
ART: Train Agents That Can Learn From Experience
...explained step-by-step with code (100% local).

Supervised Fine-Tuning (SFT) involves collecting input-output pairs and training the model to imitate them.
But a key limitation is that it only teaches the model what to say, not how to succeed.
For agents that search, call APIs, and reason across multiple steps, you don’t want imitation, but rather you want self-improvement through trial and error.
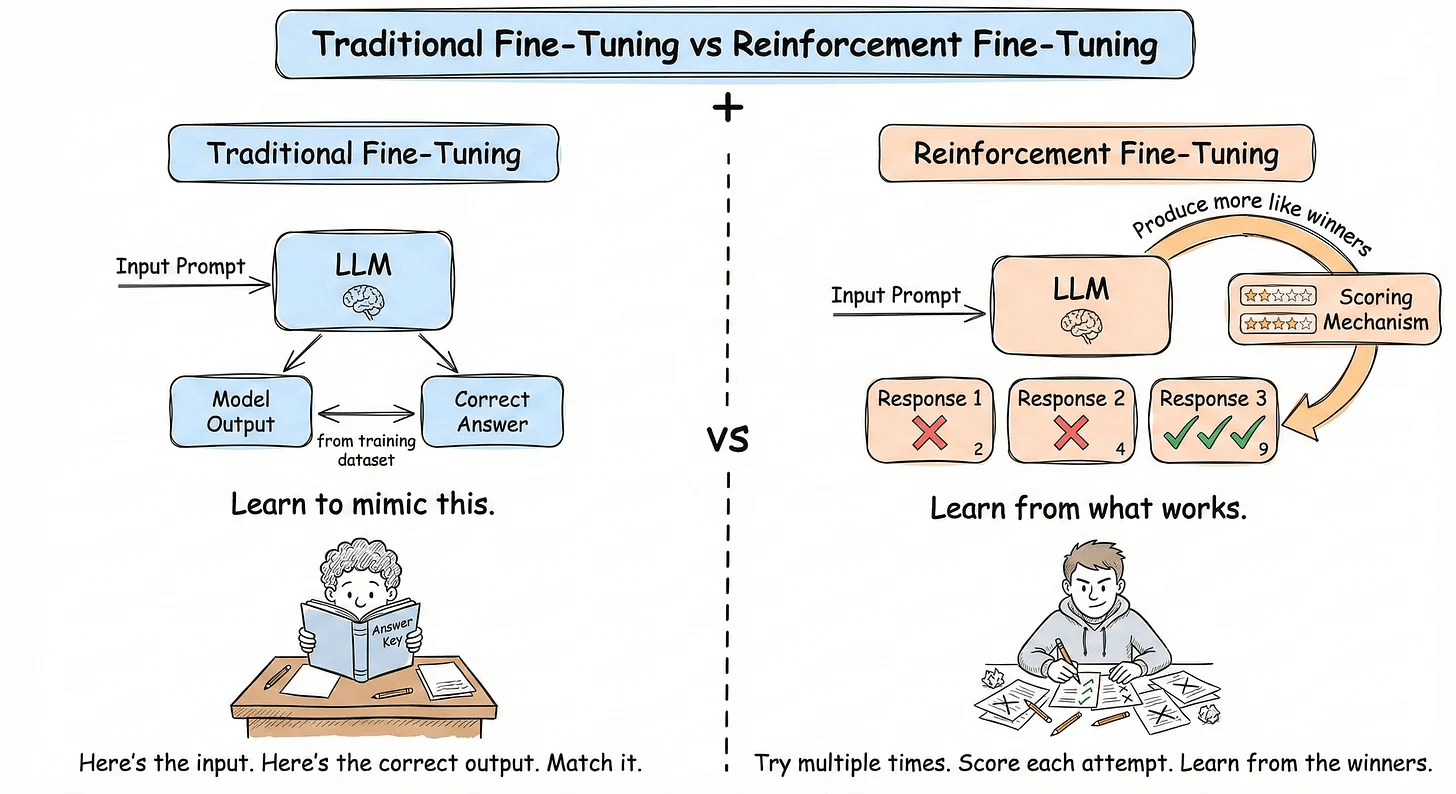
This is where Reinforcement Fine-Tuning (RFT) comes in. Instead of curated examples, you give the model a reward signal and let it discover the best strategies on its own.
Think of it this way:
SFT is like studying a textbook (memorizing answers to known questions)
RL is like on-the-job training (learning from trial, error, and feedback)
The most popular and efficient RFT algorithm is GRPO.
Today, let’s understand how it works and also cover a hands-on demo with the ART open-source framework.
How GRPO Works
GRPO was first introduced in the DeepSeekMath paper and later used to train DeepSeek-R1. Here’s the core idea:
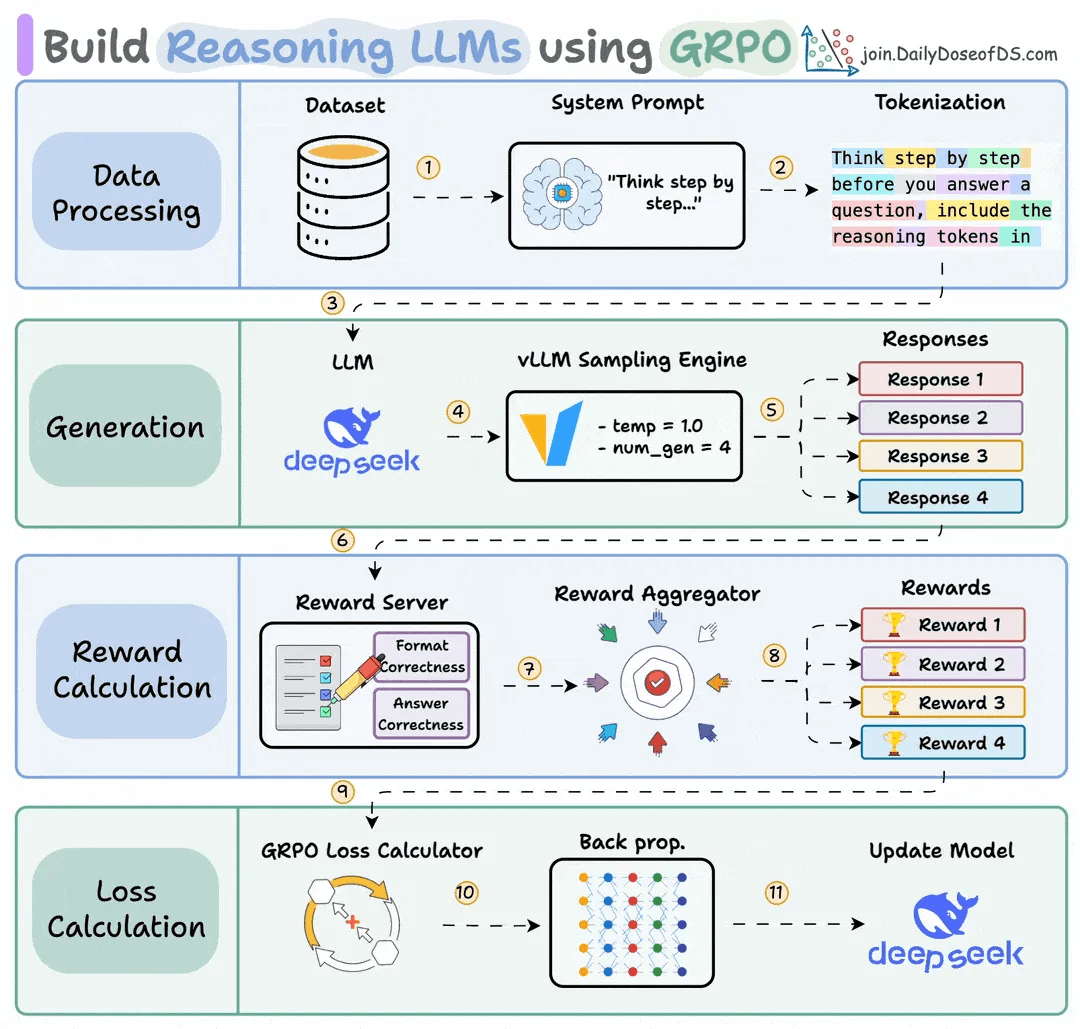
For each prompt:
Generate N different completions (say, 4) from the current model.
