
Bias-Variance Tradeoff is Incomplete!
A counterintuitive phenomenon while training ML models.

In today's newsletter:
A browser automation framework for Agents [open-source]
Bias-Variance Tradeoff is incomplete.
4 ways to run LLMs locally.
A browser automation framework for Agents [open-source]
Stagehand (open-source with 13k stars) is built to provide resilient web capabilities to Agents.
If you're building automations that need to interact with websites, fill out forms, or extract data, Stagehand delivers the perfect balance of precise control and intelligent flexibility.

It’s a middle ground between traditional automation frameworks (like Puppeteer or Selenium) and full agent-based solutions.
Also comes with an observability feature that lets you replay the session, view token usage, and more.
Double Descent vs. Bias-Variance Trade-off
It is well-known that as the number of model parameters increases, the model gradually overfits the data.
For instance, consider fitting a polynomial regression model trained on this dummy dataset below:
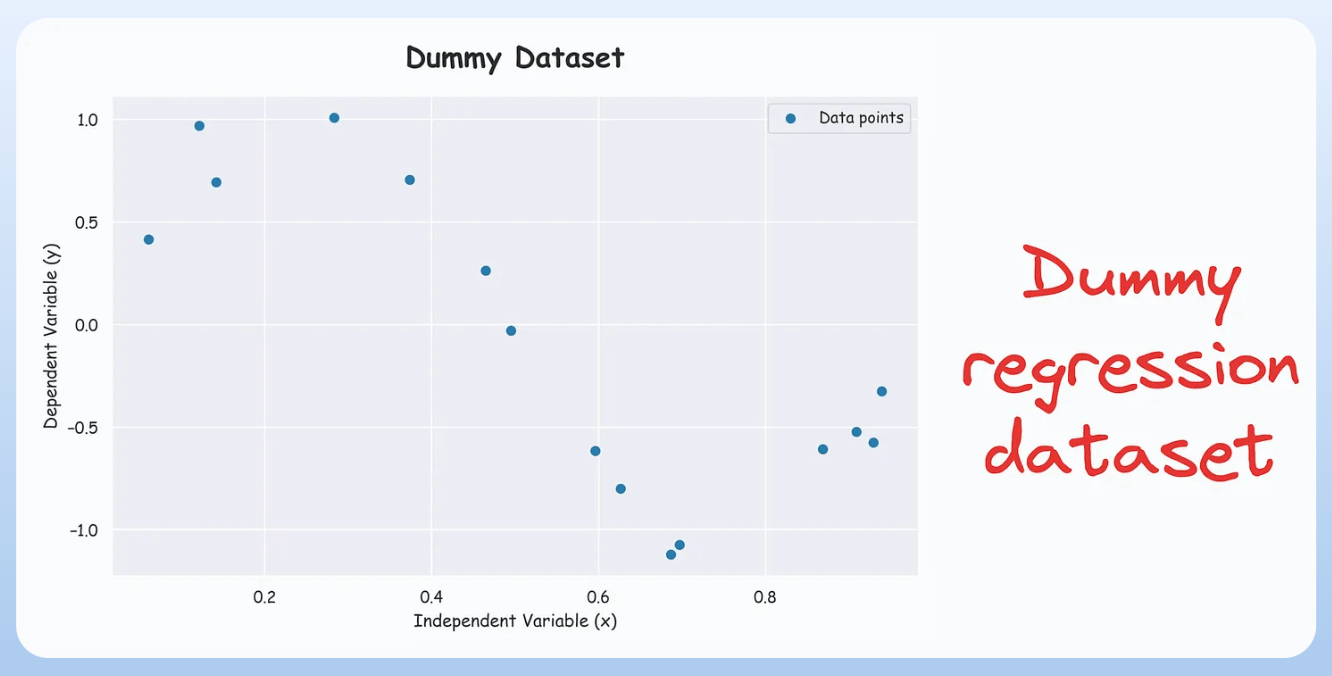
In case you don’t know, this is called a polynomial regression model:

Here, as we’ll increase the degree (m):
The training loss will get closer to zero.
The test (or validation) loss will first decrease and then increase.
This is also evident from the following loss plot:

But notice what happens when you continue increasing the degree (m):

