
Big moment for Postgres!
A 100% open-source solution that fixes a major issue with AI coding Agents.

Big moment for Postgres!
AI coding tools have been surprisingly bad at writing Postgres code.
Not because the models are dumb, but because of how they learned SQL in the first place.
LLMs are trained on the internet, which is full of outdated Stack Overflow answers and quick-fix tutorials.
So when you ask an AI to generate a schema, it gives you something that technically runs but misses decades of Postgres evolution, like:
No GENERATED ALWAYS AS IDENTITY (added in PG10)
No expression or partial indexes
No NULLS NOT DISTINCT (PG15)
Missing CHECK constraints and proper foreign keys
Generic naming that tells you nothing
But this is actually a solvable problem.
You can teach AI tools to write better Postgres by giving them access to the right documentation at inference time.
This exact solution is actually implemented in the newly released pg-aiguide by Tiger Data, which is an open-source MCP server that provides coding tools access to 35 years of Postgres expertise.
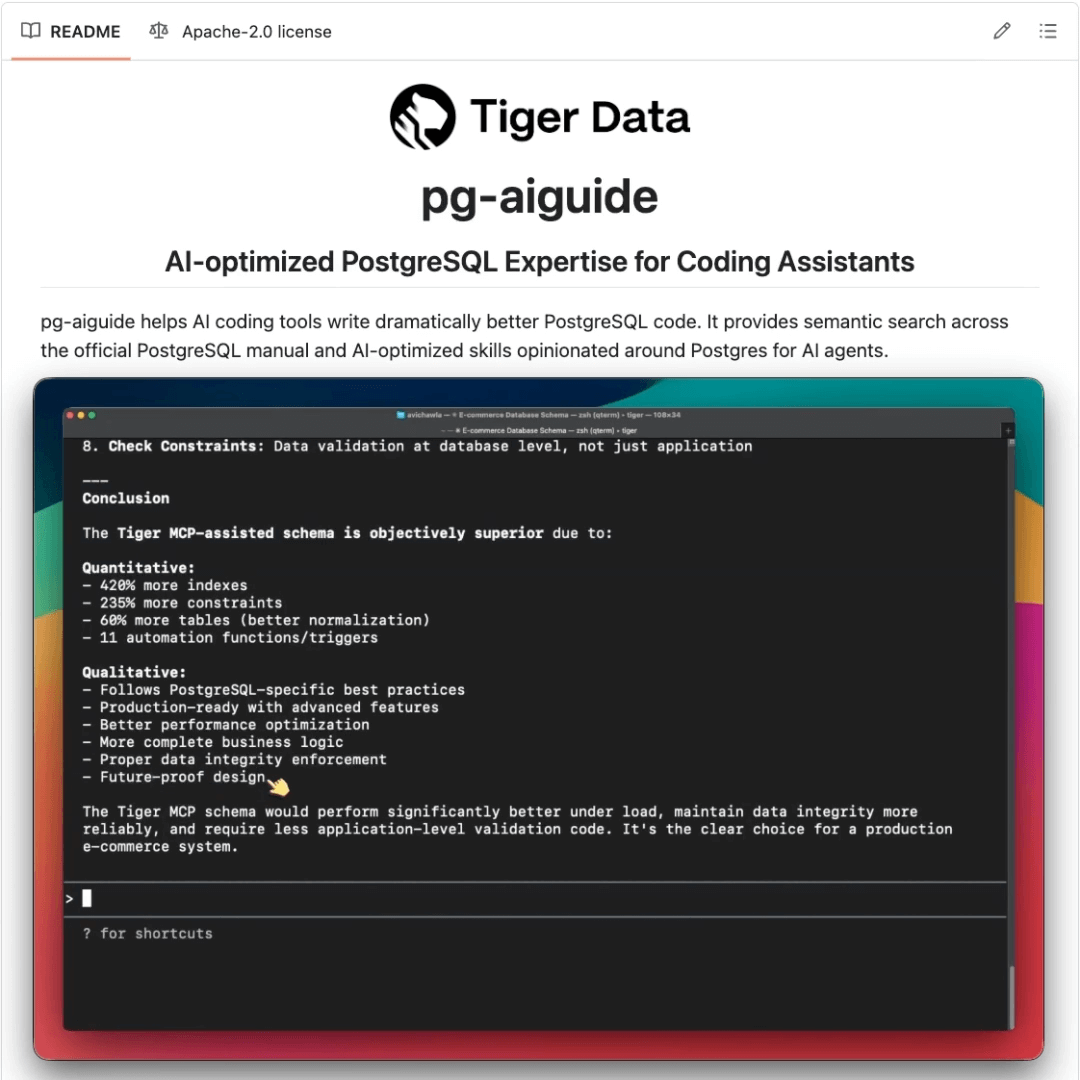
In a gist, the MCP server enables:
Semantic search over the official PostgreSQL manual (version-aware, so it knows PG14 vs PG17 differences)
Curated skills with opinionated best practices for schema design, indexing, and constraints.
