


Automatic Speech Recognition with AssemblyAI
...and many more features to interact with audio.

Since late 2022 (ChatGPT’s release, to be specific), the spotlight in AI has primarily been on text and image models.
But during this period, the interest and progress in audio-based AI (like speech-to-text) have grown incredibly well too, as depicted below:

A significant inflection point came when AssemblyAI introduced Universal-1.
It’s a state-of-the-art multimodal speech recognition model trained on 12.5M hours of multilingual audio data.
So, in today’s issue, let’s talk about AssemblyAI, which offers the best AI models for any task related to speech & audio understanding.

I first used AssemblyAI two years ago, and in my experience, it has the most developer-friendly and intuitive SDKs to integrate speech AI into applications.
More specifically, in this article, we shall use AssemblyAI on an audio file (involving multiple people) to do the following:
Automatic speech recognition.
Sentence timestamps and speaker labels.
Sentiment analysis on audio.
Using AssemblyAI’s LeMUR to prompt the audio transcript.
The code for this newsletter issue is available here: AssemblyAI demo.
Let’s begin!
AssemblyAI demo
To get started, you must get an AssemblyAI API key from here. They provide 100 hours of free transcription, which is sufficient for this demo.
Next, install the AssemblyAI Python package as follows:

For the audio file, I am using Andrew Ng’s podcast (95 mins) with Lex Fridman (the audio file is available in the code I provided above).
Transcribing the file with AssemblyAI just takes five lines of intuitive code:
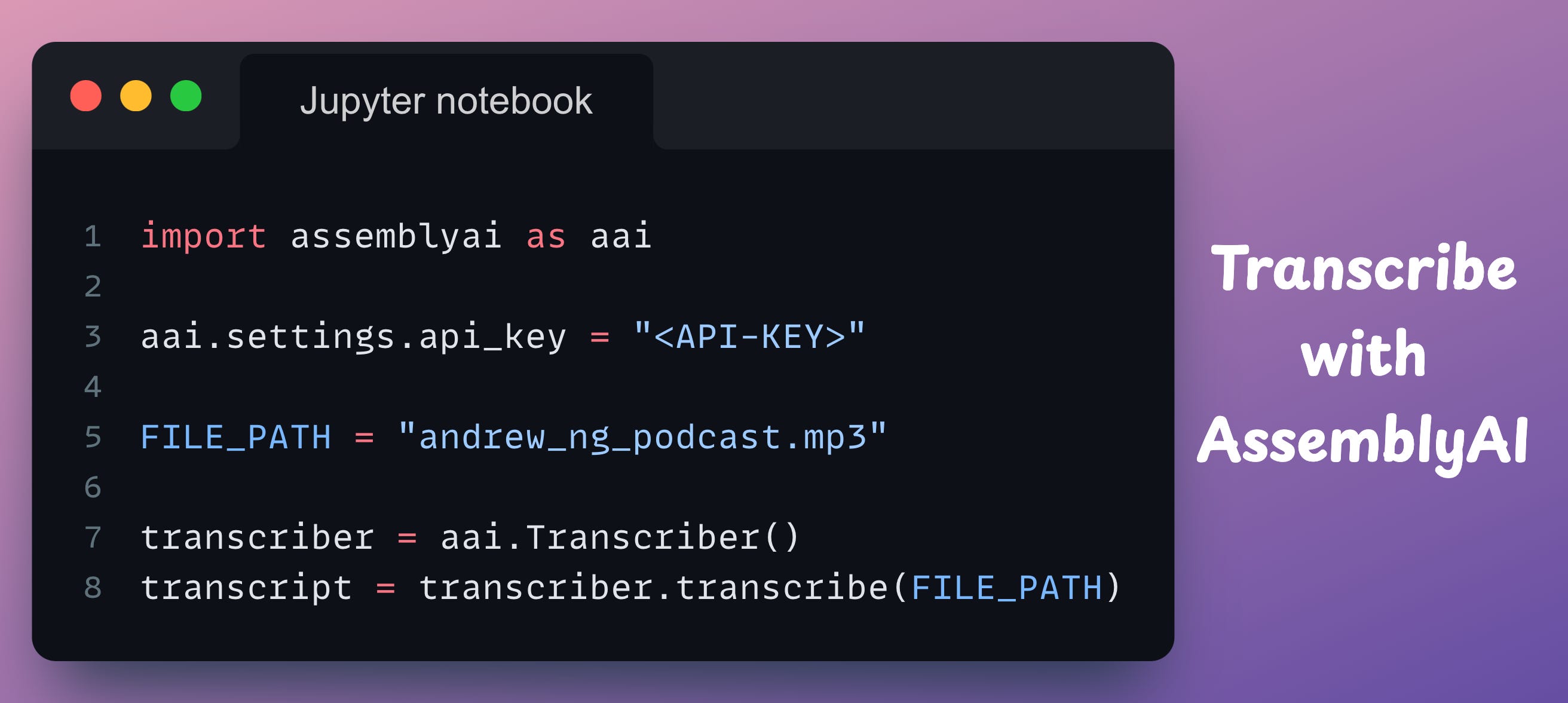
Line 1 → Import the package
Line 3 → Set the API key
