
Cython: An Under-appreciated Technique to Speed-up Native Python Programs
...within minimal effort.

Python’s default interpreter — CPython, isn’t smart.
It serves as a standard interpreter for Python and offers no built-in optimization.
This profoundly affects the run-time performance of the program, especially when it’s all native Python code.
Today, I want to tell you about Cython, an optimized compiler, which addresses the limitations of the default interpreter of Python.
CPython and Cython are different. Don’t get confused between the two.
Let’s begin!
In a gist, Cython automatically converts your Python code into C, which is fast and efficient.
Here’s how we use it, say, in a Jupyter Notebook:
First, load the Cython extension (in a separate cell of the notebook):

Where we have native Python code, add the Cython magic command at the top of the cell:

If our code has functions, specify the data type of the parameters as follows:

Define every variable using the “
cdef” keyword and specify its data type.




A sample conversion of a Python function is shown below:

Simple, isn’t it?
Once we do that, Cython will convert our Python code to C, as depicted below:
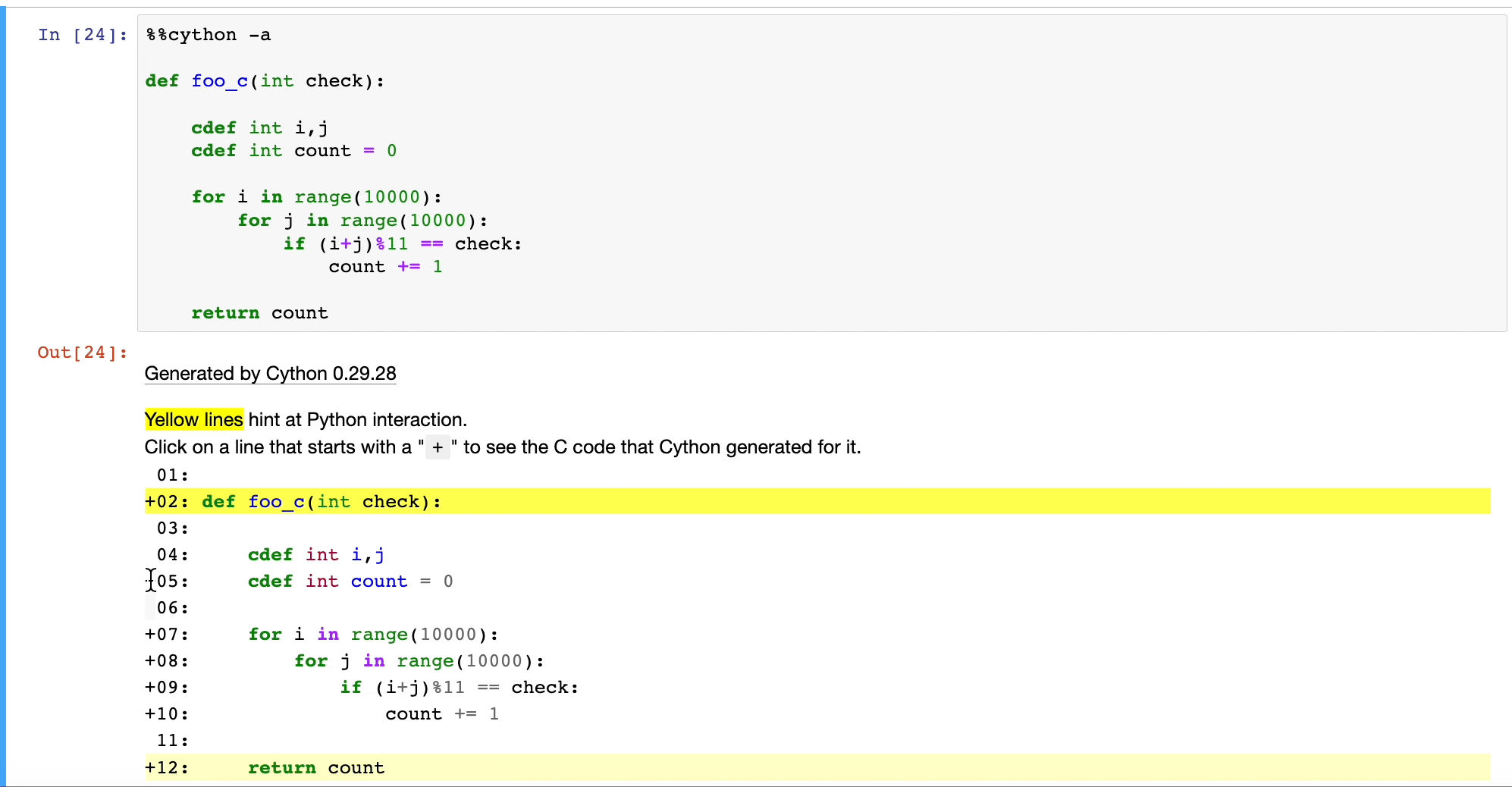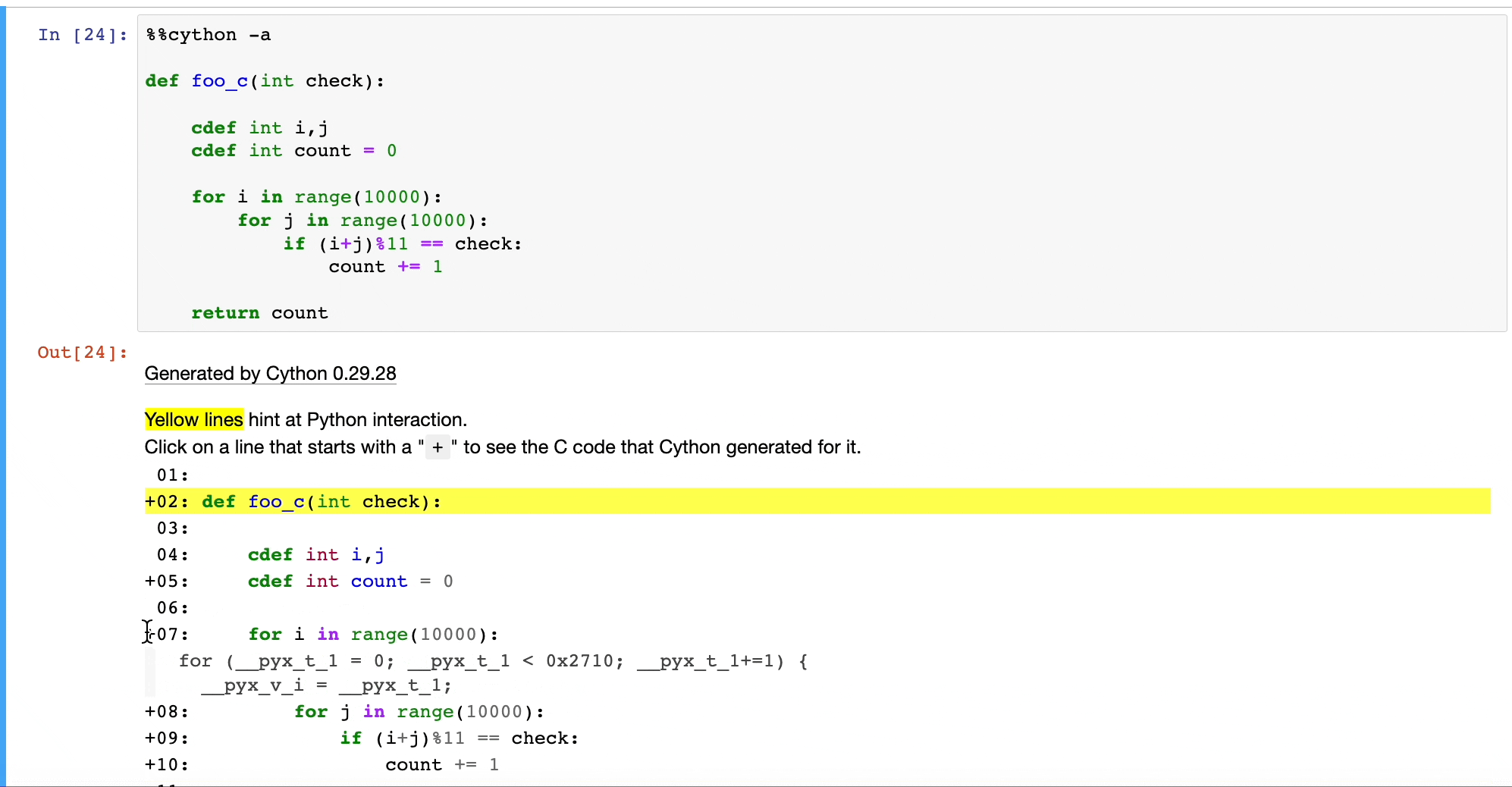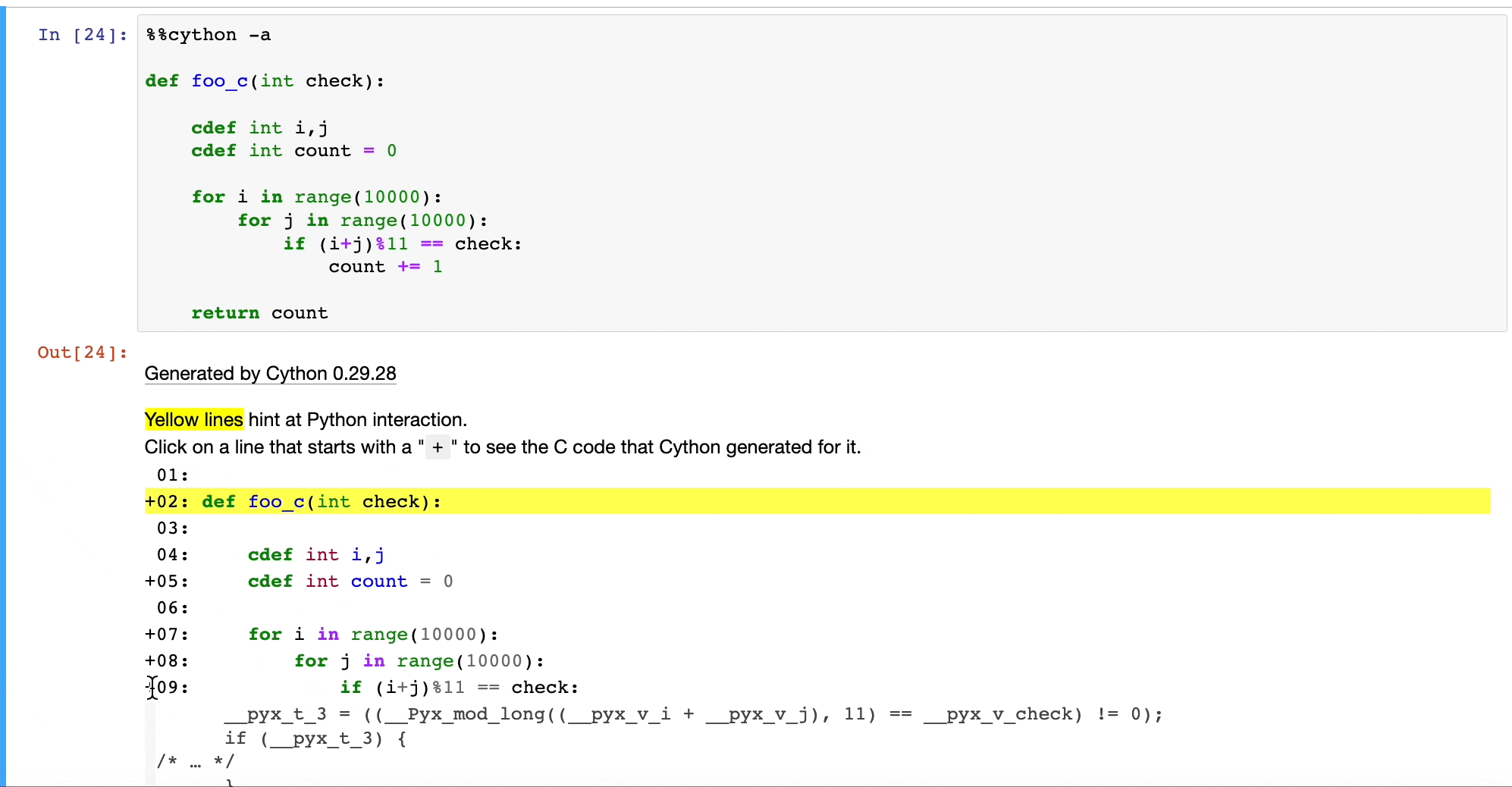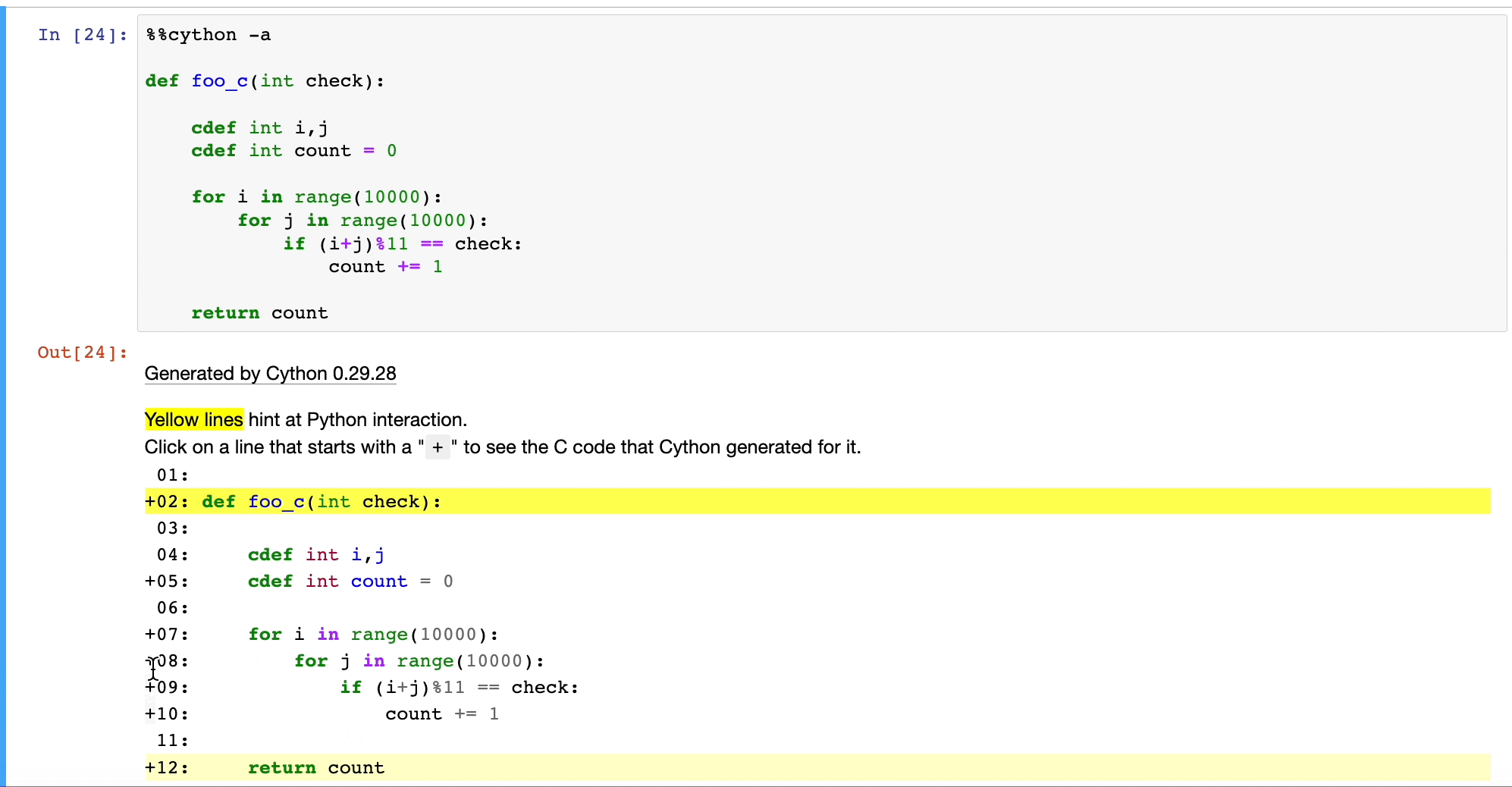
This will run at native machine code speed.
To do so, we can invoke the method as we usually would:
The speedup is evident from the image below:

Python code is slow.
But Cython provides over 100x speedup.
Why does this work?
Essentially, Python is dynamic in nature.
For instance, we can define a variable of a specific type. But later, we can change it to some other type.

But these dynamic manipulations come at the cost of run time. They also introduce memory overheads.
However, Cython restricts Python’s dynamicity.
More specifically, we avoid the above overheads by explicitly specifying the variable data type.

The above declaration restricts the variable to a specific data type. This means the program would never have to worry about dynamic allocations.
This speeds up run-time and reduces memory overheads.
Isn’t that cool?
I prepared this notebook for you to get started with Cython: Cython Jupyter Notebook.
👉 Over to you: Can you tell some more limitations of Python’s default interpreter?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Helpful and concise😌
A very nice article again. Would you write about Cython disadvantages, too?