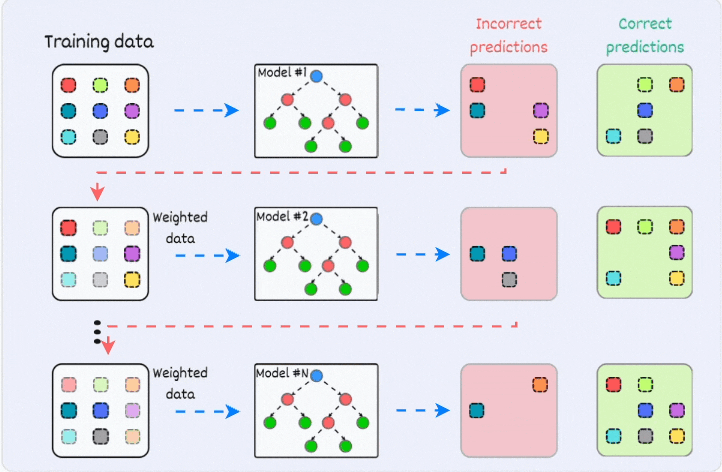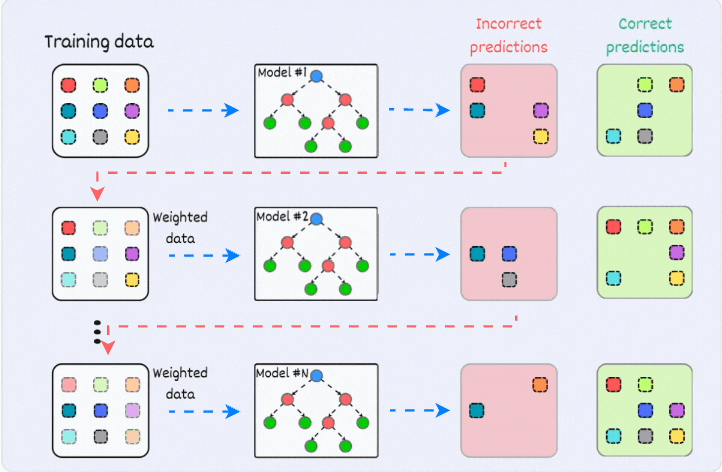
is an iterative training process
the subsequent model puts more focus on misclassified samples from the previous model
the final prediction is a weighted combination of all predictions
Some common models that leverage boosting are:
XGBoost,
AdaBoost, etc.
Overall, ensemble models significantly boost the predictive performance compared to using a single model.
They tend to be more robust, generalize better to unseen data, and are less prone to overfitting.
👉 Over to you: What are some challenges/limitations of using ensembles? Let’s discuss it today :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Formulating and Implementing the t-SNE Algorithm From Scratch.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Thanks for writing this
What tools are you using to create the animations?