
Build a Deep Researcher That Beats OpenAI, Gemini, and Perplexity
...using a 100% open-source, self-hostable stack.

Running an AI agent means keeping it alive long enough to matter
Most agent workflows die the moment the process does.
Serverless cold starts interrupt long-running tasks. Cloud VMs require networking setup, HTTPS configuration, and infra scaffolding before anything actually runs.
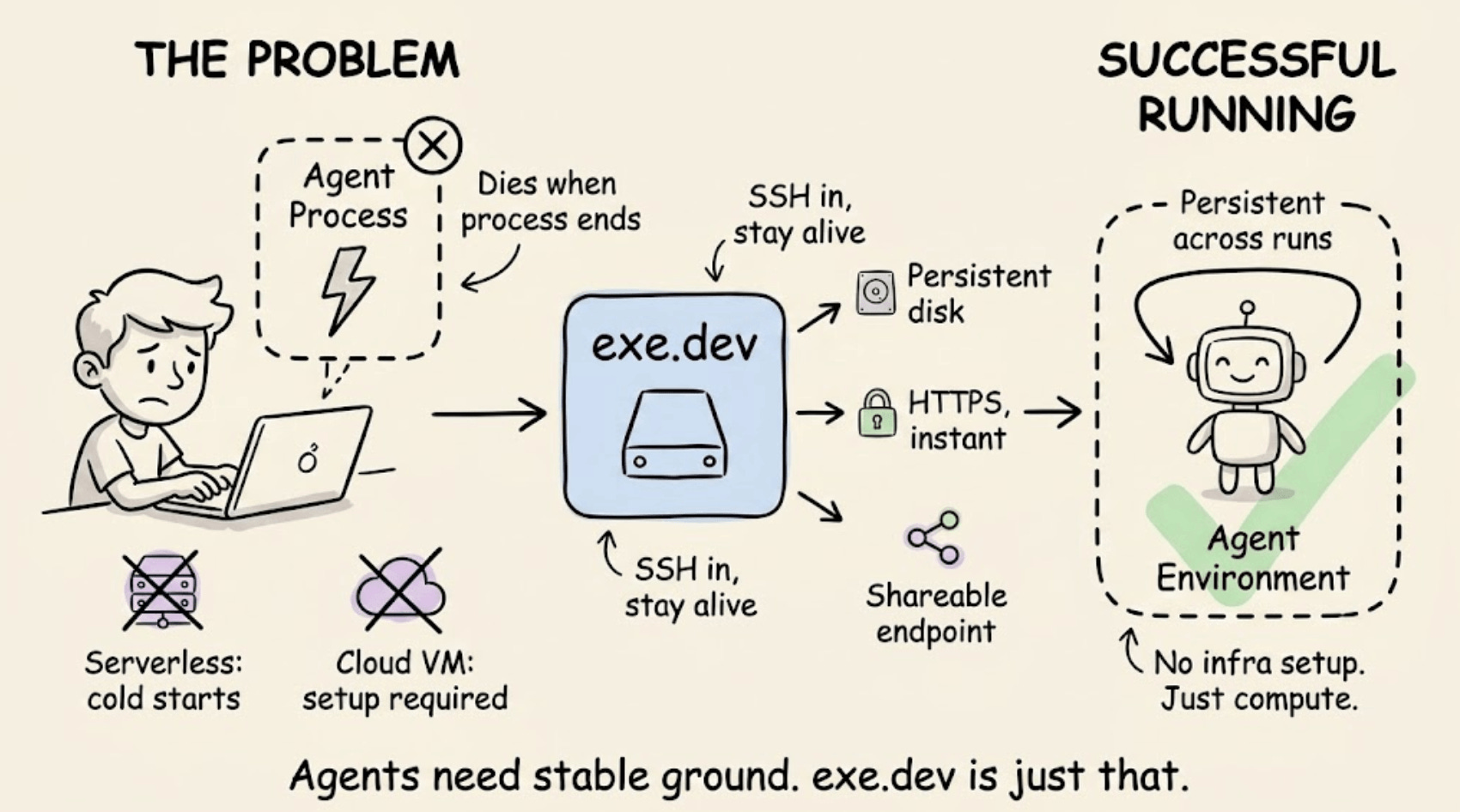
exe.dev takes a different approach. It gives developers persistent virtual machines, accessible over HTTPS immediately, with no dashboard or configuration required.
