
An Intuitive and Visual Demonstration of Momentum in Machine Learning
Speedup machine learning model training with little effort.

As we progress towards building larger and larger models, every bit of possible optimization becomes crucial.

And, of course, there are various ways to speed up model training, like:
Batch processing
Leverage distributed training using frameworks like PySpark MLLib.
Use better Hyperparameter Optimization, like Bayesian Optimization, which we discussed here: Bayesian Optimization for Hyperparameter Tuning.
and many other techniques.
Momentum is another reliable and effective technique to speed up model training.
While Momentum is pretty popular, many people struggle to intuitively understand how it works and why it is effective.
Let’s understand this today!
Issues with Gradient Descent
In gradient descent, every parameter update solely depends on the current gradient.
This is clear from the gradient weight update rule shown below:

As a result, we end up having many unwanted oscillations during the optimization process.
Let’s understand this more visually.
Imagine this is the loss function contour plot, and the optimal location (parameter configuration where the loss function is minimum) is marked here:

Simply put, this plot illustrates how gradient descent moves towards the optimal solution. At each iteration, the algorithm calculates the gradient of the loss function at the current parameter values and updates the weights.
This is depicted below:
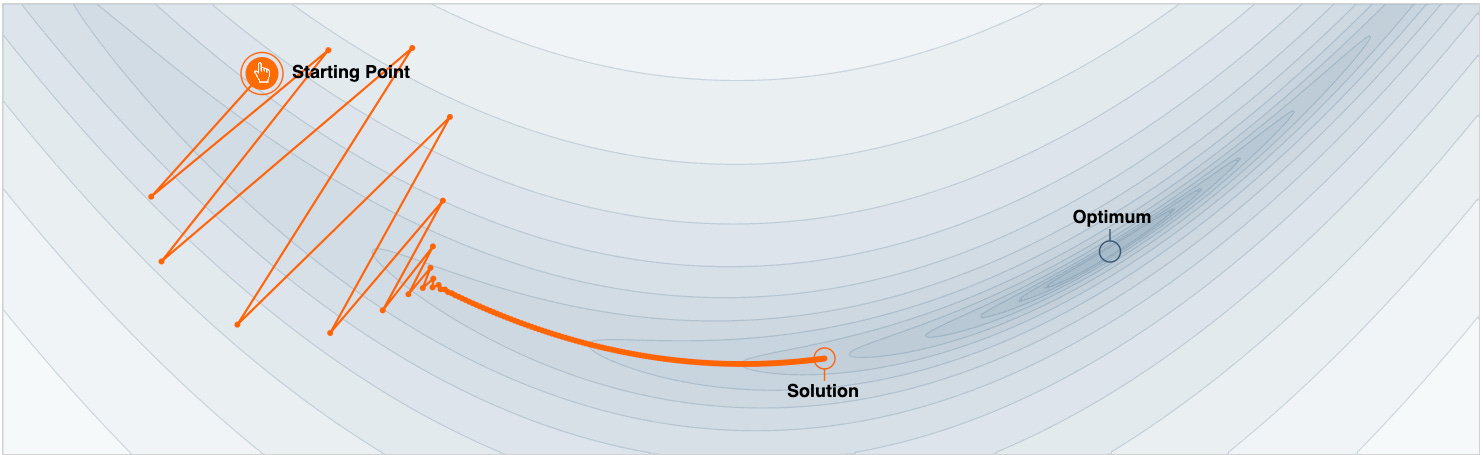
Notice two things here:
It unnecessarily oscillates vertically.
It ends up at the non-optimal solution after some epochs.
Ideally, we would have expected our weight updates to look this:
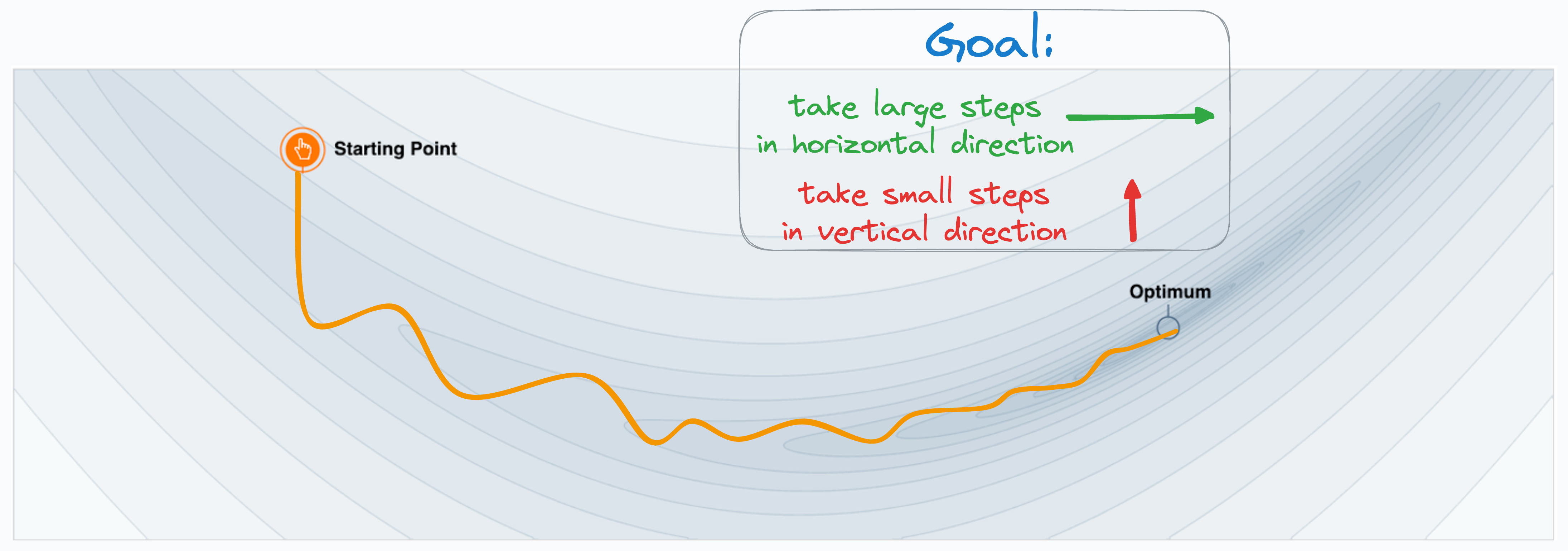
It must have taken longer steps in the horizontal direction…
…and smaller vertical steps because a movement in this direction is unnecessary.
This idea is also depicted below:
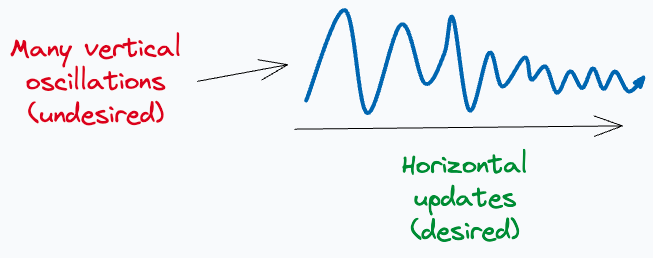
How Momentum solves this problem?
Momentum-based optimization slightly modifies the update rule of gradient descent.
More specifically, it also considers a moving average of past gradients:

