
Breathing KMeans vs KMeans
Robustify KMeans with centroid addition and removal.

Since KMeans’ performance heavily depends on the centroid initialization step, it is always advised to run the algorithm multiple times with different initializations.

But this repetition introduces an unnecessary run-time overhead.
The Breathing KMeans algorithm solves this issue while providing better clustering results than KMeans.

There is also an open-source implementation of Breathing KMeans with a sklearn-like API.
To get started, install the bkmeans library and run the algorithm as follows:
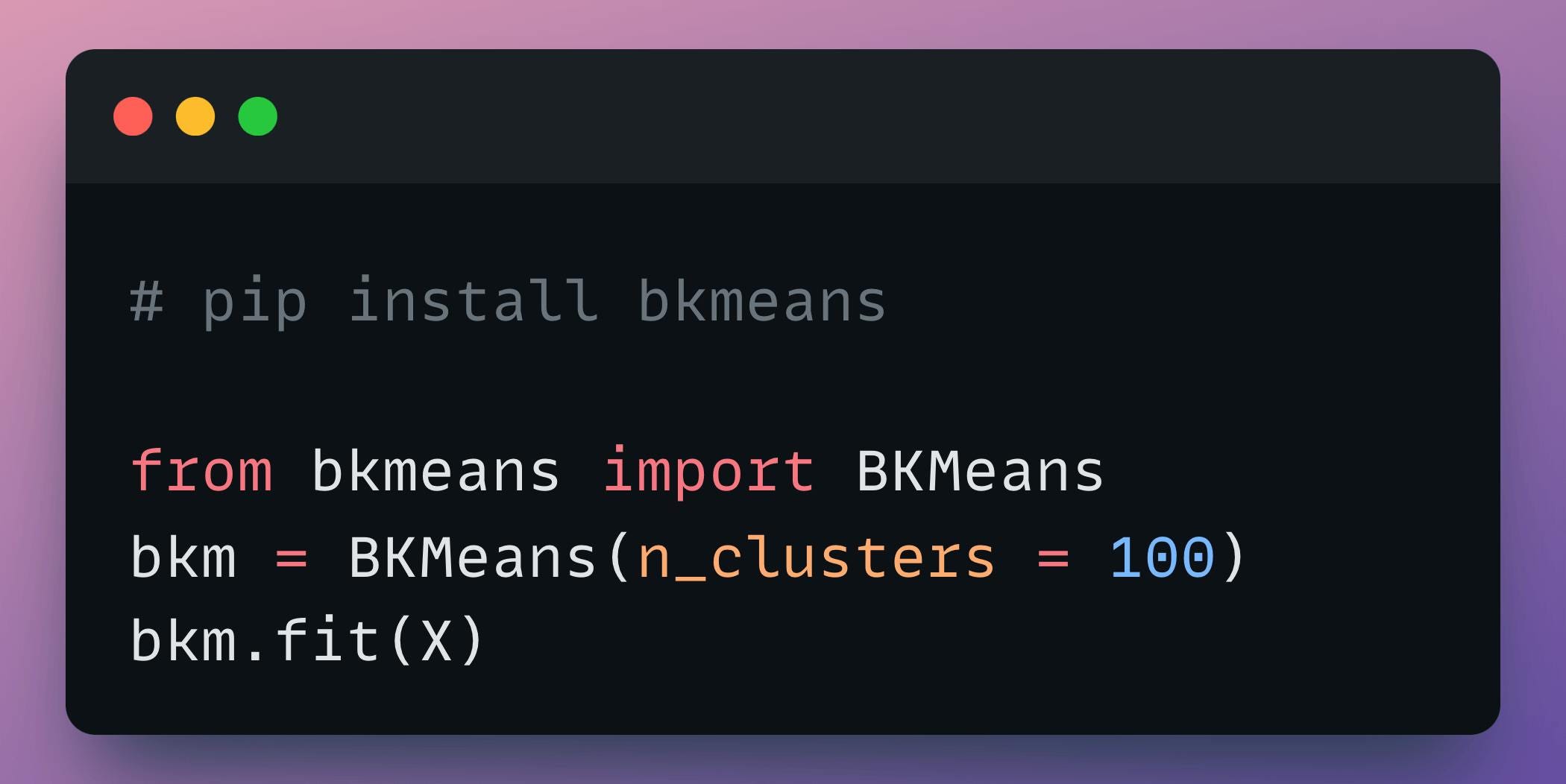
Done!