Launch a machine via SSH, and it stays alive, disk included. For agent workflows specifically, the fit is direct: agents need a stable execution environment, an addressable endpoint, and persistence across runs. exe.dev bundles all three.
You can also share a running service as easily as sharing a Google Doc, with optional built-in authentication.
Positioned between VPS and serverless, it removes the infrastructure overhead without abstracting away control.
Get started with exe.dev here→
Thanks to the team for partnering today!
Build a deep researcher that beats OpenAI, Gemini, and Perplexity
ChatGPT Deep Research, Claude, and Perplexity are all closed-source SaaS running in someone else’s cloud.
Every query and every connected internal document sits on their servers, not yours.
That’s fine for some use cases, but not all.
Today, let’s look at a fully open-source deep research stack that runs on your own infrastructure using three:
Onyx for retrieval
CrewAI for orchestration
Voxtral for voice.
Here’s the full system running end-to-end, from voice query to narrated research report:
The rest of this article breaks down how it works and walks you through building the same stack yourself. Before any of that, though, it’s worth being clear about why this is worth building at all.
Why self-hosting actually matters
Every major AI research tool is a closed cloud service. That has real consequences:
Your queries go to their servers. The questions you ask reveal what you’re working on.
Your connected data gets indexed on their infrastructure. Integration is convenient, but the index lives on their side.
Retention, logging, and audit are their call, not yours. Enterprise tiers soften this, but don’t eliminate it.
Quotas and pricing change on their timeline. The tool you depend on today can reprice or rate-limit tomorrow.
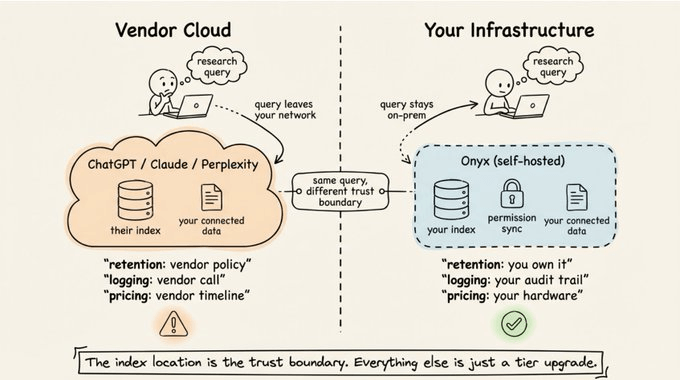
For regulated industries, teams with IP-sensitive work, or anyone working under data residency rules, that list isn’t theoretical. It’s the reason AI-assisted research still feels out of reach for a lot of serious work.
Unless you can run the whole stack yourself, with no compromise on quality.
Why existing research tools break
Most research tools do one pass. They search, collect whatever comes back, and hand it to the LLM to write something up.
That works for shallow queries. It breaks the moment you ask something that requires synthesis across sources, contradiction detection, or reasoning across multiple hops.
Here’s what that failure looks like in practice:
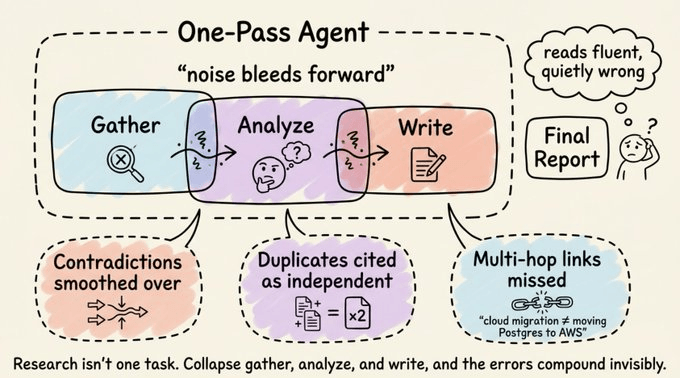
The agent finds a source and a contradicting source. It picks one and moves on. The contradiction never surfaces.
