
Build Agents That Never Forget
...long-term memory for your AI

Most AI agents can answer questions well, but forget everything the moment the conversation ends.
Here’s the problem:
When you build an agent, it processes each message independently. The model sees your query, generates a response, and moves on.
Within a single conversation, this works fine - the agent stays coherent, follows context, and delivers helpful answers.
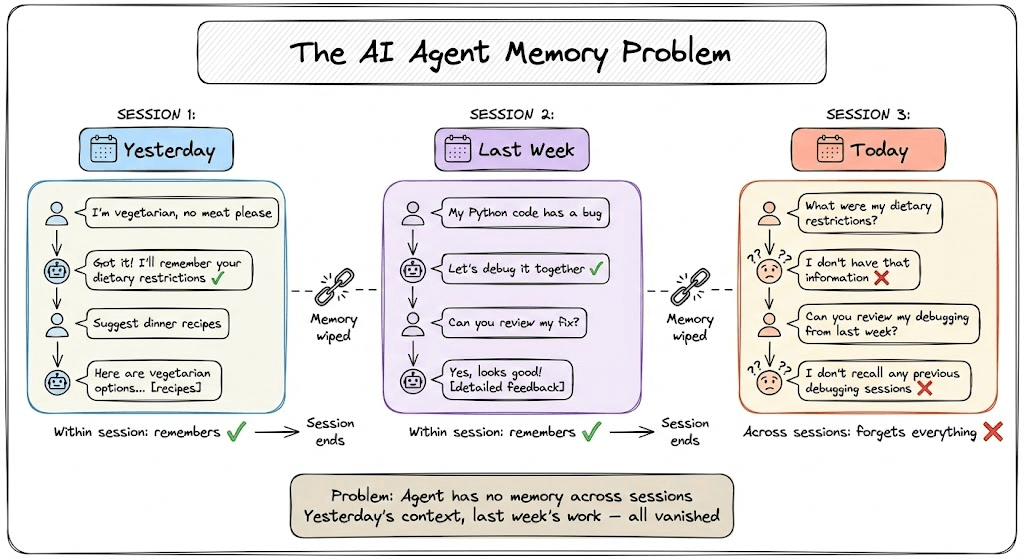
But once the conversation ends, everything disappears.
The user’s dietary restrictions from yesterday? Gone.
The debugging session from last week? Vanished.
The agent has no idea who they are today.
Most developers try to fix this by adding a vector database. Vector search is fast and finds semantically similar content.
But here’s the disconnect: similarity isn’t memory and that distinction breaks production systems.
Later in this article, I’ll show you an open-source framework that solves this.
When Similarity Isn’t Enough
Imagine building a personal food assistant.
Week 1: User says, “I love a good steak - just had the ribeye at Morton’s, it was incredible.”
Week 2: User mentions, “I decided to go vegetarian. Health reasons, and I’m feeling great about it.”
Week 3: User asks, “What restaurants should I try this weekend?”
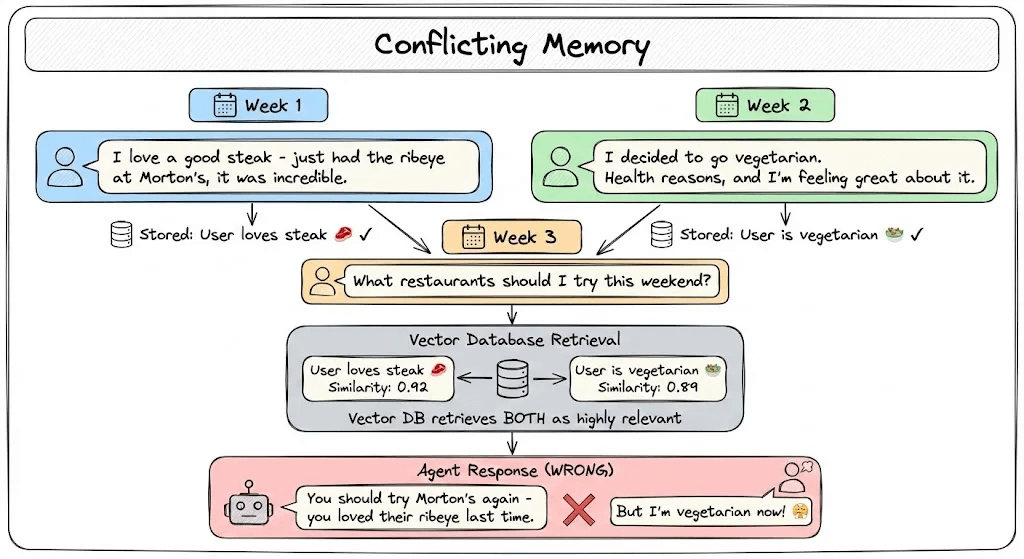
Your vector database retrieves both statements as highly relevant.