A reward function scores each response.
Normalize within the group by calculating a relative advantage: Did this attempt do better or worse than average?
Update the model by reinforcing above-average behaviors and suppressing below-average ones.
The key insight is that GRPO only needs relative rankings, not absolute scores. It doesn’t matter if all completions score 0.3, 0.5, and 0.7 or 30, 50, and 70, since only relative ordering drives learning.
ART: Agent Reinforcement Trainer
ART is a 100% open-source framework that allows GRPO-based reinforcement learning to any Python application.
But here’s what makes ART different from other RL frameworks.
Most RL frameworks are built for simple chatbot interactions. But real-world agents search through documents, invoke APIs, and reason across multiple steps before completing a task.
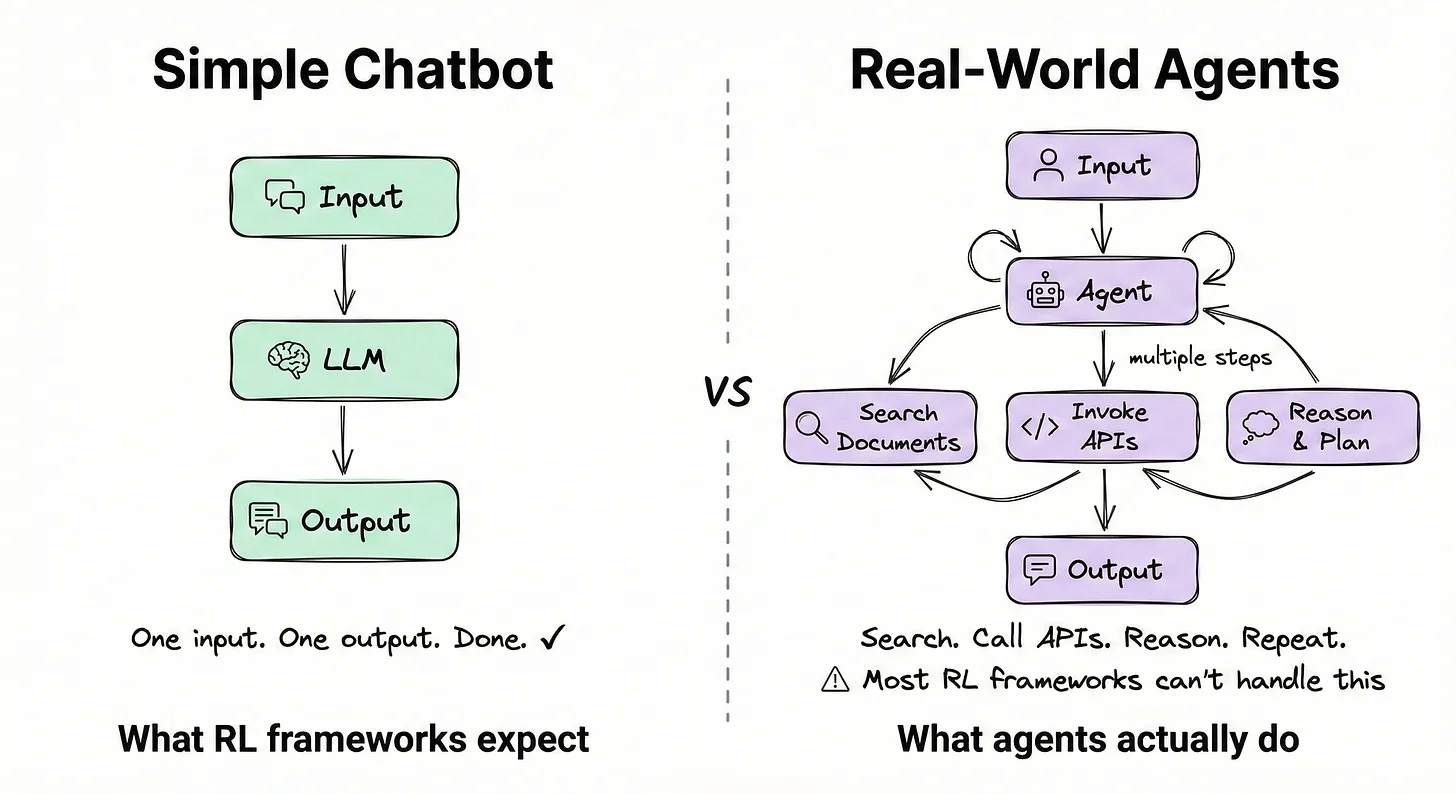
Most RL frameworks can’t handle this complexity, but ART is built for exactly this.
It provides:
Native support for tool calls and multi-turn conversations.
Integrations with LangGraph, CrewAI, and ADK.
Efficient GPU utilization during training.
Architecture
ART splits into two parts: a Client (your code) and a Backend (the GPU server).
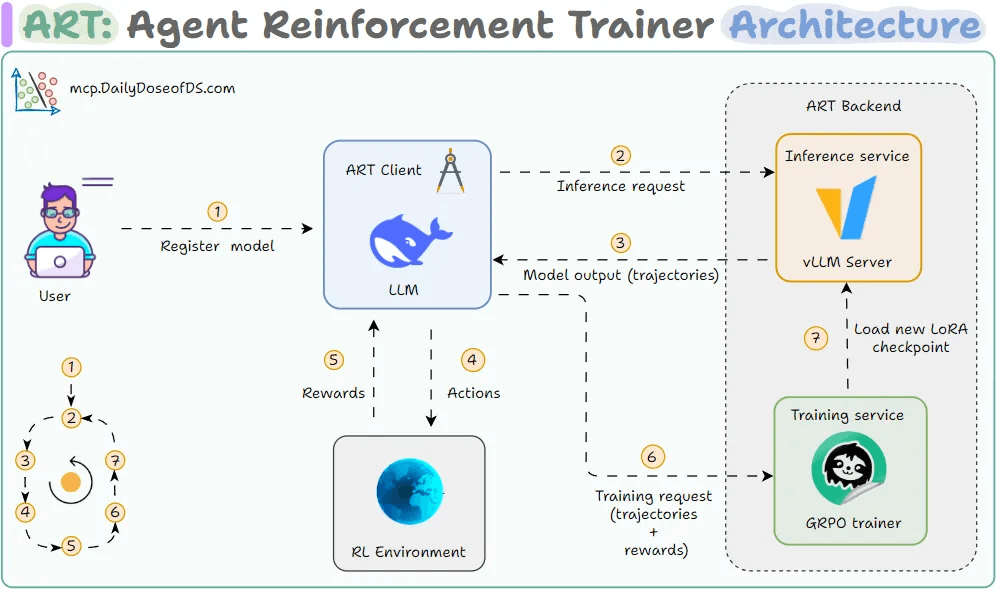
The client is where your agent code lives. You register your model with ART, and from that point, your agent sends inference requests to the backend just like it would with any OpenAI-compatible API.