Two sources say the same thing in different words. The report cites both as independent evidence.
A critical connecting fact lives in a document that wasn’t retrieved, because keyword matching doesn’t understand that “cloud migration” and “moving our PostgreSQL cluster to AWS” are the same thing.
And they all share the same root cause: research isn’t one task.
What good deep research actually requires
Five things, regardless of tools:
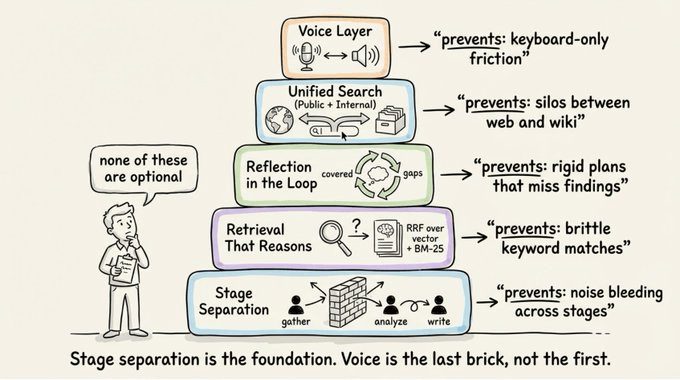
Separation of stages → Gathering, analysis, and writing should be isolated. Each stage receives only the clean output of the previous one.
Retrieval that reasons → Keyword search is brittle. Vector similarity breaks on multi-hop questions. The retrieval layer needs parallel query variants, intelligent recombination, and an LLM filtering step before synthesis. Without that filtering, hallucinations enter.
Reflection in the loop → Static plans break when findings contradict expectations. The system should pivot when something unexpected surfaces, while still tracking coverage of the original plan.
Unified search across public and internal sources → The research layer should query the open web and internal knowledge bases in one pipeline, with permissions enforced per-document. Whether indexing runs on your infrastructure or a vendor’s determines who owns the data.
A voice layer → Voice input for queries is faster than typing, especially for complex or exploratory questions. Audio output for reports makes long-form results consumable without reading through pages of text.
Onyx as the open-source retrieval layer
Onyx is an open-source AI platform built around these principles. It gives any model RAG, web search, code execution, deep research, and custom agents out of the box.
Fully self-hostable, so your data never leaves your infrastructure.

Moreover, Onyx is ranked #1 (ahead of OpenAI Deep Research, Gemini 2.5 Pro, and Perplexity Deep Research) on DeepResearch Bench, an independent academic benchmark covering 100 PhD-level research tasks across 22 fields, evaluated on report quality and citation accuracy.
Here’s how the Onyx deep research translates to architecture.
Instead of running a single retrieval loop, it separates the workflow into three distinct phases:
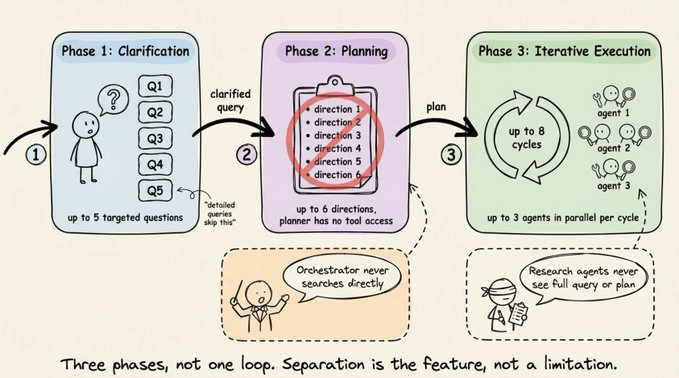
Phase 1: Clarification → For short or ambiguous queries, the system generates up to 5 targeted follow-up questions to narrow scope. Detailed queries skip this step automatically.
Phase 2: Planning → The query is decomposed into up to 6 exploration directions. The planner has no tool access, so it produces a research plan, not answers. This is a deliberate constraint.