Based on this, your agent responds: “You should try Morton’s again - you loved their ribeye last time.”
The user is vegetarian now but the agent recommended a steakhouse to someone who explicitly stopped eating meat.
The fundamental issue: Embeddings measure semantic closeness, not truth.
Vector databases don’t understand that “decided to go vegetarian” replaces “I love a good steak” - they just see two food-related statements and treat them as equally valid.
Why This Breaks in Production
The moment you deploy an agent without proper memory, you hit real operational failures.
Here’s how it breaks production in four ways:
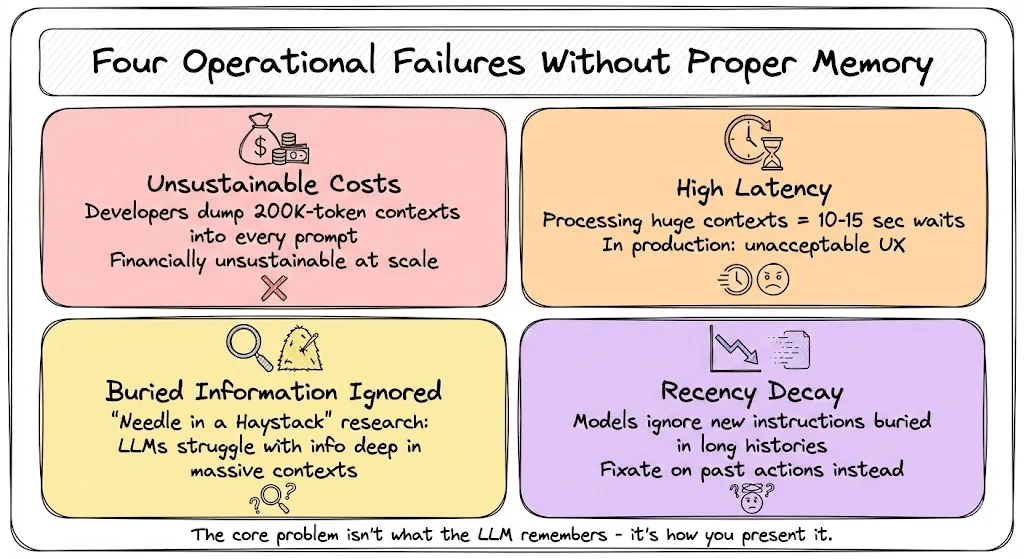
Every token costs money: Developers overcompensate by dumping 200K-token contexts into every prompt. Financially unsustainable at scale.
High latency destroys UX: Processing huge contexts means 10-15 second waits. In production, that’s unacceptable.
Buried information gets ignored: “Needle in a Haystack” research proved LLMs struggle with information deep in massive contexts.
Recency decay creates blind spots: Google DeepMind found that when new instructions are buried in long chat histories, models ignore them. They fixate on past actions instead of following current directions.
The core problem isn’t what the LLM remembers - it’s how you present it.
What Agents Actually Need to Remember
To fix this, we need to step back and understand what memory actually means for agents.
