
Approximate Nearest Neighbor Search Using Inverted File Index
Speedup traditional kNN.

One of the biggest issues with nearest neighbor search using kNN is that it performs an exhaustive search.
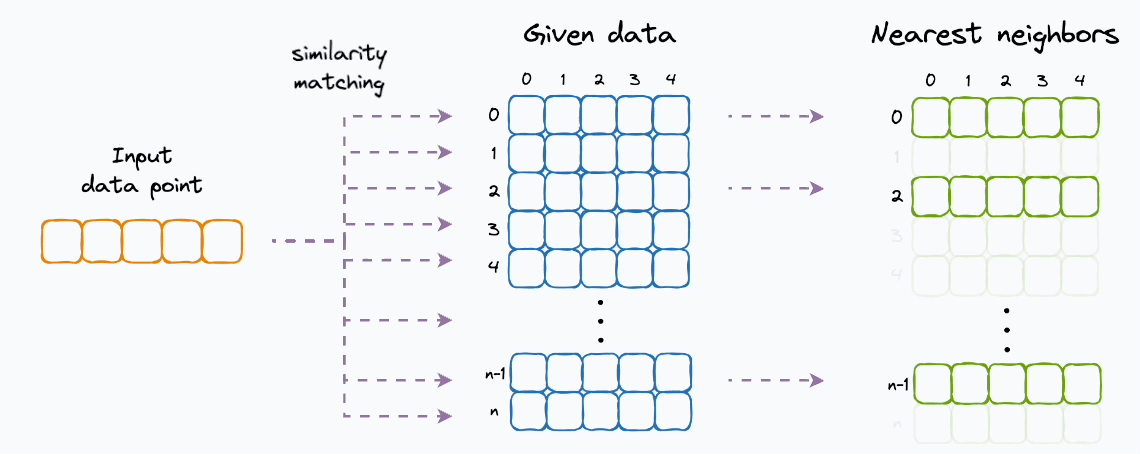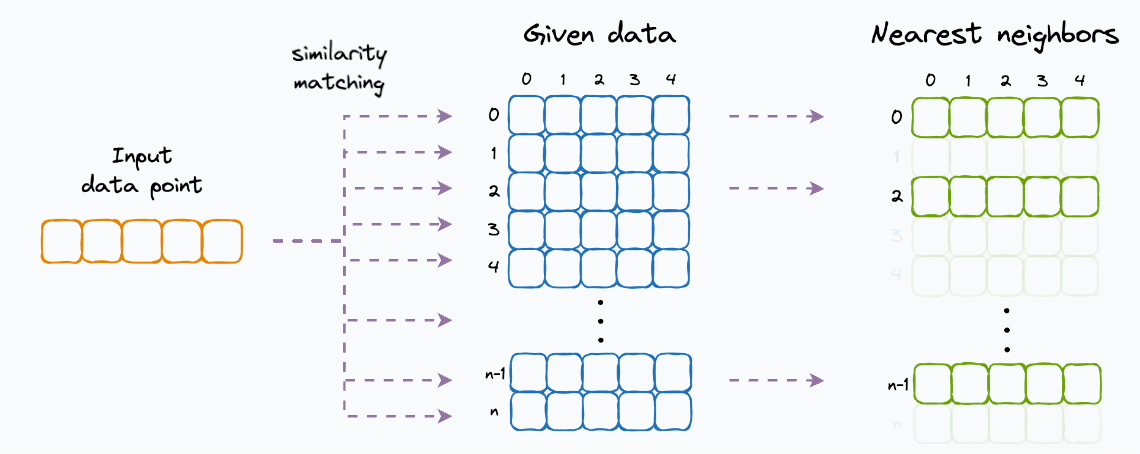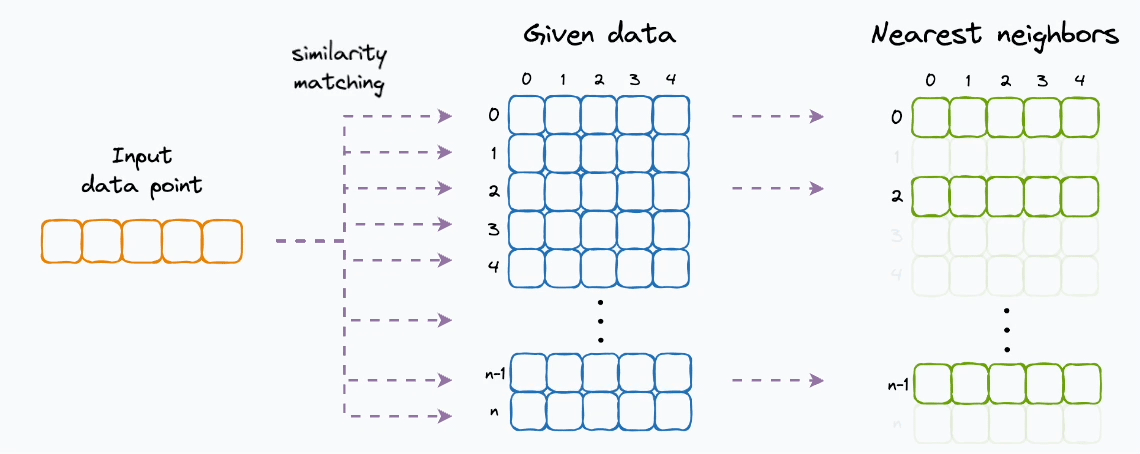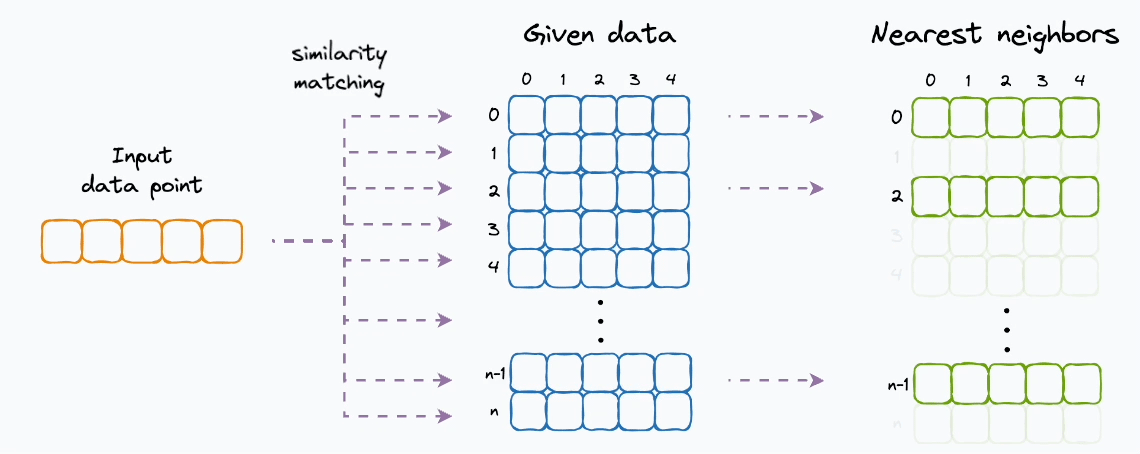
In other words, the query data point must be matched across all data points to find the nearest neighbor(s).
This is highly inefficient, especially when we have many data points and a near-real-time response is necessary.
That is why approximate nearest neighbor search algorithms are becoming increasingly popular.
The core idea is to narrow down the search space using indexing techniques, thereby improving the overall run-time performance.