Phase 3: Iterative execution → An orchestrator and research agents alternate for up to 8 cycles, each dispatching up to 3 agents in parallel.
Design-wise:
The orchestrator never searches directly.
Research agents never see the full query or plan.
This forces self-contained task briefs per agent and prevents context from leaking across stages.
Adaptive strategy
Onyx explores alternative paths from the original plan based on what it finds. Between every dispatch, a mandatory reflection step produces structured output:
What’s covered
What gaps remain
What new directions emerged
Whether more cycles will yield new info
This runs every time, so the result behaves like a researcher, not a retrieval engine.
The 6-stage retrieval pipeline
Each agent runs through this full pipeline before the LLM synthesizes anything:
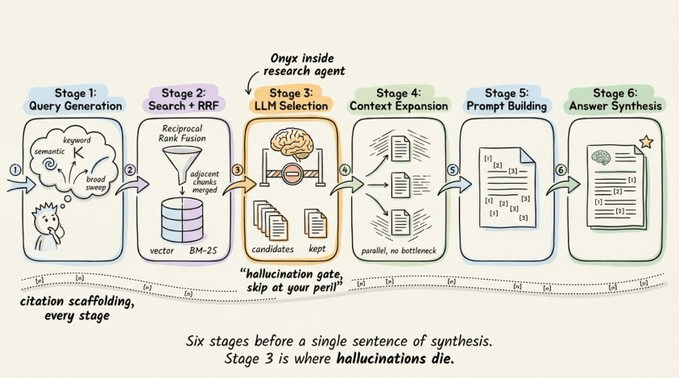
Query generation → The original query is expanded into parallel variants: semantic rephrasings, keyword alternatives, and broader searches. Multi-part questions are split automatically.
Search and recombination → Results are retrieved from a hybrid index (vector + BM25), combined via Reciprocal Rank Fusion, and adjacent chunks are merged.
LLM selection → The LLM reviews all retrieved chunks and keeps only the relevant ones. Skipping this step is where hallucinations typically enter the pipeline.
Context expansion → For each selected document, the LLM reads surrounding chunks to determine how much additional context is needed. This runs in parallel across documents.
Prompt building → Selected sections are assembled along with citations and chat history into a single prompt.
Answer synthesis → The LLM generates a grounded answer with inline citations linking back to source documents.
Onyx connects to 40+ enterprise data sources like Slack, Confluence, Jira, GitHub, Salesforce, Google Drive, SharePoint, Notion, Zendesk, HubSpot, Gong, and more.

The difference here from proprietary tools isn’t whether it can connect. It’s where the indexing happens. Onyx pre-indexes everything continuously on your own infrastructure, syncing content, metadata, and permissions in near real time.
This provides:
One query spans the open web and every internal source at once.
Users only see results from documents they’re authorised to view.
Permissions sync automatically from each source.
No internal data leaves your network to be indexed or stored by a vendor.
Finally, regarding citations:
Agents cite inline as they write intermediate reports.
Citations from parallel agents get merged and renumbered into one unified set.
Every final claim traces back to a specific source document.
CrewAI: the orchestration layer
Onyx handles retrieval. CrewAI handles coordination.
The default pattern most developers reach for is one agent with three sequential tasks sharing a growing context window:
The writer starts before the analyst finishes.
Raw search noise bleeds into the final report.
Source material gets reinterpreted twice before output.
CrewAI solves this with three primitives:
Flows wire independent Crews together, each receiving only clean output from the stage before. No accumulated context.
Skills inject domain-specific instructions into an agent’s prompt at runtime via SKILL.md. Instruction at the point of action.
MCP Integration attaches MCP servers directly to an agent via the mcps field. No adapter, no context manager.