As the agent runs: searching, invoking tools, reasoning, every message is recorded into what ART calls a Trajectory (the complete history of one agent run).
The backend is where the heavy lifting happens. It has two parts:
Inference service: Runs on vLLM for fast model responses.
GRPO trainer: Powered by Unsloth, this updates the weights of the model. After each training step, a new LoRA checkpoint is loaded into the inference server so that the next batch of rollouts uses the improved model.
Here’s how the full loop looks:
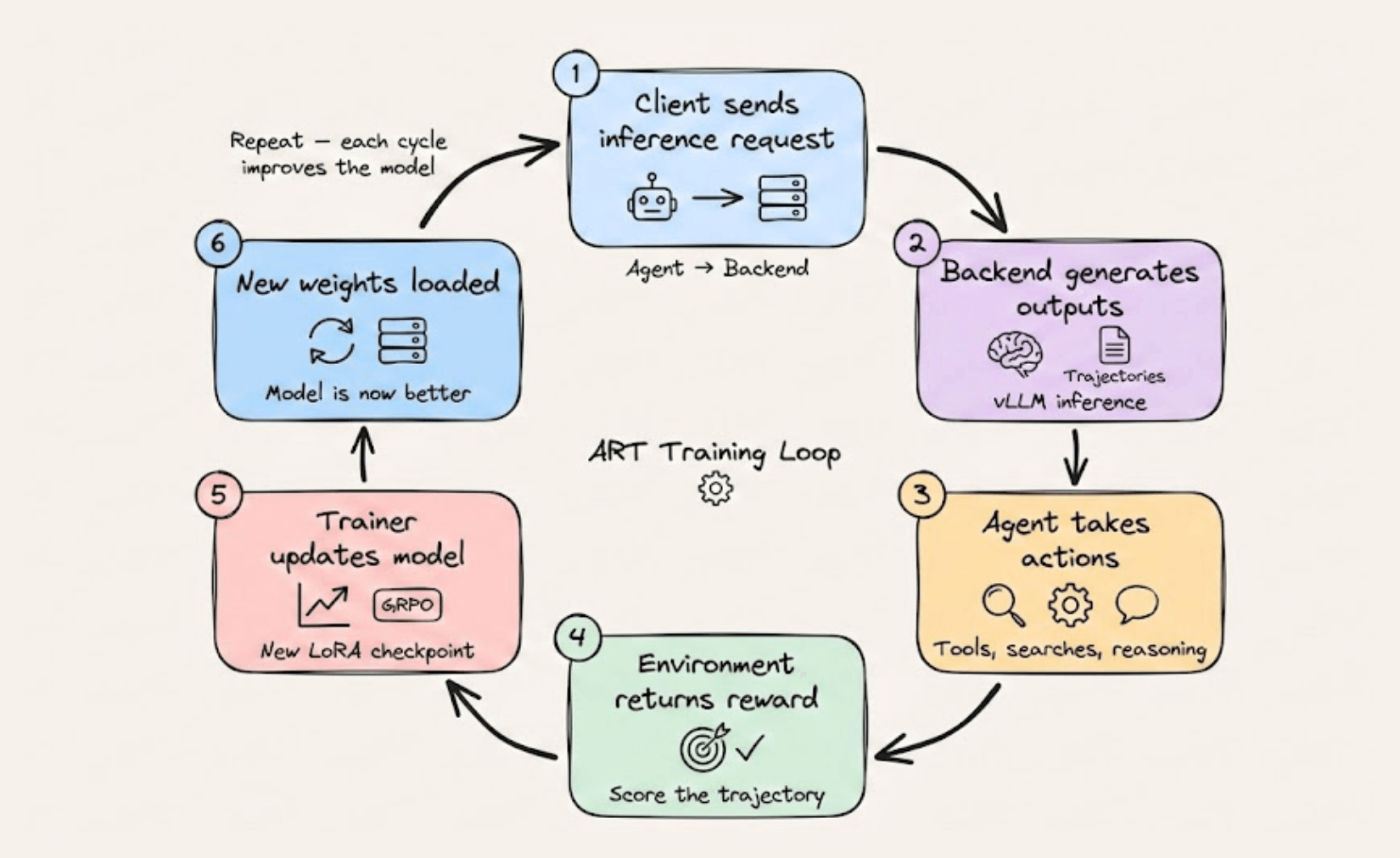
Client sends an inference request to the backend
Backend generates model outputs (trajectories)
Agent takes actions in the environment (tool calls, searches, etc.)
Environment returns a reward based on the agent’s performance
Trainer updates the model via GRPO, and a new LoRA checkpoint loads
The process repeats, and in each cycle, the model gets a little better than its previous state
RULER: Automatic Reward Functions
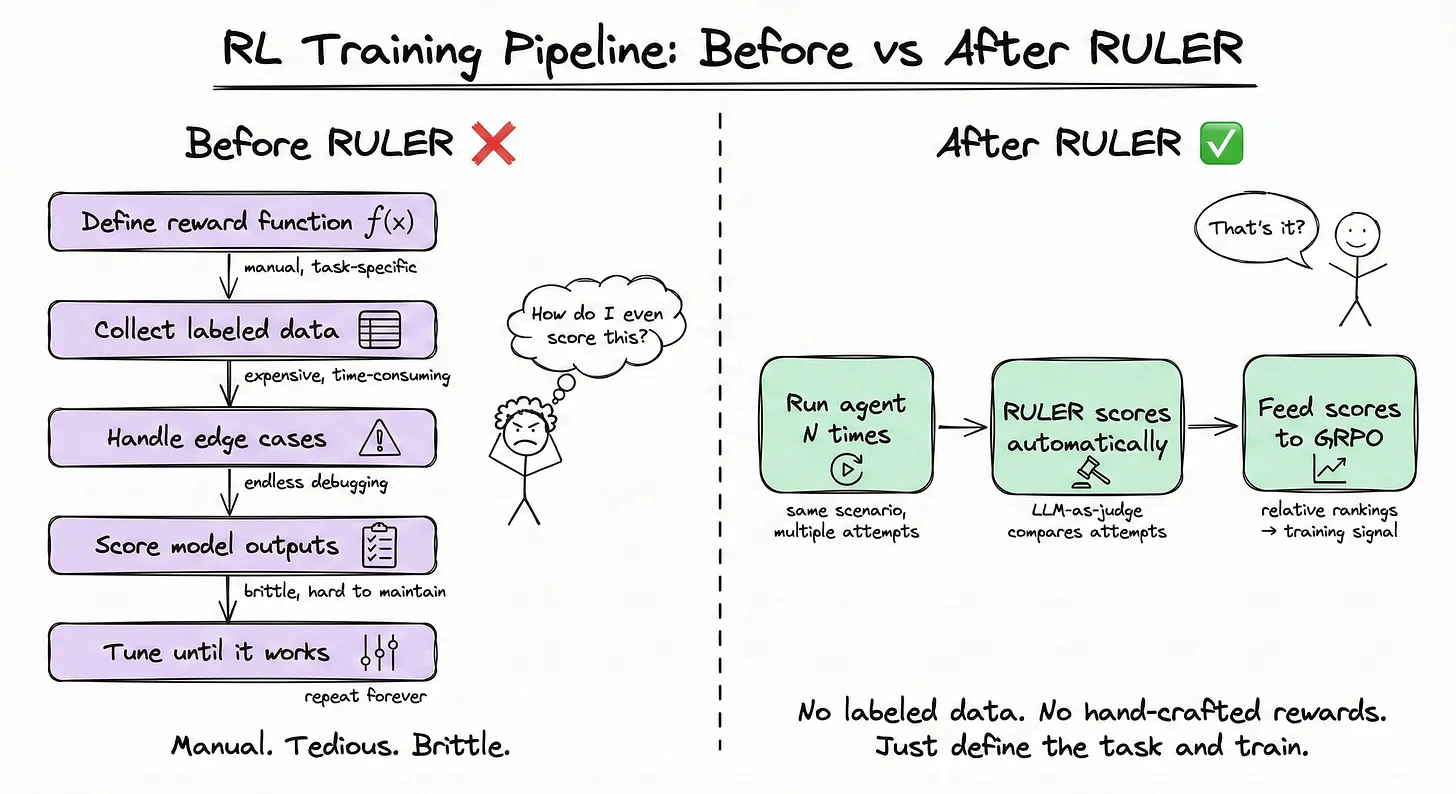
The hardest part of RL is defining good reward functions and the entire process is manual and custom.
