
Breathing KMeans: A Better and Faster Alternative to KMeans
Addressing limitations of KMeans.


The performance of KMeans is entirely dependent on the centroid initialization step. Thus, obtaining inaccurate clusters is highly likely.
While KMeans++ offers smarter centroid initialization, it does not always guarantee accurate convergence (read how KMeans++ works in my previous post). This is especially true when the number of clusters is high. Here, repeating the algorithm may help. But it introduces an unnecessary overhead in run-time.
Instead, Breathing KMeans is a better alternative here. Here’s how it works:
Step 1: Initialise
kcentroids and run KMeans without repeating. In other words, don’t re-run it with different initializations. Just run it once.Step 2 — Breathe in step: Add
mnew centroids and run KMeans with (k+m) centroids without repeating.Step 3 — Breathe out step: Remove
mcentroids from existing (k+m) centroids. Run KMeans with the remainingkcentroids without repeating.Step 4: Decrease
mby1.Step 5: Repeat Steps 2 to 4 until
m=0.
Breathe in step inserts new centroids close to the centroids with the largest errors. A centroid’s error is the sum of the squared distance of points under that centroid.
Breathe out step removes centroids with low utility. A centroid’s utility is proportional to its distance from other centroids. The intuition is that if two centroids are pretty close, they are likely falling in the same cluster. Thus, both will be assigned a low utility value, as demonstrated below.

With these repeated breathing cycles, Breathing KMeans provides a faster and better solution than KMeans. In each cycle, new centroids are added at “good” locations, and centroids with low utility are removed.
In the figure below, KMeans++ produced two misplaced centroids.
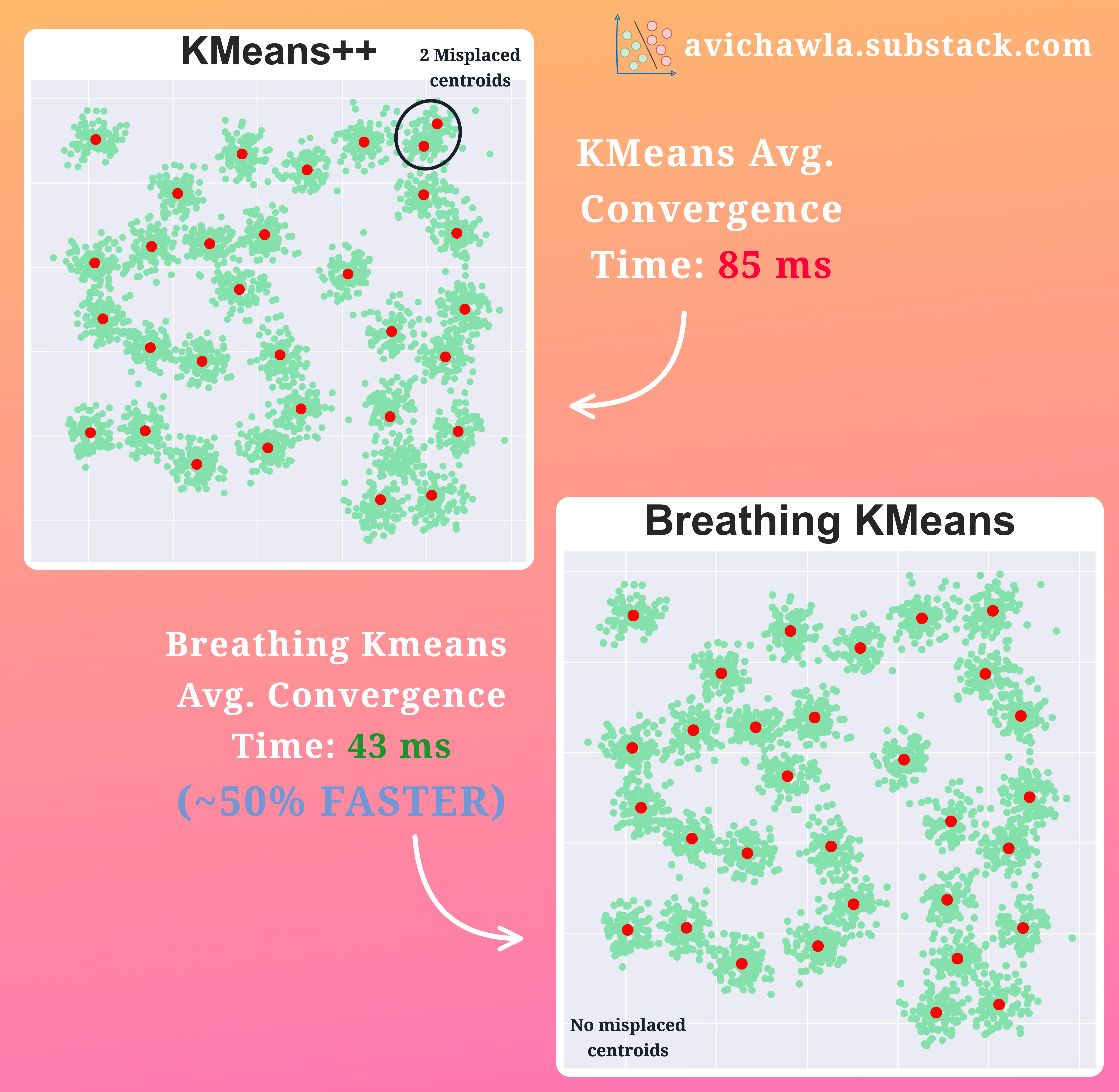
However, Breathing KMeans accurately clustered the data, with a 50% improvement in run-time.
You can use Breathing KMeans by installing its open-source library, bkmeans, as follows:
pip install bkmeansNext, import the library and run the clustering algorithm:

In fact, the BKMeans class inherits from the KMeans class of sklearn. So you can specify other parameters and use any of the other methods on the BKMeans object as needed.
More details about Breathing KMeans: GitHub | Paper.
👉 Read what others are saying about this post on LinkedIn.
👉 If you love reading this newsletter, feel free to share it with friends!
Hey there!
I frequently notice that much less than 1% of readers like these posts. While I did notice a bit of a spike when I urged you recently, the engagements are back to how they were.
Please understand that it takes quite an effort to gather insights and summarize them with visuals in one-to-two-minute daily reads.
So I would really urge you to react. It will NEVER take more than a couple of seconds. The button is located towards the bottom of this email:

This prompts Substack to recommend this newsletter to new readers and also largely increases its discoverability on this platform.
Thanks for understanding :)
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Always the best way to start the day.
A pleasant read!