If you are curious, we have covered how Breathing KMeans works in the next section.
On a side note, data conformity is another big issue with KMeans, which makes it highly inapplicable in many data situations.
These three guides cover distribution-based and density-based clustering, which address KMeans’ limitations in specific data situations:
Step 1: Run Kmeans
First, run the usual KMeans clustering only once, i.e., without rerunning it with a different initialization.
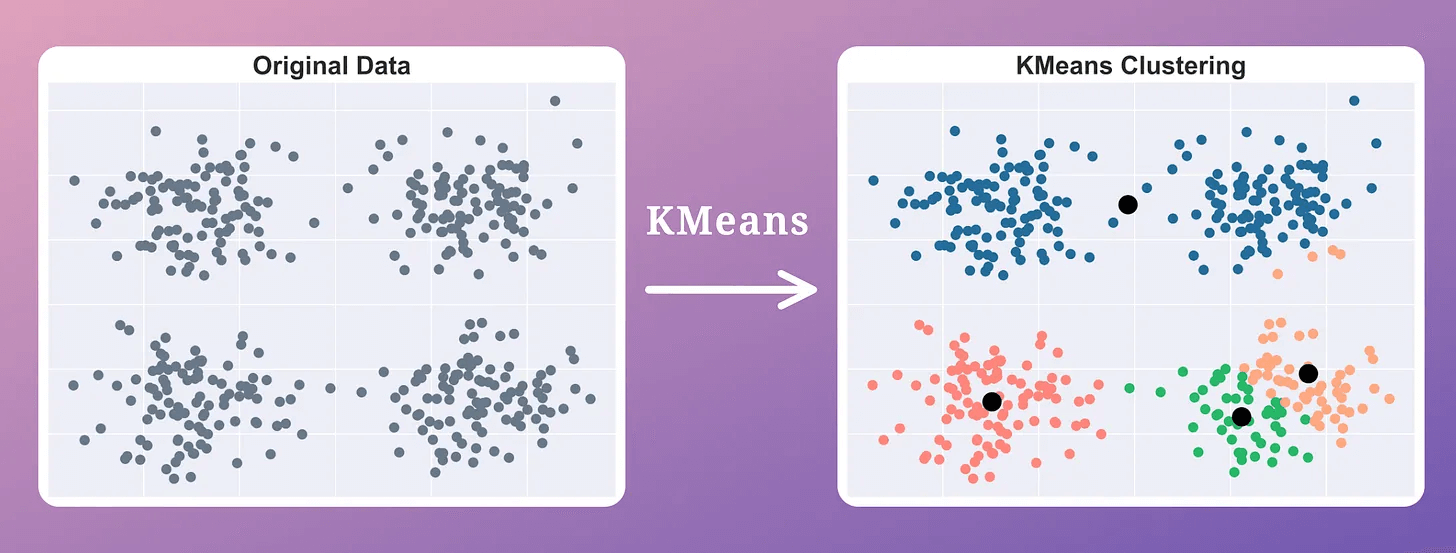
This gives us the location of “k” centroids, which may be inaccurate.
Step 2: Breathe in step
Add “m” new centroids to the “k” centroids obtained above (usually m=5).
Where to place them?
This is decided based on the error associated with the “k” existing centroids. A centroid’s error is the sum of the squared distance to its associated points.

Thus, we add “m” centroids near centroids with high error.