RULER eliminates this bottleneck entirely. It uses an LLM-as-a-judge to compare multiple agent trajectories and rank them without requiring any labeled data.
It leverages two key insights:
Relative scoring is easier than absolute scoring. Asking an LLM “rate this 0-10” is inconsistent. Asking “which of these 4 attempts best achieved the goal?” is much more reliable with LLMs.
GRPO only needs relative scores. Since GRPO normalizes rewards within each group, the absolute values don’t matter. Only the ordering.
The process:
RULER generates N trajectories for a given scenario
Passes them to an LLM judge, which scores each from 0 to 1
These scores are used directly as rewards in GRPO training
This way, you can train agents without writing any reward functions.
Benchmarks: ART-E vs. o3
OpenPipe benchmarked their trained ART agent against frontier models on email search accuracy.
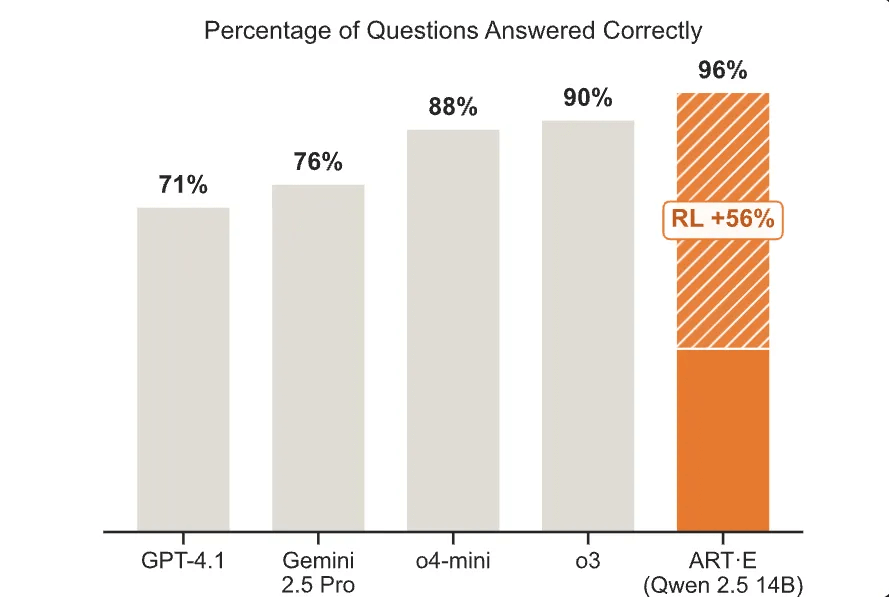
The ART-E agent (Qwen2.5-14B) achieved 96% accuracy, outperforming o3, o4-mini, Gemini 2.5 Pro, and GPT-4.1. This was a +56% improvement over the base model through RL alone.
But accuracy isn’t the whole story:
5x faster than o3 (1.1s vs 5.6s per query)
64x cheaper (0.85 vs 55.19 per 1,000 runs)
Less hallucination: RL naturally penalizes making things up
Fewer turns: The trained model learned to write more effective searches
A 14B open-source model trained with ART on a single GPU for under $80 outperformed OpenAI’s most capable model on a realistic agentic task.
[Hands-on] Teaching an Agent to master a SQL Database
Now that we understand the foundations, let’s dive into the code!
We’ll build a text-to-SQL agent, connect it to an MCP server for a company database, and a small language model that learns to query it effectively through RL training.
The agent will learn to explore schemas before querying, write correct JOINs across tables, and handle errors, all through practice, not instructions.
The reason we need RL here is because for simple single-tool calls such as “get weather for NYC,” direct approach works fine.
But the gap becomes massive with multi-step agentic workflows where the agent must chain 4-6 dependent decisions, each affecting the next.
A generic model will use suboptimal queries, waste turns on irrelevant results, and hallucinate instead of searching more.
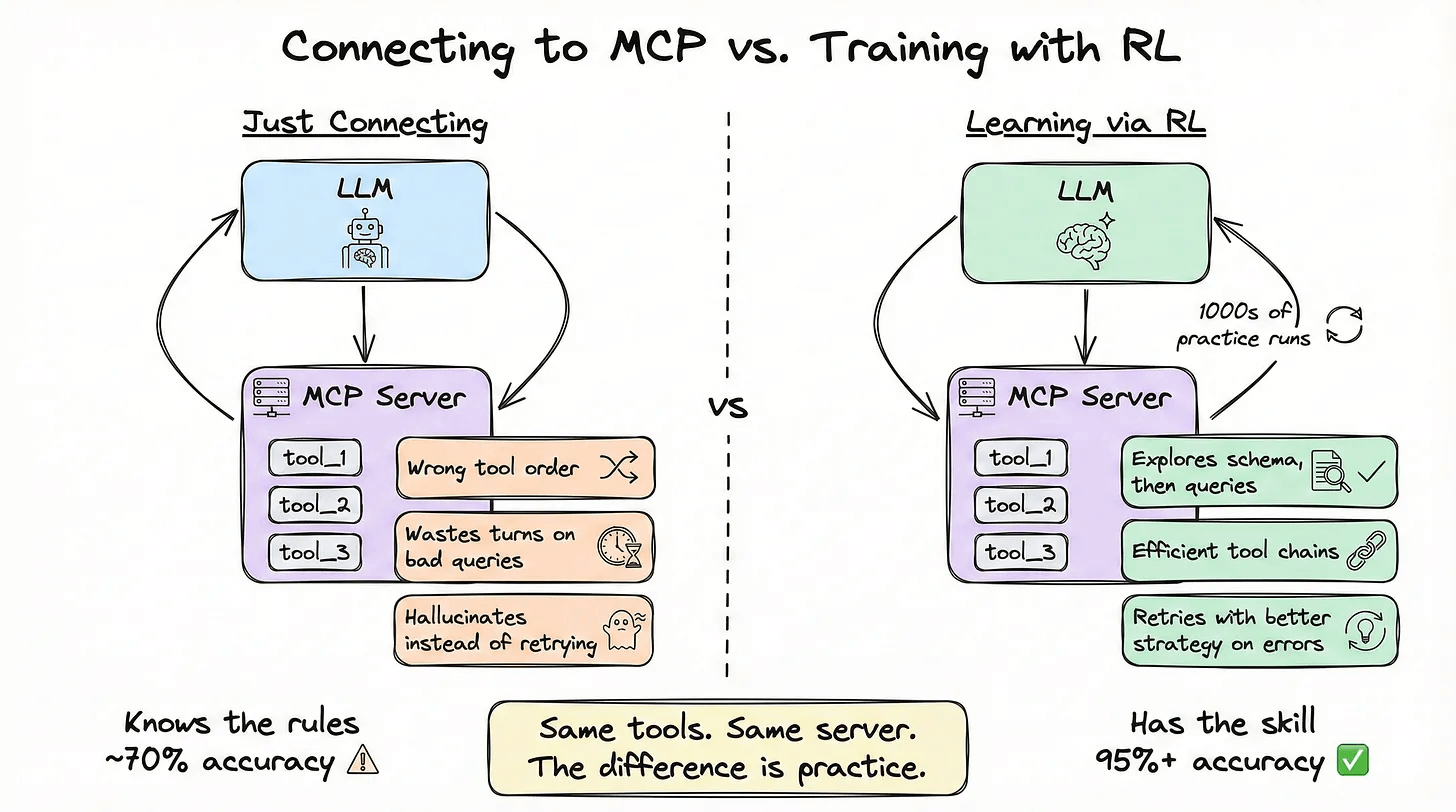
Think of it like chess: handing someone the rulebook means they know the legal moves. Training through thousands of games makes them actually good (that’s RL).