Production agents need two layers of memory:
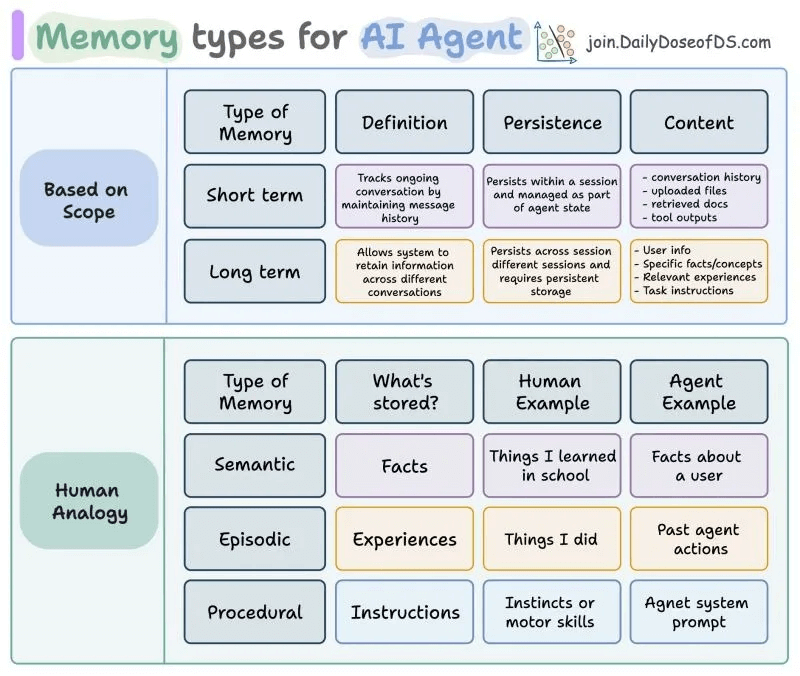
Short-term memory tracks ongoing conversations within a session - conversation history, uploaded files, retrieved documents and tool outputs.
Think of this as working memory, the context needed for the current task.
Long-term memory persists across sessions and stores user information, preferences, learned facts and past experiences.
This is what should survive after the conversation ends.
Within long-term memory, agents need three types borrowed from human psychology:
Semantic memory stores facts and concepts. For example: “User prefers Python,” “works in fintech,” “went vegetarian.”
Episodic memory stores experiences and events such as past actions, previous solutions that worked and history of interactions.
Procedural memory stores instructions and processes, including system prompts, workflow instructions, and operational procedures.
Building Memory Systems
Supporting short-term context, long-term persistence, and evolving beliefs requires building a system, not a single component.
Let’s see what that looks like in Python.
The first piece is short-term memory: the active context for a single session. This includes recent messages, tool outputs and retrieved documents.
It’s enough to keep the conversation coherent, but it’s also fragile.
Once you hit the token limit, older messages are dropped and important context disappears along with them.

To retain information across sessions, we then add long-term memory.
The usual approach is to extract facts from conversations, embed them and store them in a vector database.

Now the agent can remember things from previous interactions. But memory is not static. Users change preferences, revise decisions, and override earlier instructions.
What happens when new facts contradict old ones?
To handle this, we need to model change over time. That means detecting conflicts and explicitly marking which information is current and which is historical.

Now you’re tracking changes over time, but that still doesn’t solve retrieval. When a new query comes in, the agent has to decide which version of a memory is current and should be used.
One simple way to handle this is to bias retrieval toward more recent memories, gradually reducing the influence of older ones unless they are explicitly relevant.

At this point, the system has short-term memory, long-term storage, conflict resolution and temporally aware retrieval. In theory, this is enough to support a stateful agent.
In practice, building this from scratch takes significant time.
You’re coordinating multiple data stores, extraction pipelines, retrieval heuristics, and background maintenance logic, and many of the hardest problems only surface once the system is in production.
An Open-Source Memory Framework
Whether you’re building customer support bots, personal assistants or development tools, the memory challenge is the same.
Cognee is a 100% open-source framework that solves this by combining vector search with knowledge graphs.
But it’s not just plugging two databases together.
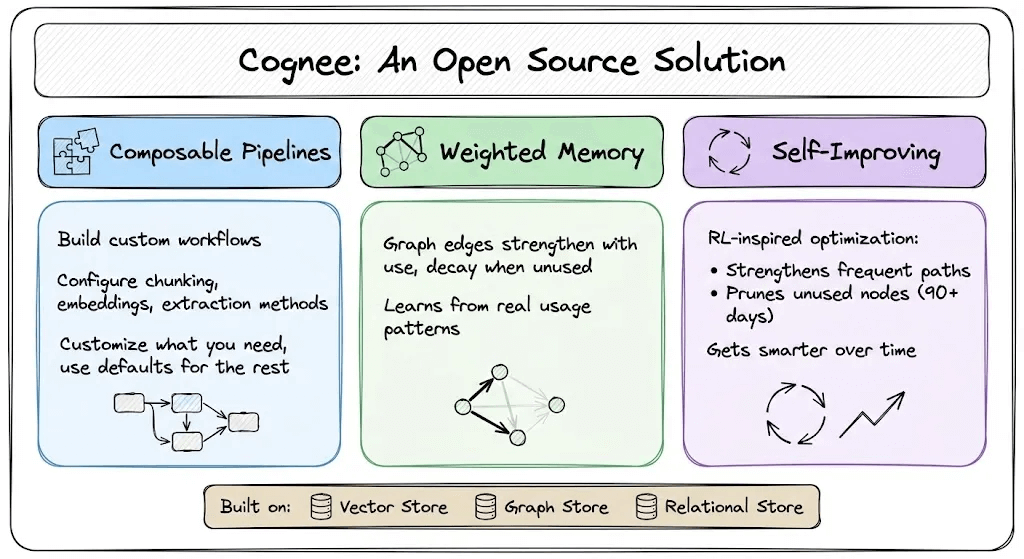
Here’s what makes it different:
Composable pipelines: Instead of a fixed workflow, Cognee lets you mix and match components like chunking strategies, embedding models, and entity extraction methods. You customize what matters and use defaults for the rest.