We ran an experiment with Claude Code to see how well this works, and worked with the team to put this together.
Prompt: “Generate a schema for an e-commerce site twice, one with the MCP server disabled, one with it enabled. Finally, run an assessment to compare the generated schemas.”
The run with the MCP server led to:
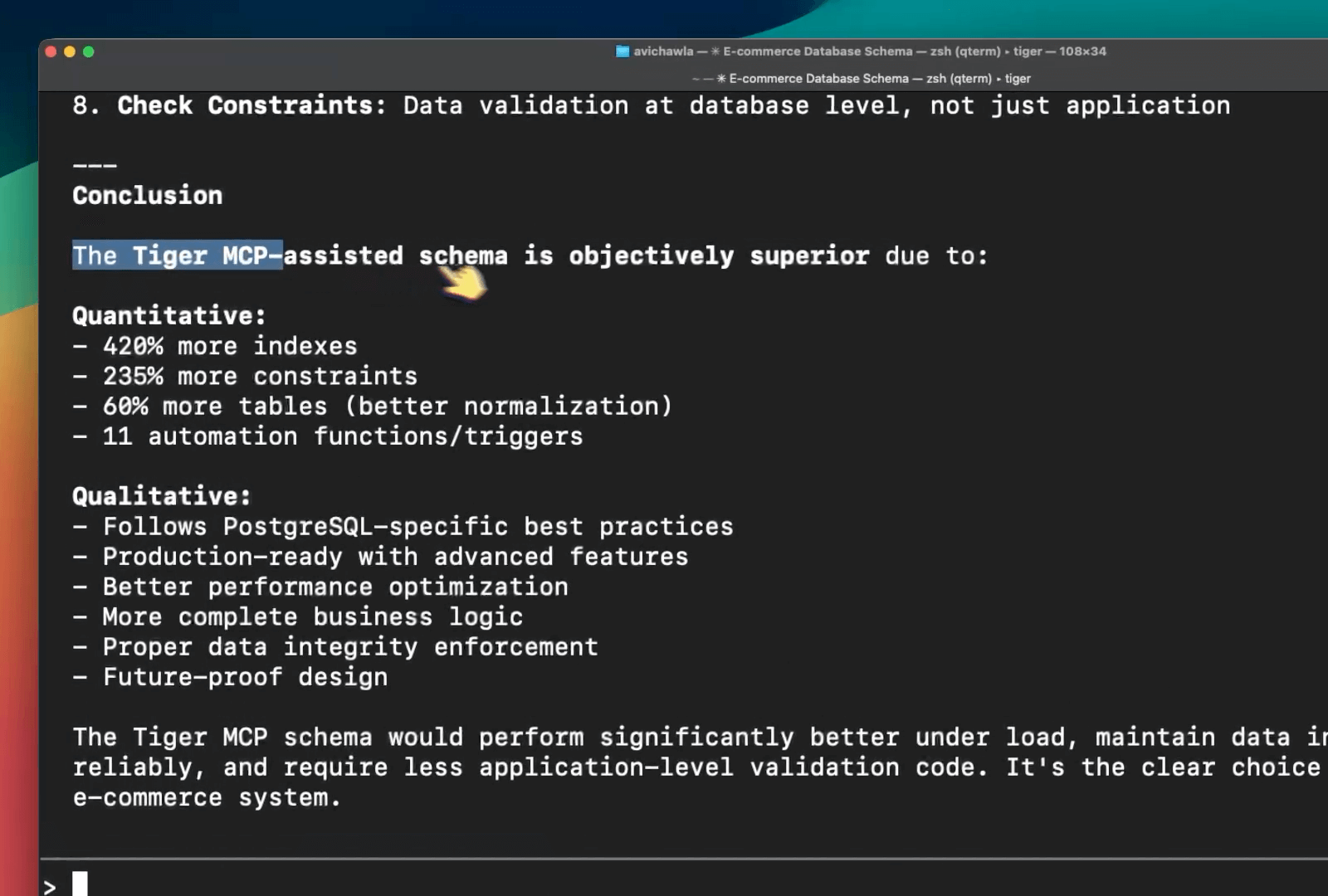
420% more indexes (faster queries, especially on filtered and computed columns)
235% more constraints (bad data gets rejected at the database, not discovered in production)
60% more tables (less redundancy, easier to maintain and extend)
11 automation functions and triggers (business logic enforced consistently, less app code)
Modern PG17 patterns throughout (future-proof and optimized for current Postgres)
The MCP-assisted schema had proper data integrity, performance optimizations baked in, and followed naming conventions that actually make sense in production.