Installation
We start by installing all the necessary dependencies:

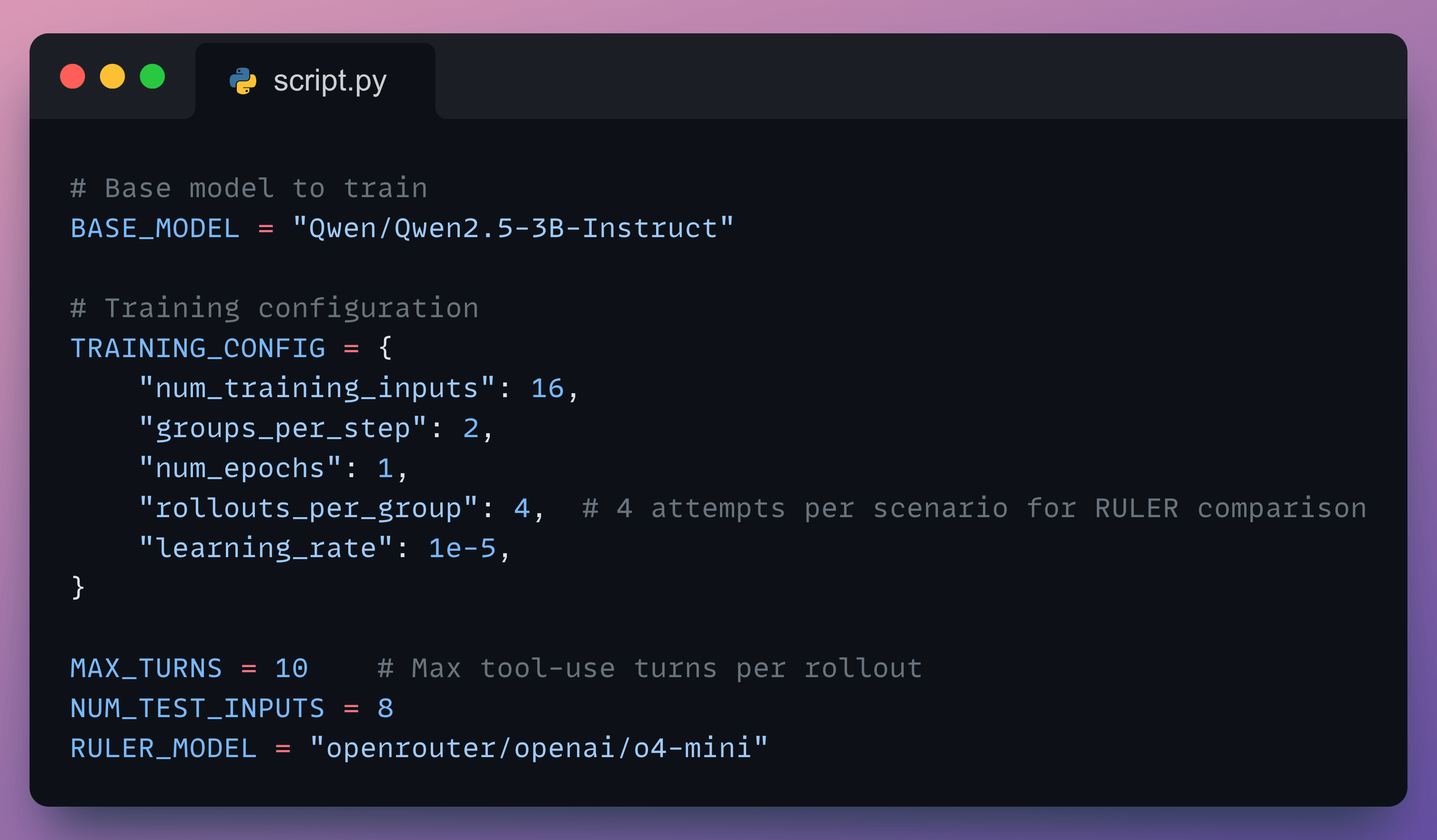
Set the training config and judge LLM
Our RULER reward function requires a good model to judge the quality of the agent’s performance. For this example, we’ll use OpenAI’s o4-mini model as the LLM judge.
We’ll start with a Qwen2.5-3B base model, use RULER for automatic reward scoring, and train with GRPO using ART’s backend on vLLM.
Create the Database
We create a simple company database containing three tables and populate them.