Weighted memory: Knowledge graph connections are weighted by usage. When retrieved information leads to successful responses, those relationships strengthen, so the graph evolves to reflect what actually matters in practice.
Self-improving (memify): Memory is continuously refined via RL-inspired optimization, strengthening useful paths, pruning stale nodes, and auto-tuning based on real usage.
This is powered by three complementary stores: vector (semantic search), graph (relationships and temporal logic), and relational (provenance and metadata).
Earlier, I showed what building memory from scratch involves: managing short-term context, evolving long-term facts, resolving conflicts over time and retrieving the right information when it matters.
Even a minimal Python setup quickly turns into a system with many moving parts.
With Cognee, all of that reduces to six lines:
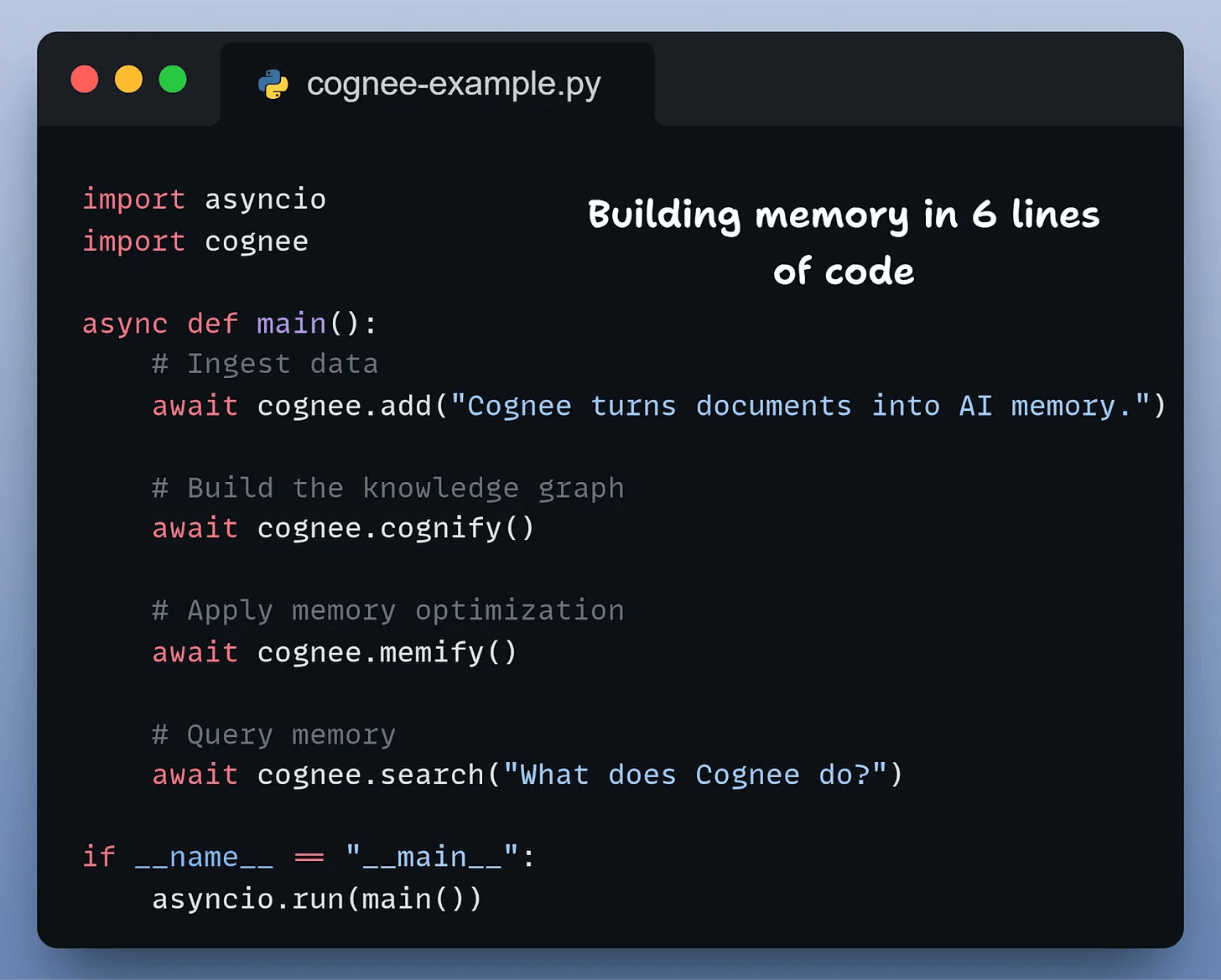
That’s it.
