
Avoid Using PCA for Visualization Unless the CEV Plot Says So
Using variance as an indicator for visualization.

Yesterday’s post on KernelPCA was appreciated by many of you.
To recall, we discussed the motivation behind using KernelPCA over PCA for dimensionality reduction.
More specifically, we understood that even though our data is non-linear, PCA still produces a linear subspace for projection, but KernelPCA handles it well:

Today, I want to continue our discussion on PCA and highlight one common misconception about PCA.
Let’s begin!
PCA, by its very nature, is a dimensionality reduction technique.
Yet, at times, many use PCA for visualizing high-dimensional datasets. This is done by projecting the given data into two dimensions and visualizing it.

While this may appear like a fair thing to do, there’s a big problem here that often gets overlooked.
To understand this problem, we first need to understand a bit about how PCA works.
The core idea in PCA is to linearly project the data to another space using the eigenvectors of the covariance matrix.
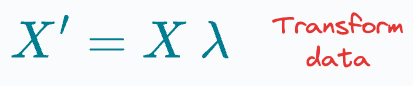
Why eigenvectors?

It creates uncorrelated features, which is useful because if features are independent, the features with the least variance can be dropped for dimensionality reduction.
It ensures that new features collectively preserve the original data variance.
If you wish to learn the mathematical origin of eigenvectors in PCA, we covered it here: PCA article.
Coming back to the visualization topic…
As discussed above, after applying PCA, each new feature captures a fraction of the original data variance.
Thus, if we intend to use PCA for visualization by projecting the data to 2-dimensions…
…then this visualization will only be useful if the first two principal components collectively capture most of the original data variance.
If they don’t, then the two-dimensional visualization will be highly misleading and incorrect.
How to determine the variance contribution of the first two principal components?
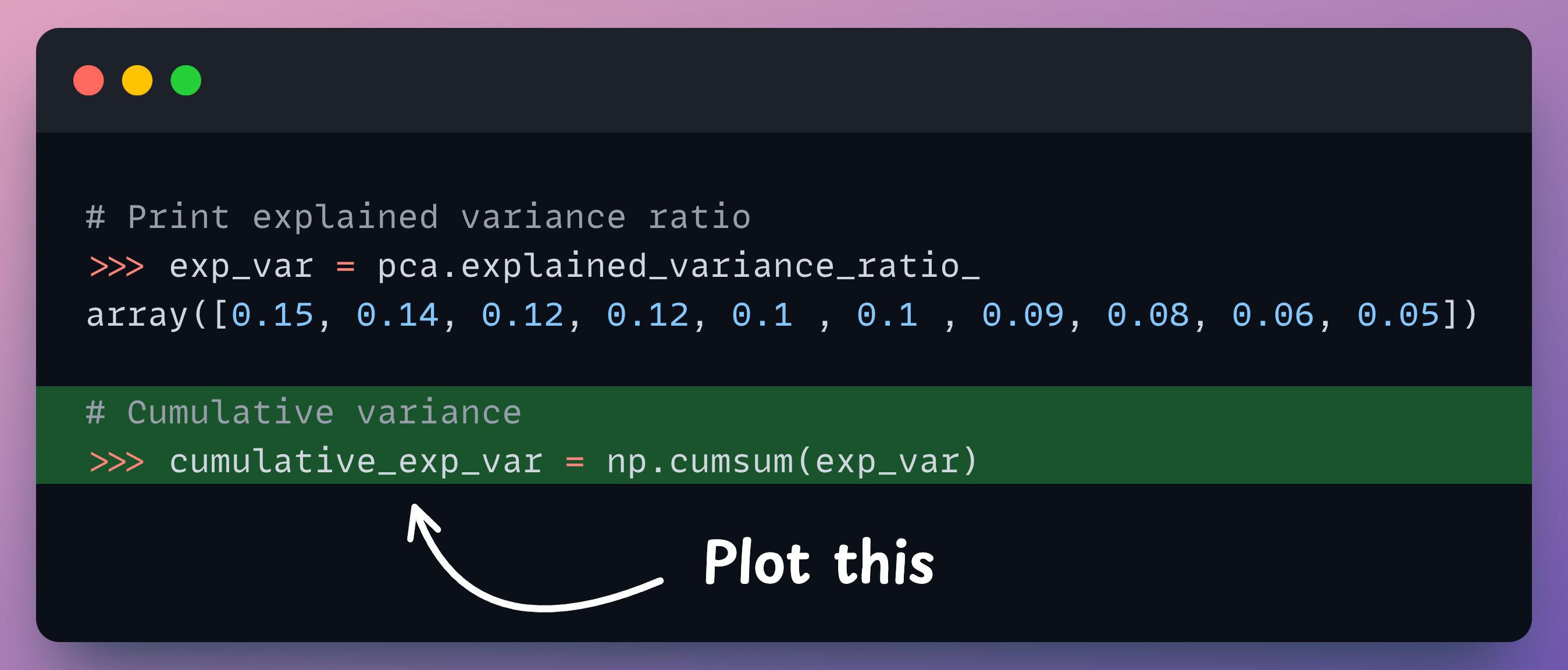
We can avoid this mistake by plotting a cumulative explained variance (CEV) plot.
As the name suggests, it plots the cumulative variance explained by principal components.
In sklearn, for instance, the explained variance fraction is available in the explained_variance_ratio_ attribute:

We can create a cumulative plot of explained variance and check whether the first two components explain the majority of variance.
For instance, in the plot below, the first two components only explain 55% of the original data variance.
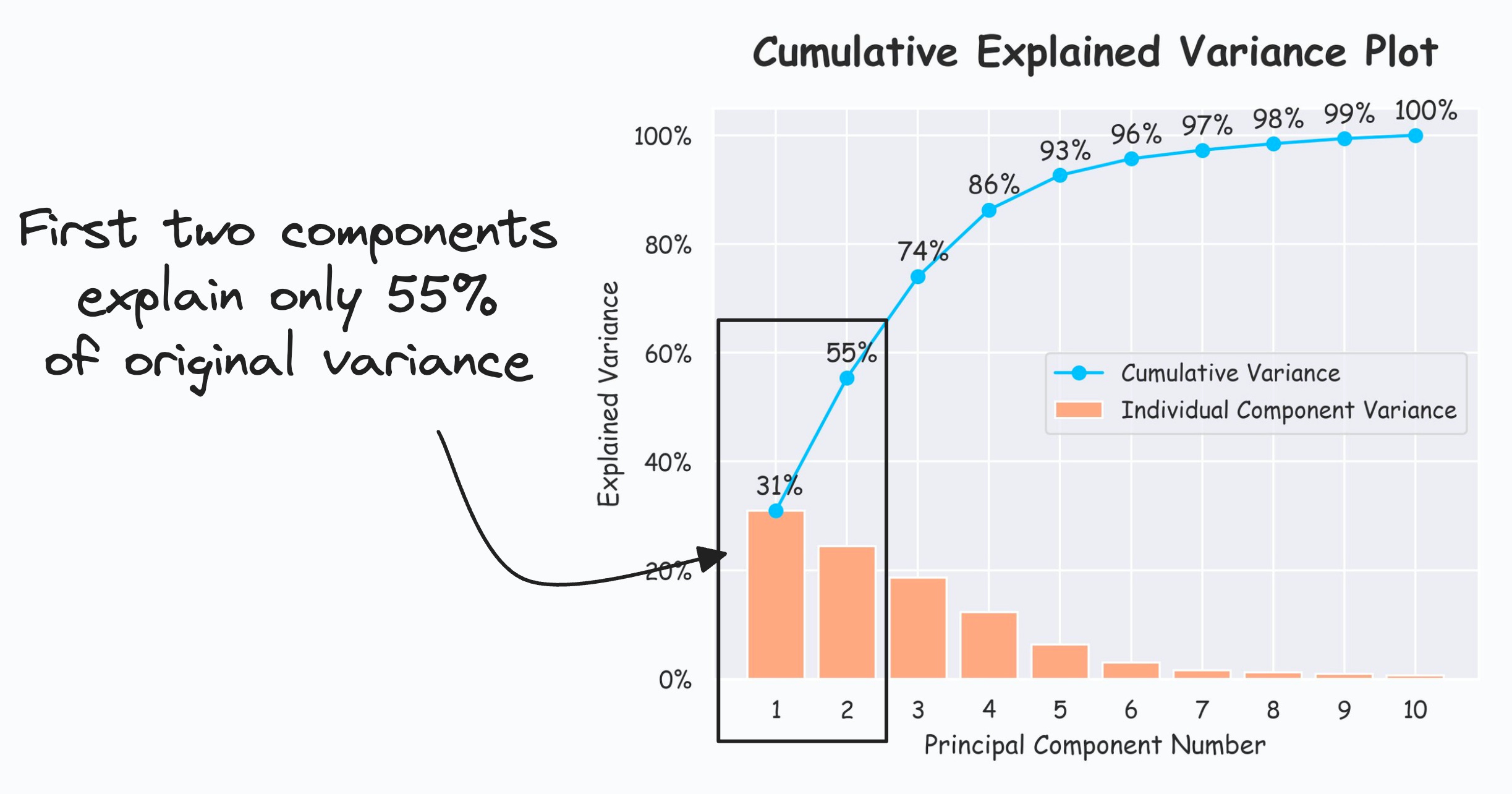
Thus, visualizing this dataset in 2D using PCA may not be a good choice because plenty of data variance is missing.
However, in the below plot, the first two components explain 90% of the original data variance.

Thus, using PCA for visualization looks like a fair thing to do.
As a takeaway, use PCA for 2D visualization only when the above plot suggests so.
If it does not, then refrain from using PCA for 2D visualization and use other techniques specifically meant for visualization, like t-SNE, UMAP, etc.
If you want to learn the entirety of t-SNE, we covered it here: Formulating and Implementing the t-SNE Algorithm From Scratch.
👉 Over to you: What are some other problems with using PCA for visualization?
In case you missed it…
I completed 500 days of writing this daily newsletter yesterday. To celebrate this, I am offering a limited-time 50% discount on full memberships.
The offer ends in the next 10 hours.
Also, I will publish an entirely beginner-friendly and extensive deep dive into vector databases tomorrow, which I wouldn’t recommend missing out on.
Join here or click the button below to join today:
Thanks!
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Congratulations on your 500 days. May you have 10,000! Your posts are small daily doses of knowledge as an antidote against my ignorance. Thank you.
Truly a work of simplicity.