To understand this intuitively, consider these clustering results:
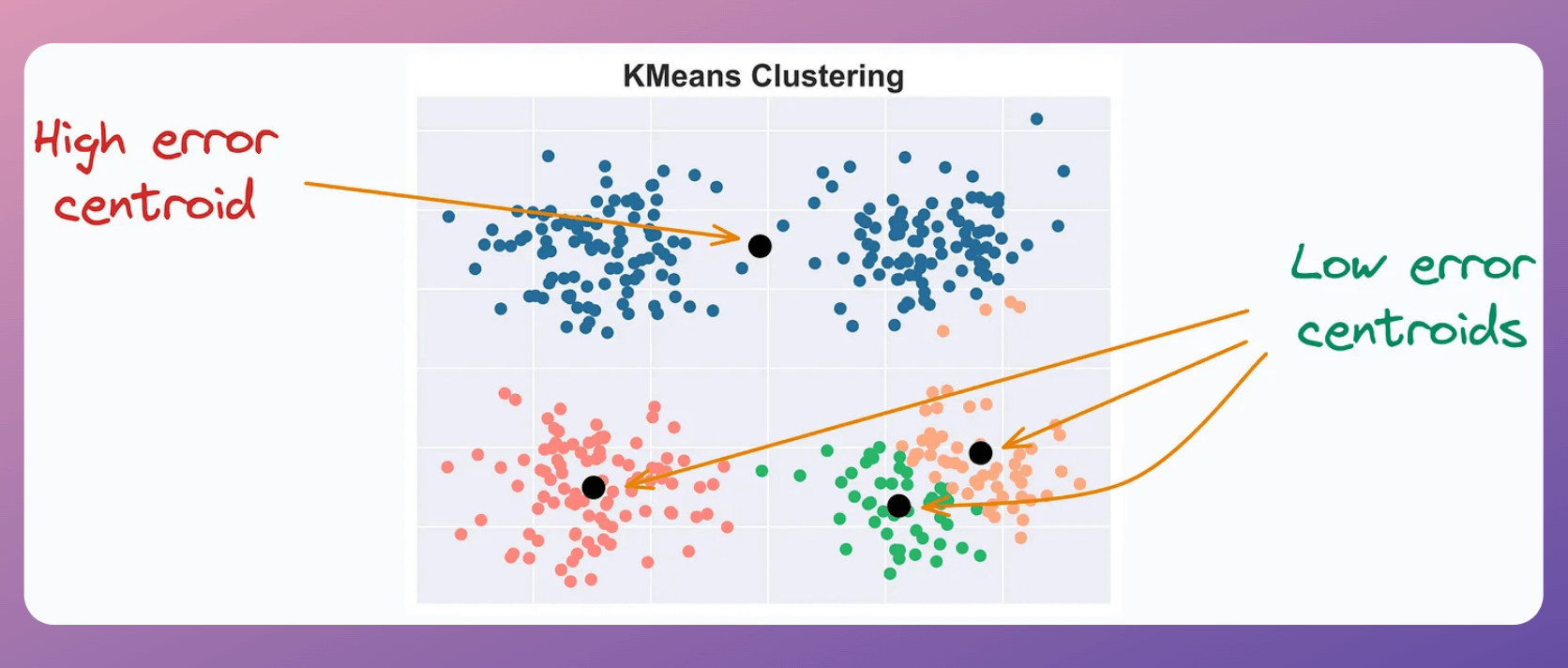
The centroid at the top has a high error.
All other centroids have relatively low error.
Intuitively speaking, if a centroid has a very high error, multiple clusters may be associated with it.
Thus, we must split this cluster by adding new centroids near centroids with high error.
This gives us a total of “k+m” centroids.
Next, rerun KMeans with “k+m” centroids only once.
Step 3: Breathe out step
Next, we should remove “m” centroids from the “k+m” centroids obtained above.
Which “m” centroids should we remove?
This is determined using the “utility” of a centroid.
A centroid’s utility is proportional to its distance from all other centroids.
The greater the distance, the more isolated it will be; hence, the more the utility.