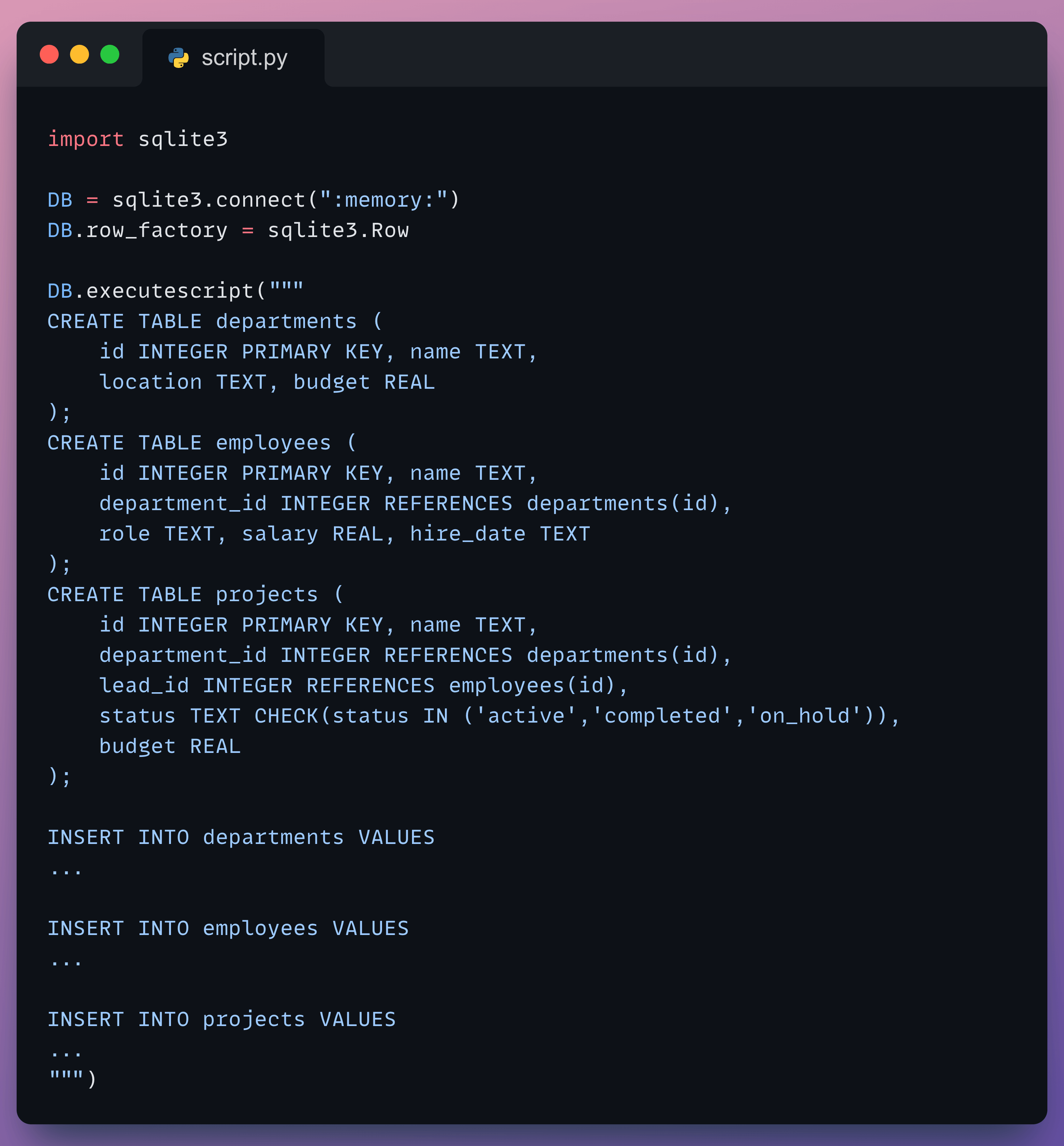
Departments: contains location and budget info for different departments
Employees: contains info about the employees, such as name, department, salary, role, etc.
Projects: contains info on the ongoing projects in the company
Build the MCP server
Instead of relying on a third-party hosted server, we’ll build our own using FastMCP and host it locally.
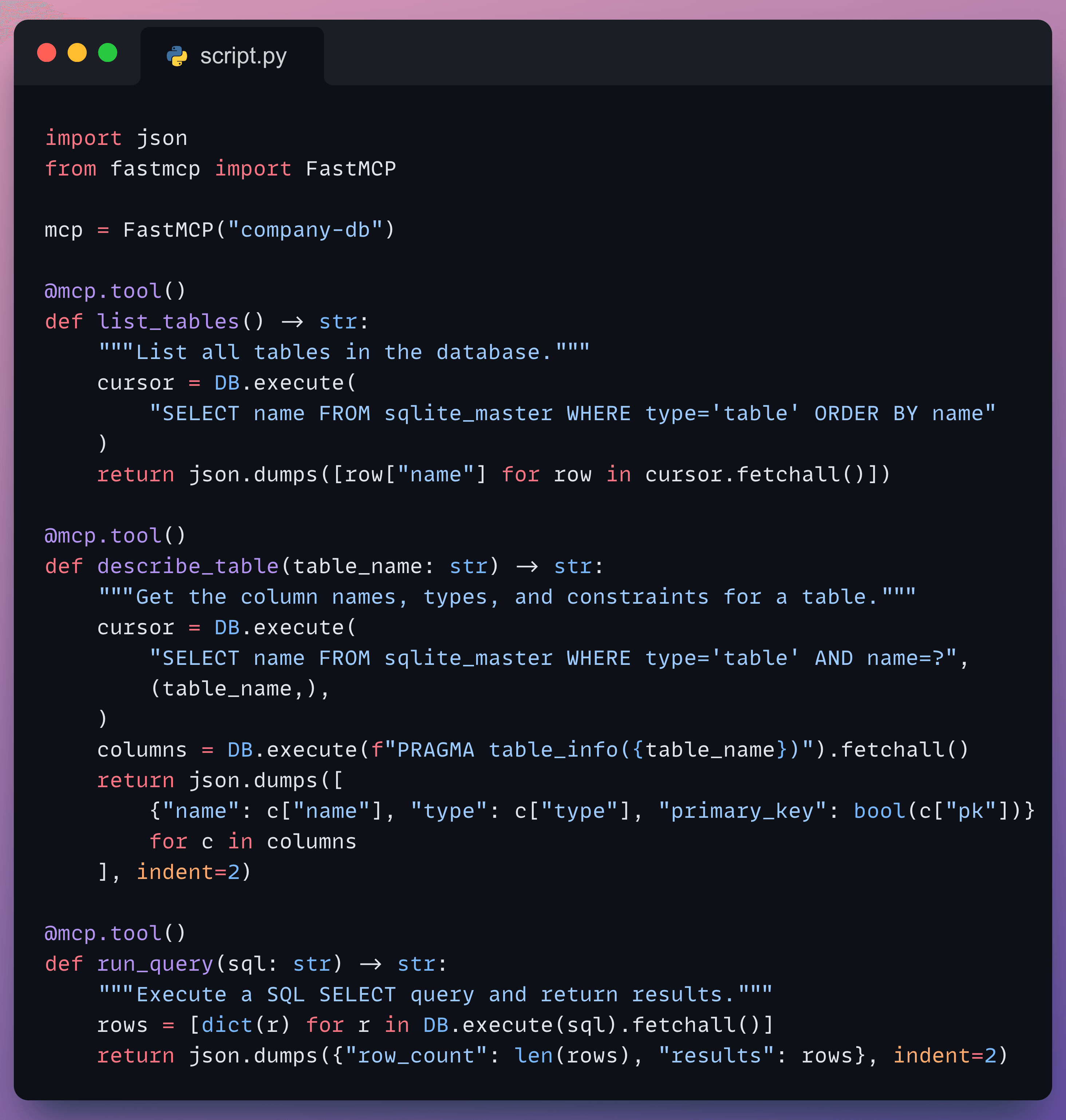
This is a simple database server with 3 tools that the agent will learn to use:
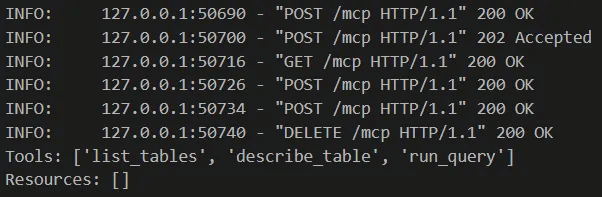
list_tables()— discover what tables are availabledescribe_table(table_name)— check schema before queryingrun_query(sql)— execute SQL queries
After defining our MCP server, we run it as a background process so the training loop can connect to it:
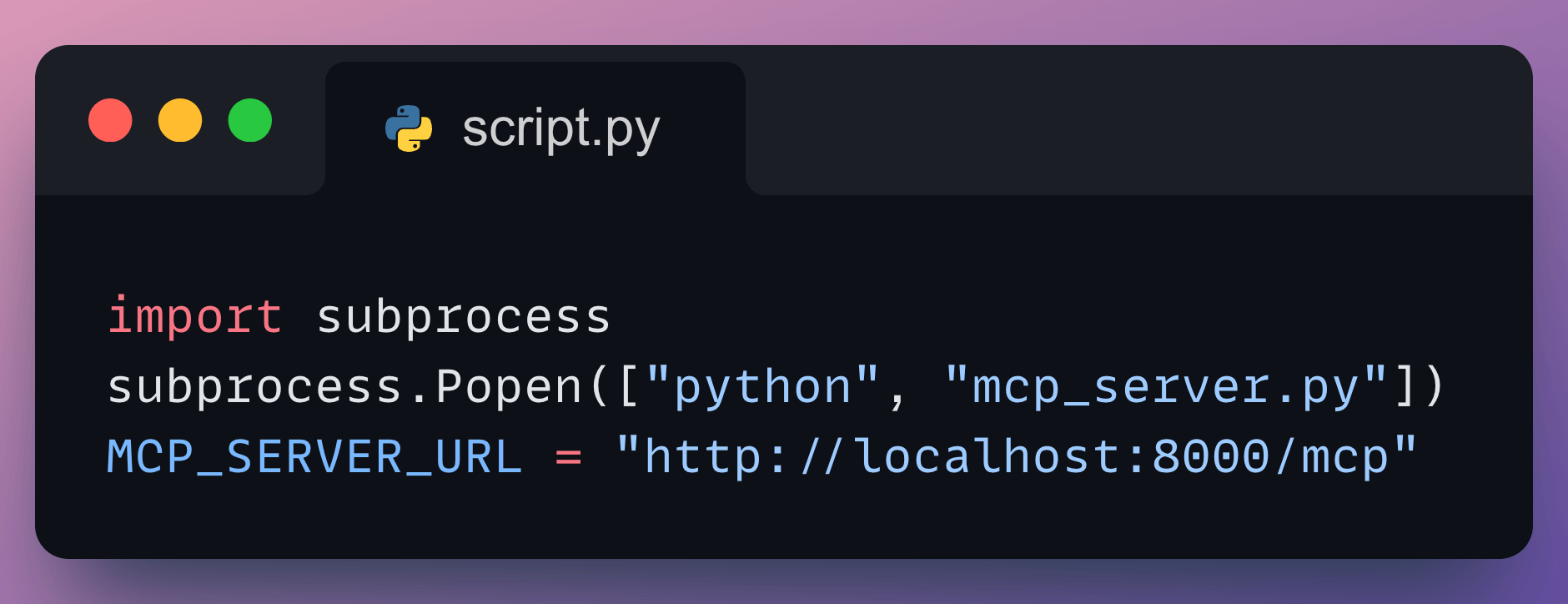
Our server gets started successfully on port 8000:
Connect & Discover Tools
ART connects to the MCP server and discovers available tools automatically:
Auto-Generate Training Scenarios
Instead of manually writing training data, ART uses an LLM to automatically generate diverse training scenarios based on the discovered tools:

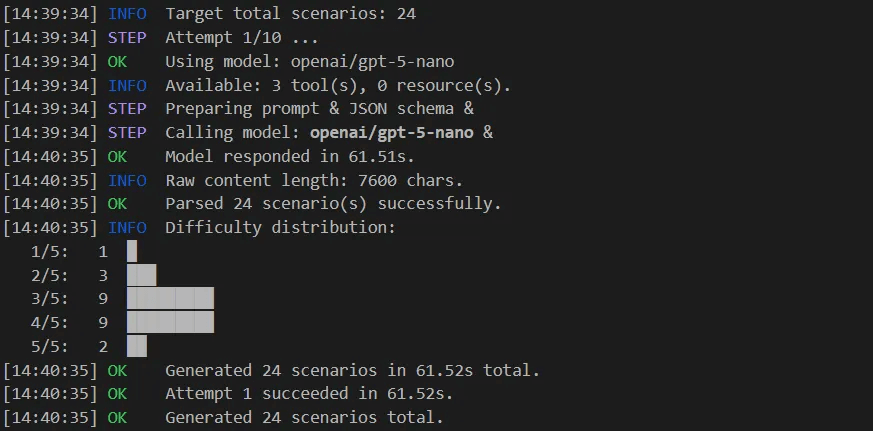
The generator examines the tool schemas and creates a mix of scenarios, including simple single-tool lookups, multi-step JOINs, and edge cases:
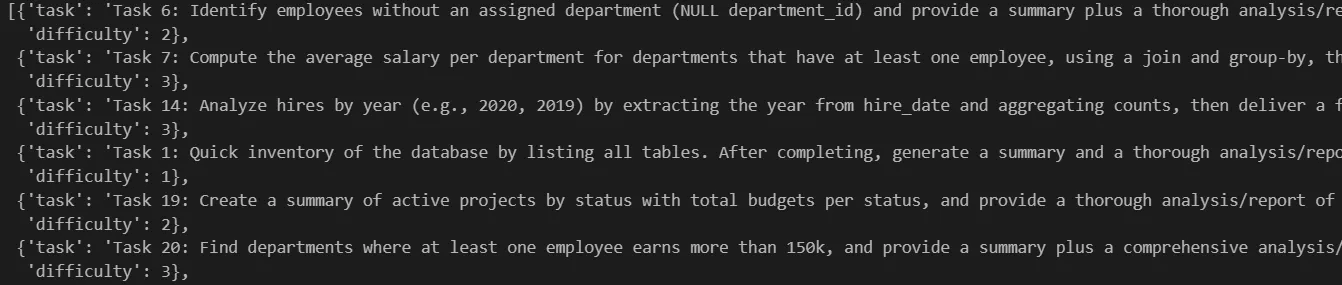
“List all tables in the database” (single tool:
list_tables)“What’s the average salary for departments having at least one employee?” (
describe_table+ filtered query)“Who leads the most expensive active project, and what department are they in?” (3 tools chained:
list_tables→describe_table× 2 → JOIN query)
No hand-crafted examples. No labeled outputs. Just the tool schemas.