Onyx connects in one declaration:
from crewai import Agent
researcher_agent = Agent(
role="Senior Research Analyst",
goal="Gather information on research query with source URLs",
backstory="You are a disciplined analyst. Record every source URL.",
mcps=[
f"{ONYX_MCP_URL}?token={ONYX_TOKEN}" # also runs locally without a token
]
) The Researcher agent gets three tools instantly without any tool wiring:
Search the knowledge base
Search the web
Fetch full page content from any URL
Voxtral: the voice layer
Research workflows typically bottleneck at the keyboard, especially for exploratory queries that are easier to articulate verbally than to type out.
Voxtral is Mistral’s native audio model family, designed for both speech understanding and generation within the same architecture.
Transcription handles accents, background noise, and domain-specific vocabulary well. Generation produces natural-sounding speech rather than robotic TTS output.
This adds two things to the research pipeline:
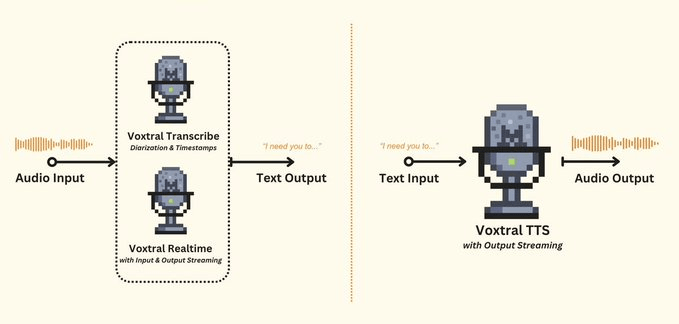
Voice input → A spoken question is transcribed and fed directly into the research pipeline, removing the typing step entirely.
Report narration → The full Markdown report is read back as expressive audio. For long reports, listening is more practical than reading through pages on screen.
Putting it together
The full flow works like this:
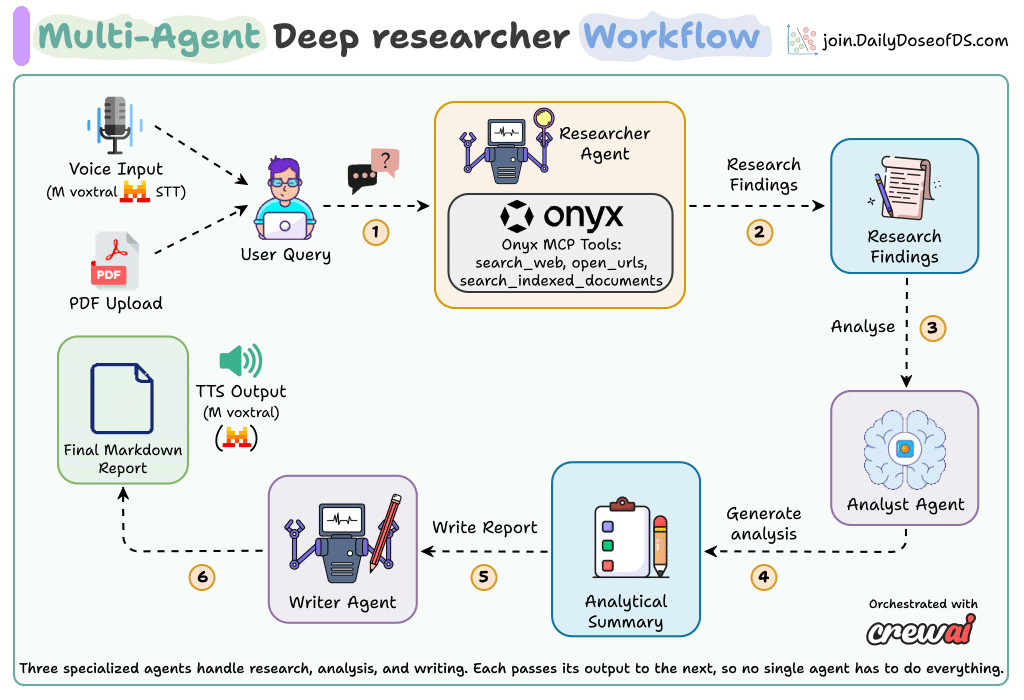
A research query comes in as typed text, spoken audio, or an uploaded PDF.
The Researcher Agent searches the web and internal documents via Onyx MCP.