This helps us handle the unnecessary vertical oscillations we saw earlier.
How?
As Momentum considers a moving average of past gradients, so if the recent gradient update trajectory looks as shown in the following image, then it is clear that its average in the vertical direction will be very low while that in the horizontal direction will be large (which is precisely what we want):

As this moving average gets added to the gradient updates, it helps the optimization algorithm take larger steps in the desired direction.
This way, we can:
Smoothen the optimization trajectory.
Reduce unnecessary oscillations in parameter updates, which also speeds up training.
This is also evident from the image below:
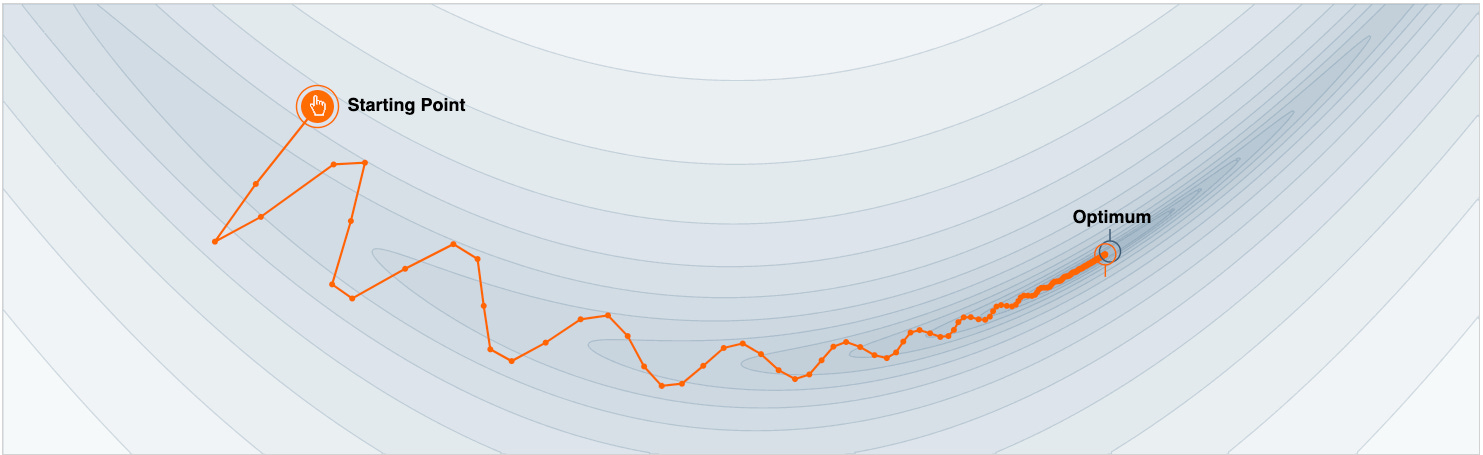
This time, the gradient update trajectory shows much smaller oscillations in the vertical direction, and it also manages to reach an optimum under the same number of epochs as earlier.
This is the core idea behind Momentum and how it works.
Of course, Momentum does introduce another hyperparameter (Momentum rate) in the model, which should be tuned appropriately like any other hyperparameter:

For instance, considering the 2D contours we discussed above:
Setting an extremely large value of Momentum rate will significantly expedite gradient update in the horizontal direction. This may lead to overshooting the minima, as depicted below:

What’s more, setting an extremely small value of Momentum will slow down the optimal gradient update, defeating the whole purpose of Momentum.

If you want to have a more hands-on experience, check out this tool: Momentum Tool.

👉 Over to you: What are some other reliable ways to speed up machine learning model training?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Great
It is a very clear and useful article. Thank you.