Line 5 → Specify the file path (this can be a remote location if you prefer that).
Line 7 → Instantitate the AssemeblyAI
transcriberobject.Line 8 → Send the file for transcription.
Done!
The transcript object can be used to check the status of the request:

As it says “completed”, we can print the transcript as follows:
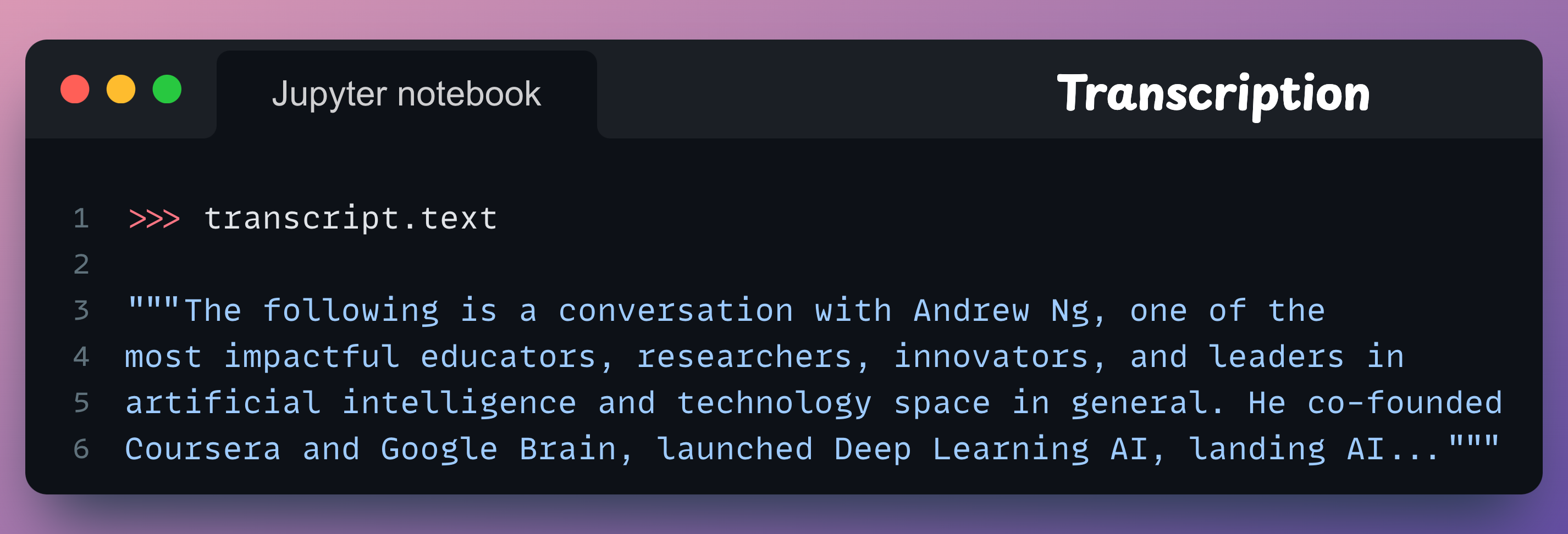
Moreover, the id attribute of the transcript object can be used to retrieve the transcript later if needed:

Moving on, to obtain the sentence-level timestamps, we can use the get_sentences() method of the transcript object:
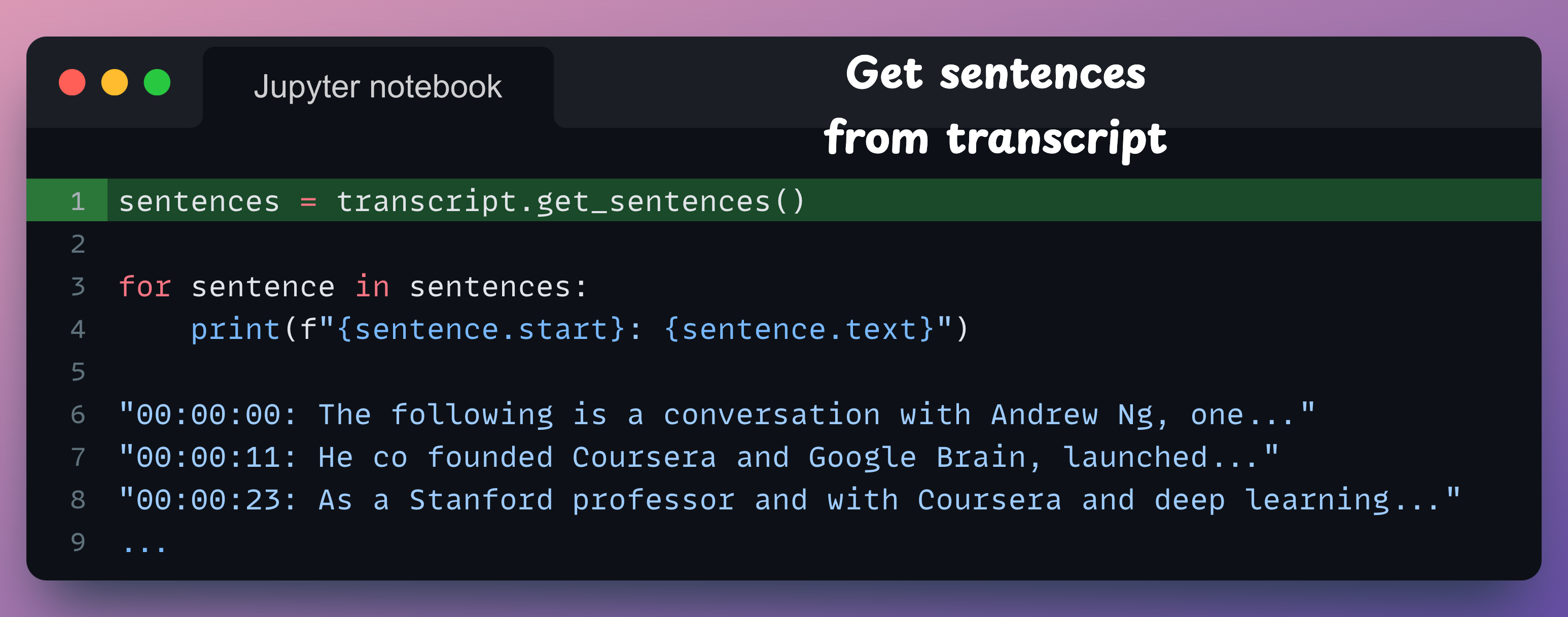
sentence.start provides timestamps in milliseconds. I formatted them here for better comprehensibility. The formatting function is not shown here.Similarly, we can also get word-level timestamps if needed. More details are available in the docs here: API docs.