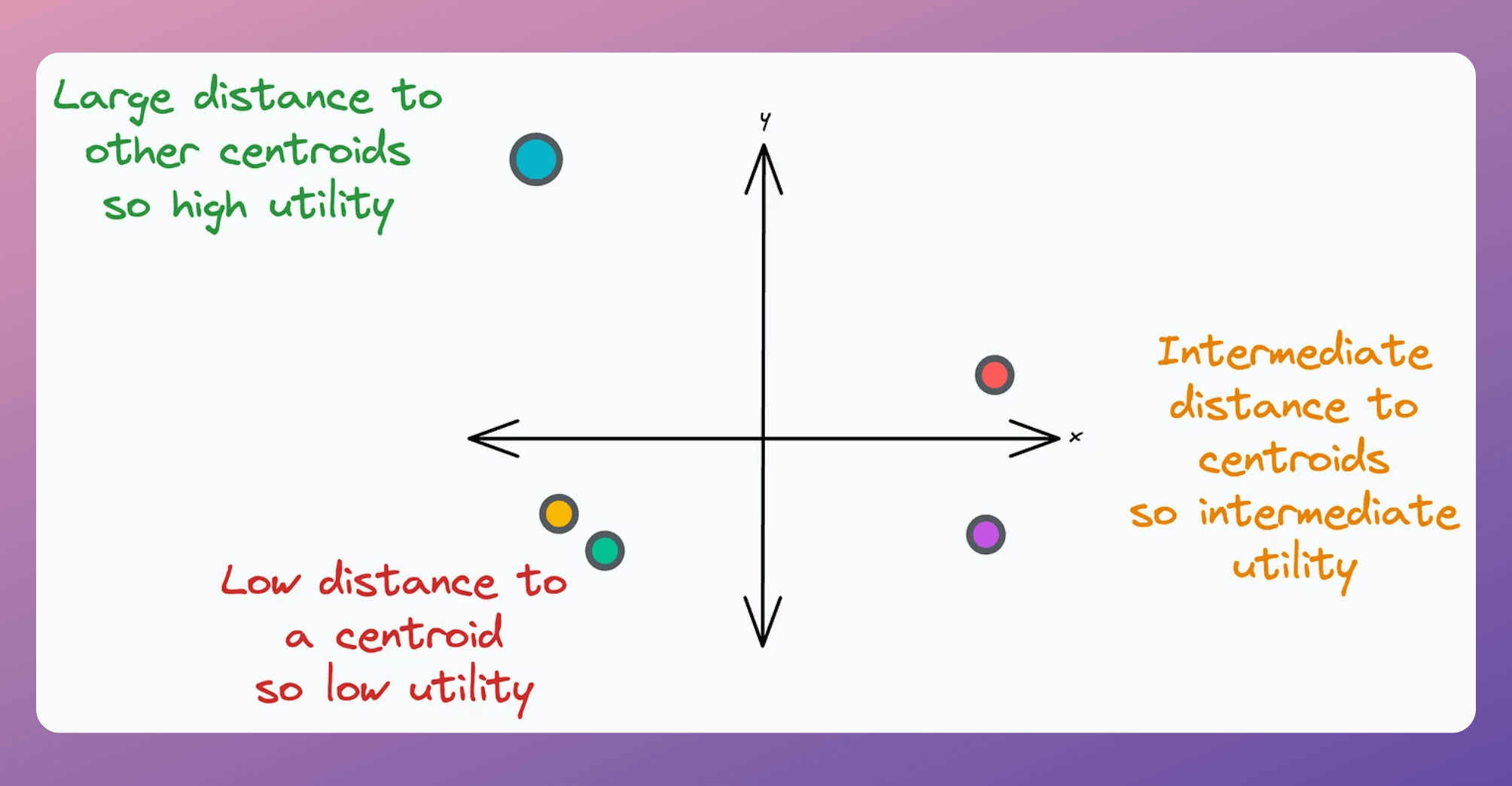
In other words, if two centroids are close, they may lie in the same cluster.
Thus, we must remove one of them, as demonstrated below (in the top right cluster):

This is repeated until all “m” low-utility centroids have been removed.
This gives back “k” centroids.
Finally, we run KMeans with these “k” centroids only once.
Step 4: Decrease m by 1.
Step 5: Repeat Steps 2 to 4 until m=0.
Done!
Why does Breathing Kmeans work?
These repeated breathing cycles (breathe-in and breathe-out steps) almost always provide a faster and better solution than standard KMeans with repetitions.
In each cycle:
New centroids are added at “good” locations. This helps in splitting clusters occupied by a single centroid.
Low-utility centroids are removed. This helps eliminate centroids that are likely in the same cluster.
As a result, it is expected to converge to the optimal solution faster.
The effectiveness of Breathing KMeans over KMeans is evident from the image below:
KMeans produced two misplaced centroids.
Breathing KMeans accurately clustered the data with a 50% run-time improvement.
Isn’t that a significant upgrade to KMeans?
That said, data conformity is another big issue with KMeans, which makes it highly inapplicable in many data situations.
These three guides cover distribution-based and density-based clustering, which address KMeans’ limitations in specific data situations:
Gaussian Mixture Models (GMMs) [derived and implemented from scratch using NumPy].
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering [with implementation].
HDBSCAN—An Algorithmic Deep Dive [with implementation].
👉 Over to you: What are some other ways to improve KMeans’ clustering and its run-time?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 115,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.