Inverted File Index (IVF) is possibly one of the simplest and most intuitive techniques here, which you can immediately start using.
Here’s how it works:
Given a set of data points in a high-dimensional space, the idea is to organize them into different partitions, typically using clustering algorithms like k-means.

As a result, each partition has a corresponding centroid, and every data point gets associated with only one partition corresponding to its nearest centroid.
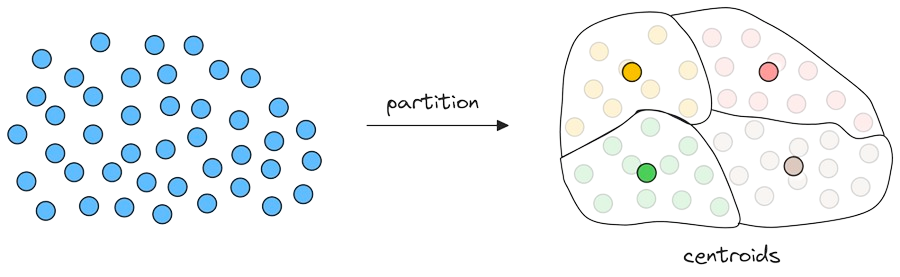
Also, every centroid maintains information about all the data points that belong to its partition.

Indexing done!
Here’s how we search.
When searching for the nearest neighbor(s) to the query data point, instead of searching across the entire dataset, we first find the closest centroid to the query:

Once we find the nearest centroid, the nearest neighbor is searched in only those data points that belong to the closest partition found:
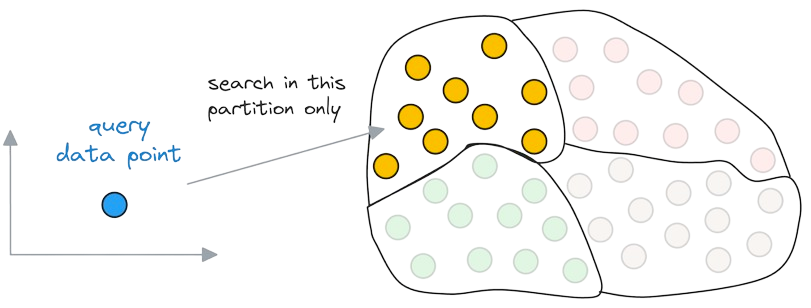
Let’s see how the run-time complexity stands in comparison to traditional kNN.
Consider the following:
There are N data points
Each data point is D dimensional
We create K partitions.
Lastly, for simplicity, let’s assume that each partition gets equal data points.
In kNN, the query data point is matched to all N data points, which makes the time complexity → O(ND).
In IVF, however, there are two steps:
Match to all centroids → O(KD).
Find the nearest neighbor in the nearest partition → O(ND/K).
The final time complexity comes out to be the following:

…which is significantly lower than that of kNN.
To get some perspective, assume we have 10M data points. The search complexity of kNN will be proportional to 10M.
But with IVF, say we divide the data into 100 centroids, and each partition gets roughly 100k data points.
Thus, the time complexity comes out to be proportional to 100 + 100k = 100100, which is nearly 100 times faster.
Of course, it is essential to note that if some data points are actually close to the input data point but still happen to be in the neighboring partition, we will miss them during the nearest neighbor search, as shown below:

But this accuracy tradeoff is something we willingly accept for better run-time performance, which is precisely why these techniques are called “approximate nearest neighbors search.”
In one of the recent deep dives on vector databases (not paywalled), we discussed 4 such techniques, along with an entirely beginner-friendly and thorough discussion on Vector Databases.
Check it out here if you haven’t already: A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
Moreover, around 6 weeks back, we discussed two powerful ways to supercharge kNN models in this newsletter. Read it here: Two Simple Yet Immensely Powerful Techniques to Supercharge kNN Models.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
We have other similar options like Kd Tree and LSH for nearest neighbor search.
To mitigate the accuracy loss, if the query point is close to other partitions, you can not only search the most similar centroid but the neighbouring centroid of most similar cemtroid too. Usually the parameter is called we called "n_probs". But it comes as the expense of time complexity.