The Analyst Agent deduplicates findings, flags contradictions, and groups them into themes.
The Report Writer Agent produces a structured Markdown report with citations.
The report can be narrated back via Voxtral TTS.
The natural first design is a single Crew with three sequential tasks. This doesn’t work well in practice.
Shared context across stages degrades ground truth. Onyx refers to this as “deep frying” where facts get reinterpreted, contradictions get smoothed over, and source material becomes unrecognizable by the time the Writer sees it.
This system uses a CrewAI Flow instead, with three separate Crews where each one receives only the clean output from the previous stage.
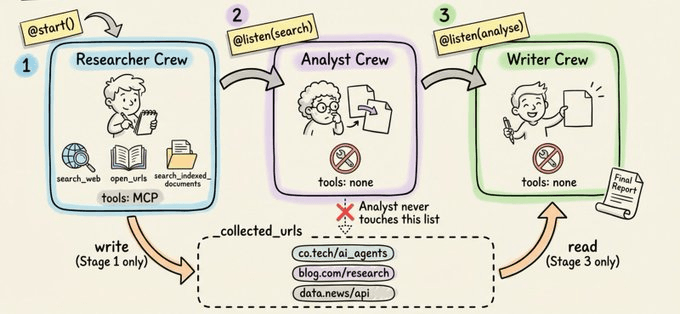
Researcher Agent → Connects to Onyx via CrewAI’s MCP integration. It runs web searches, reads full URLs, and searches uploaded PDFs. Every finding carries a citation back to its source.
Analyst Agent → Takes the raw findings and deduplicates overlapping facts, merges sources that say the same thing, flags explicit contradictions, and groups everything into coherent themes. The output is a structured summary, not a pile of search results.
Report Writer Agent → Turns the analyst’s summary into a citation-backed Markdown report. It’s equipped with a CrewAI Skill (SKILL.md) that gets injected at generation time to enforce consistent structure.
deep-research-report/
├── SKILL.md # Formatting rules, evidence standards, structure
├── scripts/ # Optional
└── references/ # OptionalSKILL.md uses YAML front matter and a Markdown body:
---
name: deep-research-report
description: >
Guidelines for writing high-quality, publication-ready deep research reports.
Covers structure, tone, evidence standards, and formatting rules.
metadata:
author: deep-research-agent
version: "1.0"
---
Instructions for the agent go here.
This markdown is injected into the agent's prompt when the skill is activated.Here's a successful execution of the full flow:
You can find all the code for the project in this Lightning Studio →
Why build?
The point here isn’t that open-source has caught up to closed-source research tools.
It’s that Onyx runs deep research on infrastructure you can inspect, self-host, and modify. Combined with CrewAI’s enforced stage separation and Voxtral’s native speech layer, the resulting stack covers three things that closed-source alternatives fundamentally cannot offer together:
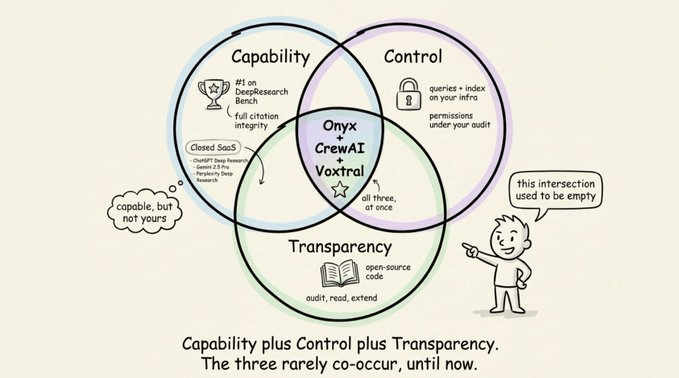
Research quality that’s competitive with commercial tools, with full citation integrity maintained across stages.
Complete data sovereignty, where every query and internal document stays on your infrastructure.
Full transparency into the codebase, which you can read, audit, and extend.
If data sovereignty has been the reason your team hasn’t adopted AI-powered research, that constraint no longer has to exist.
Thanks for reading!