Now I know what you are thinking…
The features discussed above are some basic things one would expect from any transcription service.
Also, a plain transcript may not be entirely helpful in most cases.
Thus, we need more details and insights to make genuine use of audio data, which is where AssemblyAI shines.
Let’s look at other details we can extract from audio using AssemblyAI.
Speaker labels
The speaker details are missing from the above transcript. Enabling this is quite simple.
Declare a TranscriptionConfig object and specify the speaker_labels parameter during the transcription request:
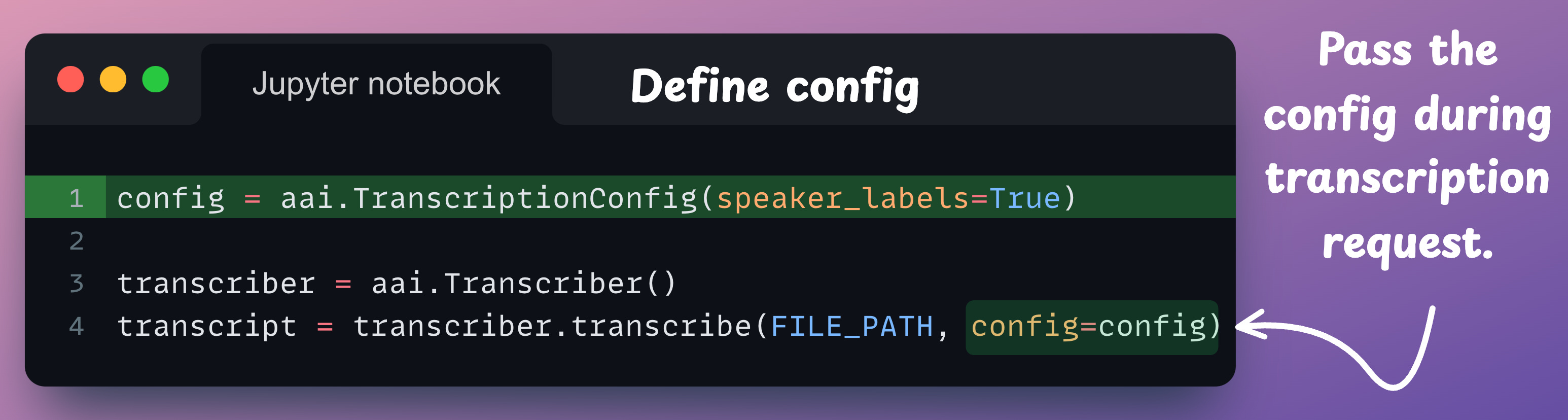
We can print the speaker labels along with the transcript as follows:

Simple, isn’t it?
More details about speaker labels are available here: API Docs.
Sentiment analysis
Determining the sentiment of each sentence is quite simple as well.