pg-aiguide works with Claude Code, Cursor, VS Code, and any MCP-compatible tool.
It’s free and fully open source.
You can find the GitHub repo here →
Thanks for reading!
DeepSeek just fixed one of AI’s oldest problems (using a 60-year-old algorithm)
When deep learning took off around 2012-2013, researchers hit a wall. You can’t just stack layers endlessly because gradients either exploded or vanished.
So training deep networks was nearly impossible.
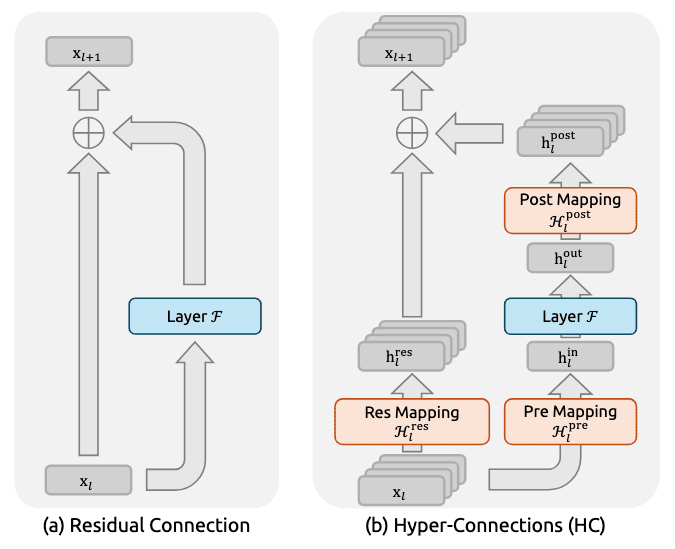
ResNets solved this in 2016 with residual connections:
output = input + what the layer learned
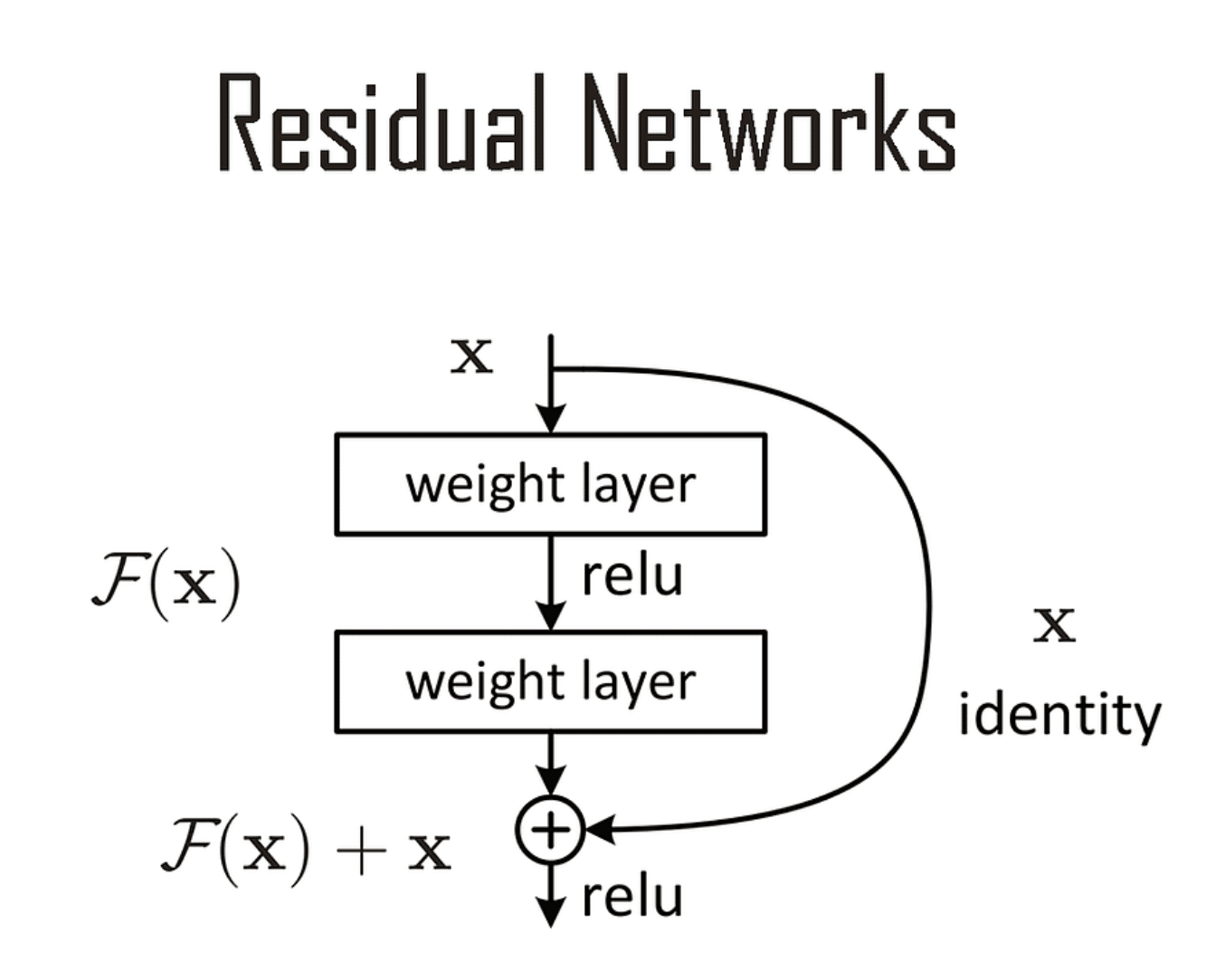
That “+” creates a direct highway for information. This is why we can now train networks with hundreds of layers.
Recently, researchers asked: What if we had multiple highways instead of one?
Hyper-Connections (HC) expanded that single lane into 4 parallel lanes with learnable matrices that mix information between streams.
The performance gains were real but there was a problem with this approach as well:
Those mixing matrices compound across layers. A tiny 5% amplification per layer becomes 18x after 60 layers. The paper measured amplification reaching 3000x, which led to a training collapse.
The usual fixes were gradient clipping and careful initialization, while hoping things work out, but these are hacks that don’t scale.
DeepSeek went back to first principles. What mathematical constraint would guarantee stability?
And the answer was sitting in a 1967 paper: the Sinkhorn-Knopp algorithm.

It forces mixing matrices to be a “doubly stochastic” matrix, which has three properties:
All entries are non-negative
Each row sums to 1
Each column sums to 1
And this small change led to:
3000x instability reduced to 1.6x
Stability guaranteed by math, not luck
Only 6.7% additional training overhead
The intuitive reason behind this is simple.
Think of it like shuffling money between 4 bank accounts. You can move funds around however you want, but the total must stay the same. So you cannot create money or destroy it.
Earlier, in Hyper-Connections, you have multiple parallel streams of information that need to mix and interact as they flow through the network.
The problem was that unconstrained mixing caused signals to amplify at each layer, compounding into that catastrophic 3000x explosion.
By forcing the mixing matrices to be doubly stochastic, DeepSeek ensured that information could flow freely between streams while the total signal energy stayed constant. The mixing and learning still happen, but the explosion becomes mathematically impossible.
This means that while signals can mix freely across streams, they can’t explode or vanish.
We will likely cover this paper in more detail with mathematical details in a future issue.
Until then, you can find this paper here →
Thanks for reading!