
Build a Reasoning Model Like DeepSeek-R1
100% locally.

A web browser for your AI
Browserbase powers web browsing capabilities for AI agents and applications.
If you’re building automations that need to interact with websites, fill out forms, or replicate users’ actions, Browserbase manages that infrastructure so you don’t have to maintain your fleet of headless browsers.

With the excitement of Open AI's new Computer Using Agent API, Browserbase has built an open-source version of this toolkit—CUA Browser, for you to try out yourself.
Supercharge your CUA with Browserbase's reliable, scalable browser infrastructure, and sign up for free.
Thanks to Browserbase for partnering on today’s issue.
Build a Reasoning Model Like DeepSeek-R1
If you have used DeepSeek-R1 (or any other reasoning model), you must have seen that they autonomously allocate thinking time before producing a response.
Today, let’s learn how to embed reasoning capabilities into any LLM.
We'll train our own reasoning model like DeepSeek-R1 (code is provided later in the issue).

To do this, we'll use:
UnslothAI for efficient fine-tuning.
Llama 3.1-8B as the LLM to add reasoning capabilities to.
Let’s implement this.
1) Load the model
We start by loading the Llama 3.1-8B model and the tokenizer using Unsloth.

You can use any other open-weight LLM here.
2) Define LoRA config
We must use efficient techniques like LoRA to avoid fine-tuning the entire model weights.
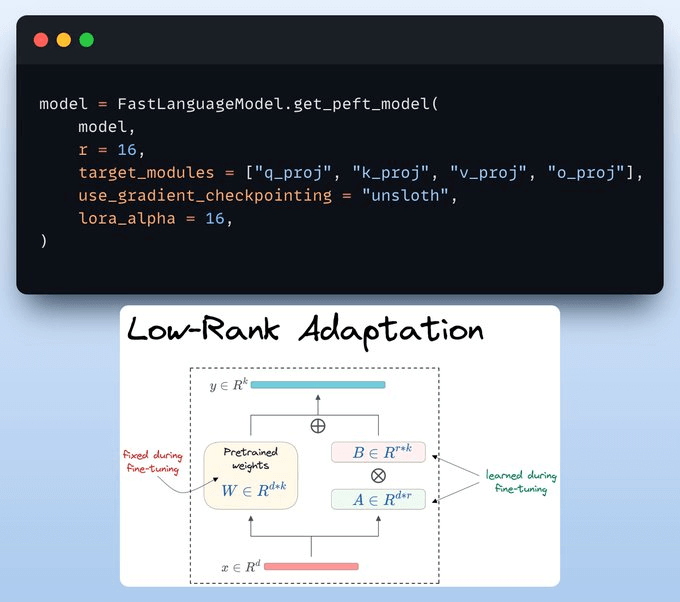
In this code, we use Unsloth's PEFT by specifying:
The model
LoRA low-rank (r)
Modules for fine-tuning
and a few more parameters.
3) Create the dataset
We load GSM8K (a math word problem dataset) and format prompts for reasoning.
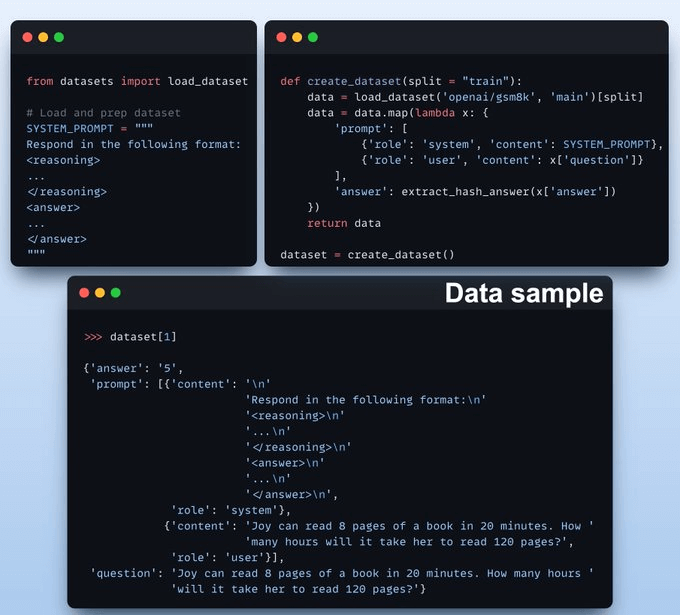
Each sample includes:
A system prompt enforcing structured reasoning
A question from the dataset
The answer in the required format
4) Define reward functions
To guide fine-tuning, we define reward functions for:

Correctness of answers
Integer formatting
Strict/soft format adherence
XML structure compliance
These help reinforce structured reasoning!
5) Use GRPO
We employ GRPO, an RL method, to enhance reasoning. GRPO improves model performance without the need for a separate value function used in PPO.
If you don’t understand GRPO or PPO, don’t worry. We shall cover them soon. For now, just understand that these are reinforcement learning algorithms used to optimize decision-making policies (LLMs, in this case).
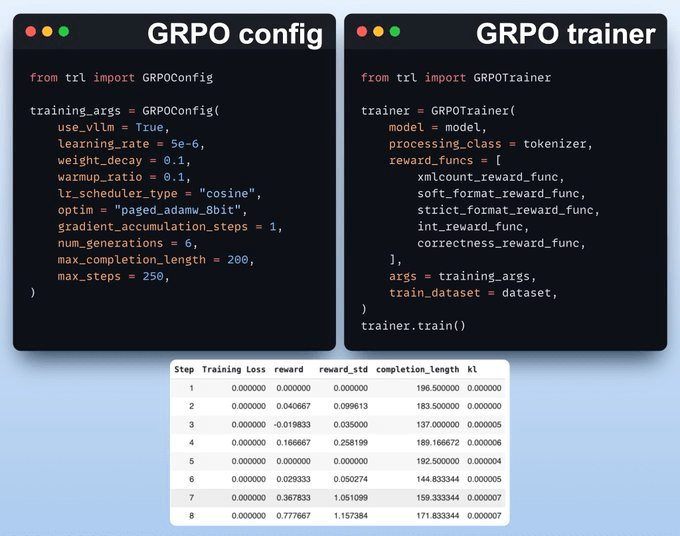
The setup includes:
Training config (LR, optimizer, steps)
Reward functions
Trainer execution
Done!
Comparison
Before fine-tuning, Llama 3 struggles with numerical reasoning and provides incorrect answers.
After applying GRPO, the model not only gives the correct answer but also explains its reasoning.

In this case, of course, it is a little flawed—”9 is greater than 11” when it may have wanted to say “90 is greater than 11” but you also need to consider that GRPO takes time, and I only ran the training script for 2 hours.
So this is expected and it will improve with subsequent training.
If you don’t know about LLM fine-tuning and want to learn, here’s some further reading:
We implemented LoRA for fine-tuning LLMs from scratch here →
LoRA has several efficient variants. We covered them here →
You can find the code for today’s issue in our AI Engineering Hub repo here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.