Yet again, we declare a TranscriptionConfig object and specify it during the transcription request:

Similar to how we displayed speaker labels, we can display sentiment labels sentence-by-sentence as follows:
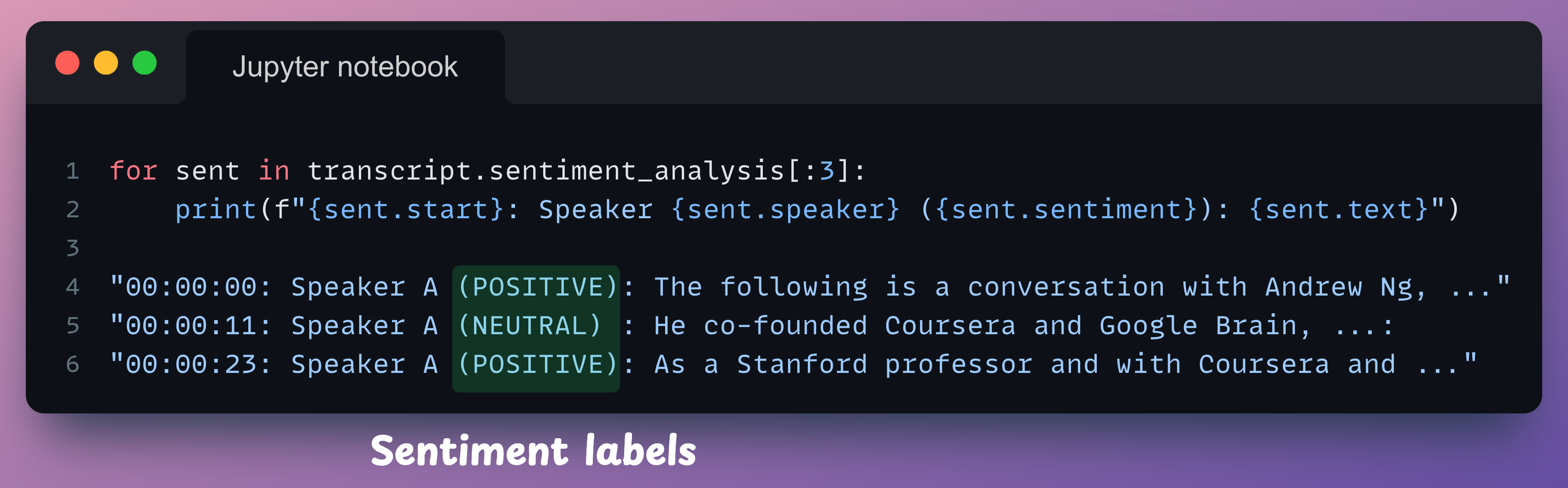
sent.start provides timestamps in milliseconds. I formatted them here for better comprehensibility. The formatting function is not shown here.We can analyze these sentiment labels to determine the speaker’s overall tone throughout the conversation.
More details about sentiment analysis are available here: API Docs.
Note: By specifying
iab_categories=Truein the config object definition, you can also do topic detection. We are not discussing this here as the process is almost the same.
Interact with audio using LeMUR
This is one of my personal favorite features of AssemblyAI.
In a nutshell, LeMUR is a framework that allows you to build LLM apps on speech data in a few lines of code, which includes:
summarizing the audio.
extracting some specific insights from the audio.
doing Q&A on the audio.
or getting any other details you wish to extract, etc.
Let’s look at a demo.

Line 1 → We declare the prompt.
Line 4 → We use the
transcriptobject returned earlier to prompt it using LeMUR.Line 6 → We print the response.
Done!
This DID NOT require us to do any of the following:
Store transcripts,
Ensure that the transcript fits into the model’s context window,
Invoke an LLM, etc.
LeMUR handles everything under the hood.
Isn’t that cool?
Departing note
I have known AssemblyAI for over two years and have also had an opportunity to talk to their founder — Dylan.
AssemblyAI envisioned creating superhuman Speech AI models that can unlock the capability to build an entirely new class of applications and products with voice data.