Why does the test loss increase to a certain point but then decrease again?
What you see here is called the “double descent phenomenon,” and it is commonly observed in many deep learning models.
It depicts that increasing the model complexity beyond the point of interpolation can improve generalization performance.
And it’s hard to fathom since it challenges the traditional bias-variance trade-off:
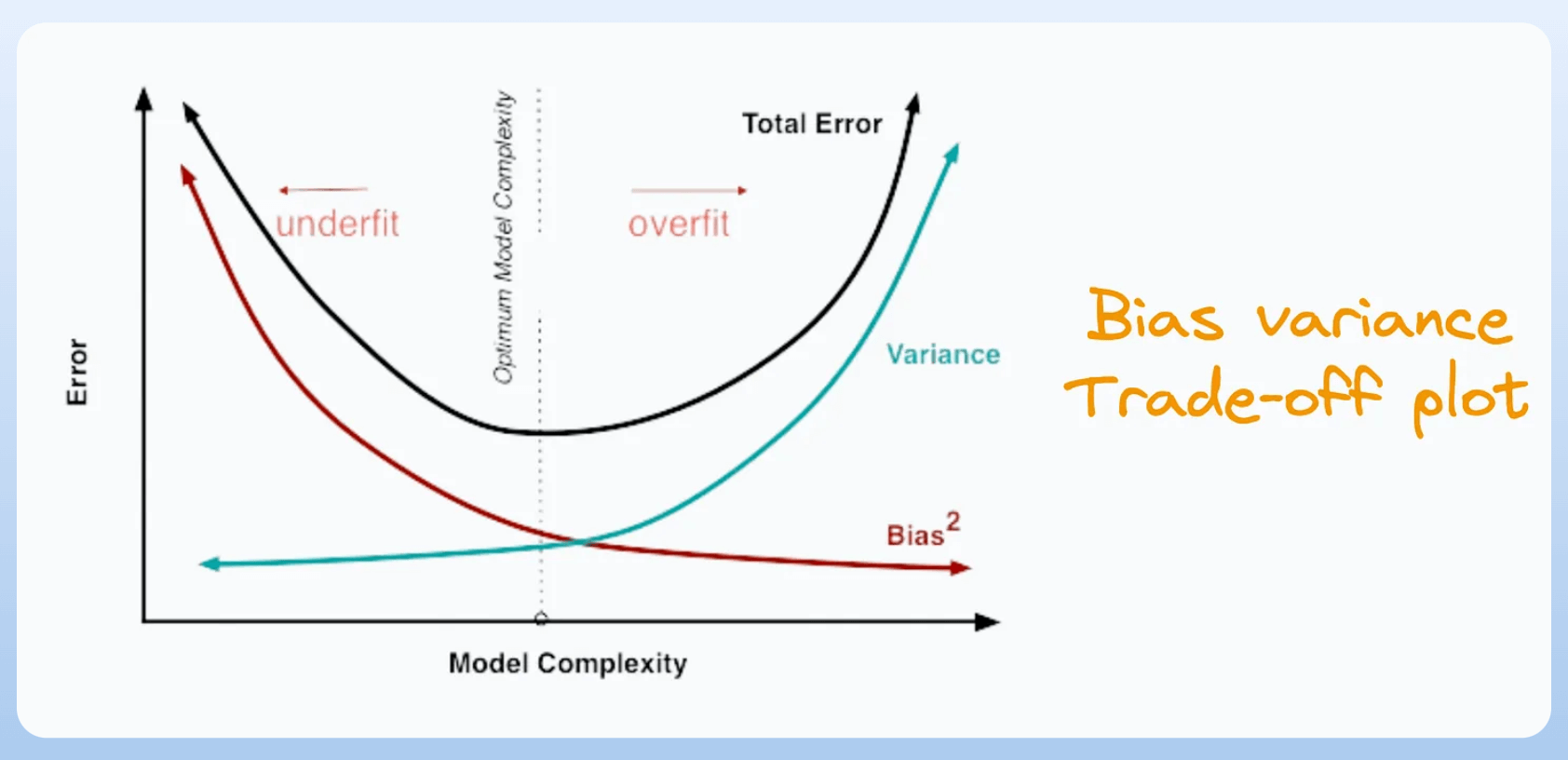
To the best of our knowledge, this is still an open question, and it isn’t entirely clear why neural networks exhibit this behavior.
Some theories suggest that the model applies an implicit regularization that allows it to precisely focus on an apt number of parameters for generalization.
You can actually try it yourself:
Create a small dummy dataset of size n.
Train a polynomial regression of degree m, starting from 1 to a value greater than n.
Plot the test loss and training loss for each m.
👉 Over to you: What do you think about the possible causes?
4 Ways to Run LLMs Locally
Being able to run LLMs also has many upsides:
Privacy since your data never leaves your machine.
Testing things locally before moving to the cloud and more.
Ollama is one of them.
Running a model through Ollama is as simple as executing this command:

To get started, install Ollama with a single command:
Done!
Now, you can download any of the supported models using these commands:

For programmatic usage, you can also install the Python package of Ollama or its integration with orchestration frameworks like Llama Index or CrewAI:

We covered there more ways here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.