RULER in Action
Before jumping into the training loop, let’s see RULER’s relative scoring in action with a simple example:
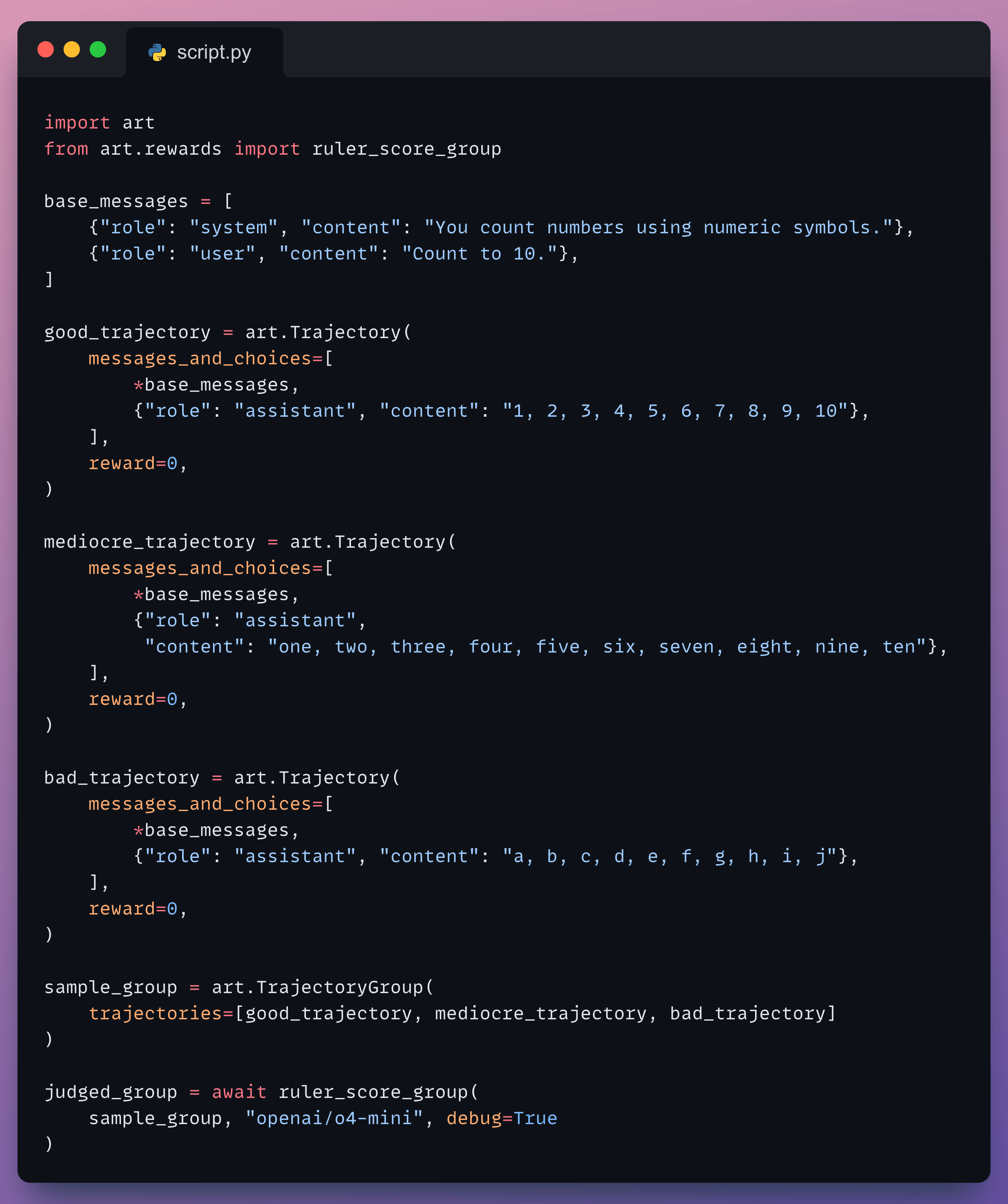
Here is the output from RULER:

RULER correctly ranked the numeric response highest (followed the “numeric symbols” instruction perfectly), the word-based response in the middle (correct count, wrong format), and the alphabetical response last (completely wrong). All without any labeled data, just with a single system prompt.
Initialize Model
Now we set up the trainable model and define how the agent interacts with the MCP server:
Defining a Rollout
A rollout is a single episode of the agent performing its task. The agent gets a question, uses the available tools to query the database and returns an answer:

Notice how this looks like any normal agent loop. The agent calls tools, gets results, and decides what to do next. But each run is recorded as a Trajectory that GRPO will learn from.
Early in training, the agent might try to run a query without checking the schema first and fail. Over time, it learns the correct pattern: explore first, then query.
Training Loop
This is where the magic happens. For each training step, the agent runs multiple times on each scenario, RULER scores the attempts, and GRPO updates the model:

Here’s what’s happening at each step:
For each scenario (e.g., “Find the highest-paid engineer”), the agent runs 4 times → 4 different trajectories with different tool call sequences and SQL queries.
RULER sends all 4 trajectories to the judge LLM, which compares them and scores each from 0 to 1.
model.train()feeds these relative scores into GRPO. The correct trajectories get reinforced, whereas suboptimal trajectories get suppressed.A new LoRA checkpoint loads into vLLM, and the next batch uses the improved model.
The training can be seen here:
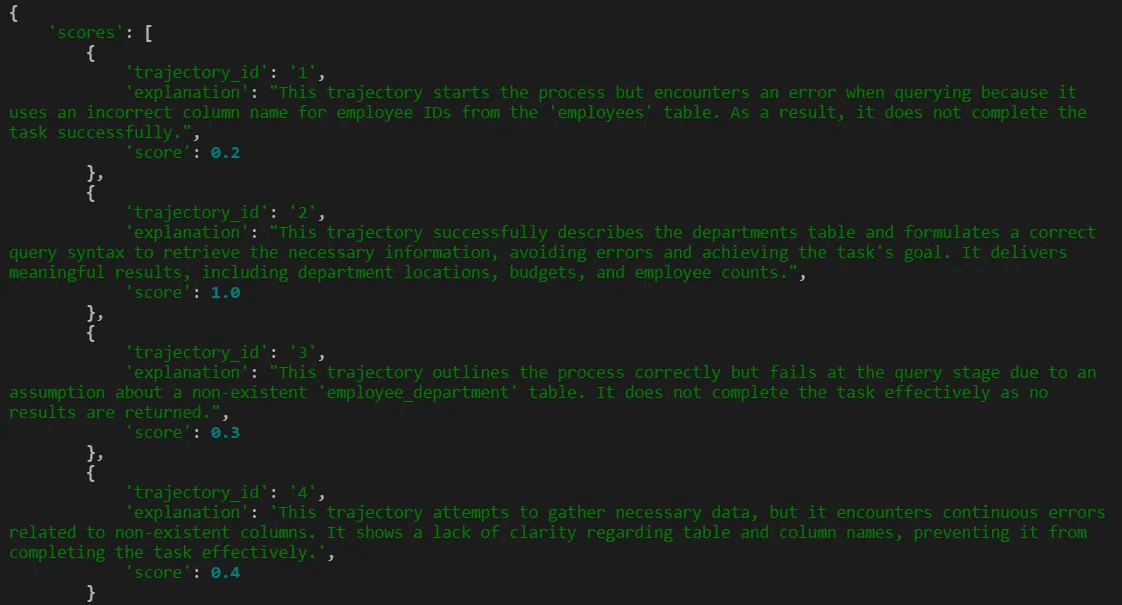
RULER can judge response quality purely from the agent’s final output without requiring any labeled data. This makes it possible to train high-quality MCP agents with minimal manual intervention.
The trained model learns to explore schemas before querying, write correct multi-table JOINs, and produce accurate answers in fewer turns, compared to the base model attempting the same tasks.
Everything runs locally. 100% open-source.
ART is 100% open-source and supports Qwen 2.5, Qwen 3, Llama, and most vLLM-compatible models.
You can find the ART GitHub repo here →
For the full code example, refer to the code here →
Thanks for reading!