Universal-1 was one of the biggest wins of AssemblyAI, positioning it as a market leader in speech recognition, even beyond reputed players like Google, Microsoft, OpenAI’s Whisper, etc. This is depicted below:
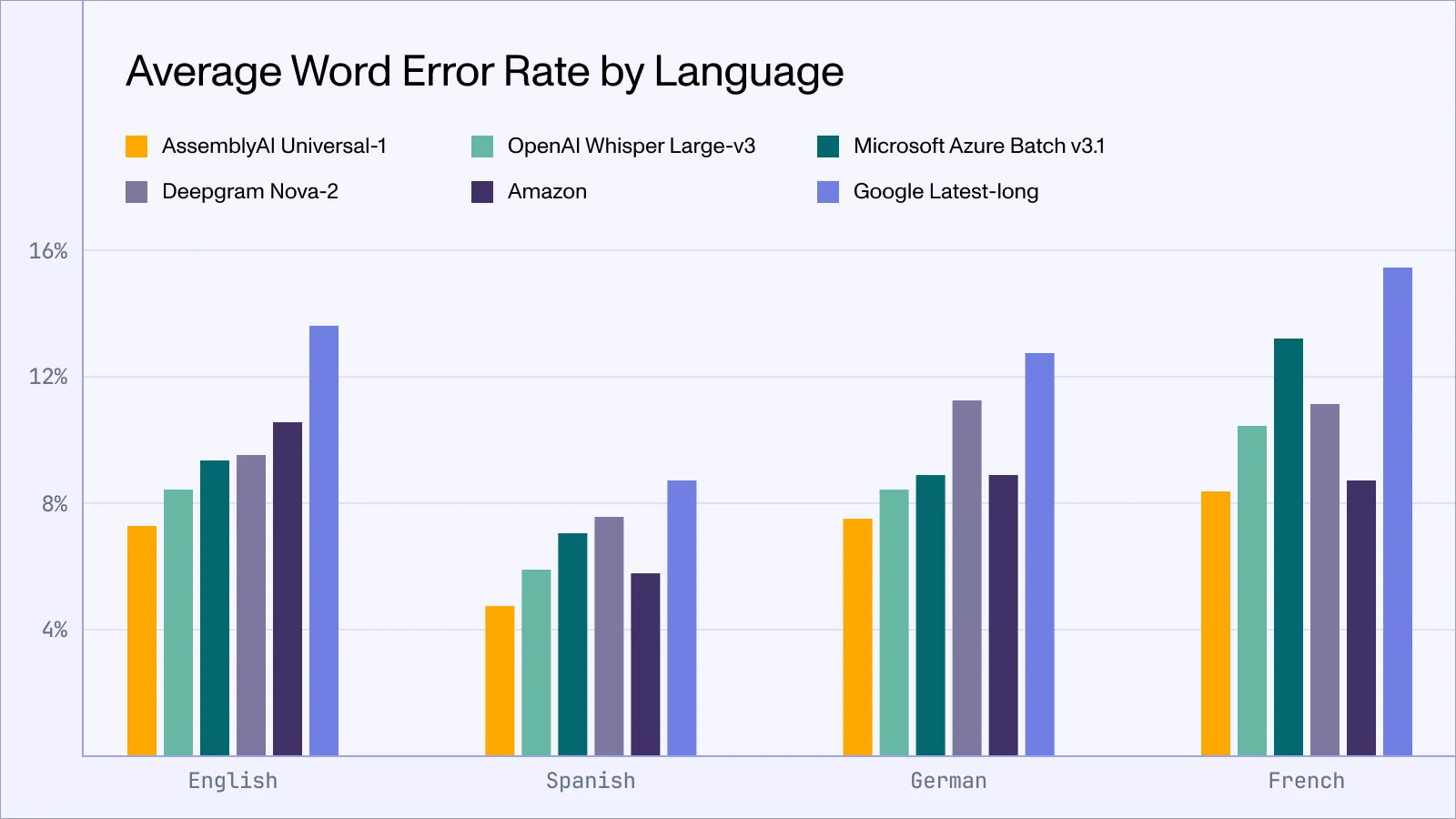
Universal-1 exhibits 10% or greater improvement in English, Spanish, and German speech-to-text accuracy compared to the next-best system.
Universal-1 has 30% lower hallucination rate than OpenAI Whisper Large-v3.
Universal-1 is capable of transcribing multiple languages within a single audio file.
Isn’t that impressive?
I love Assembly’s mission of supporting developers in building next-gen voice applications in the simplest and most effective way possible.
They have already made a big dent in speech technology, and I’m eager to see how they continue from here.
You can get started with Assembly here: AssemblyAI.
Also, their API docs are available here if you want to explore their services: AssemblyAI API docs.
🙌 Also, a big thanks to AssemblyAI, who very kindly partnered with me on this post and let me share my thoughts openly.
👉 Over to you: What would you use AssemblyAI for?
Thanks for reading!