add() ingests your documents (text, PDFs, audio, images)
cognify() builds the knowledge graph with entities and relationships
memify() optimizes memory based on usage patterns
search() retrieves with temporal awareness
Time to production: hours, not weeks.
How Cognee Handles the Vegetarian Scenario
Let’s replay the same scenario with Cognee handling memory.
Week 1: User says, “I love a good steak - just had the ribeye at Morton’s, it was incredible.”
Cognee creates: User enjoys steak, User has_preference “meat”, positive experience at Morton’s.
Week 2: “I decided to go vegetarian. Health reasons, and I’m feeling great about it.”
Cognee recognizes the conflict and updates: Archives previous meat preference as historical, creates new preference “vegetarian”, marks change timestamp.
Week 3: “What restaurants should I try this weekend?”
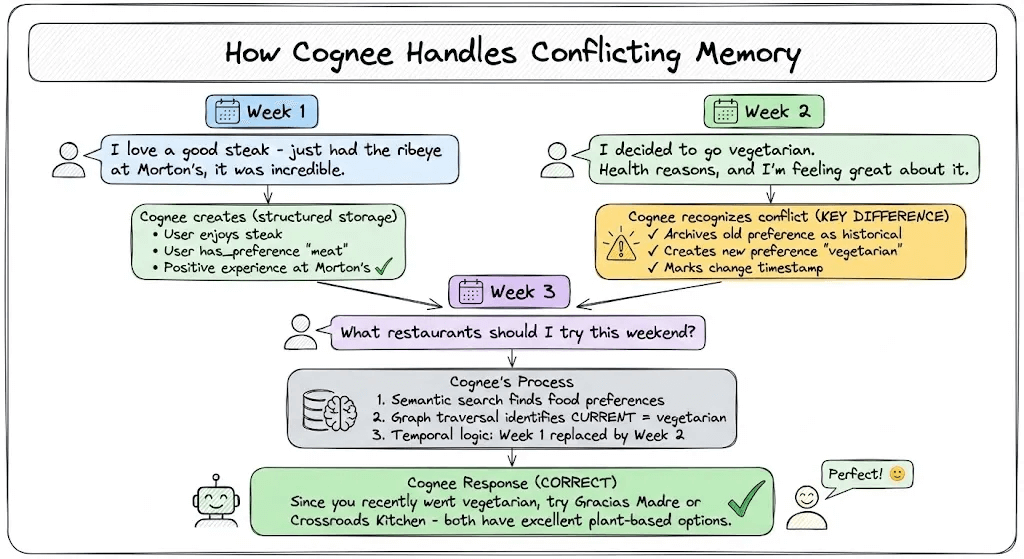
Cognee’s process:
Semantic search finds food preference and restaurant content
Graph traversal identifies current dietary preference is vegetarian
Temporal logic recognizes Week 1 preference was replaced by Week 2 decision
Returns: “Since you recently went vegetarian, try Gracias Madre or Crossroads Kitchen - both have excellent plant-based options.”
The difference: Cognee understands that preferences change over time, archives outdated information as historical context and uses current state for recommendations.
The Bottom Line
If your retrieval is semantic, your memory needs to be relational and temporal.
Vector search alone is like books scattered on the floor. You can find words, but can’t trace connections, understand what supersedes what, or know what’s current versus outdated.
Production agents need memory that:
Captures relationships (knowledge graph)
Understands time (temporal logic)
Evolves with usage (weighted connections)
Maintains itself (automatic optimization)
Building this from scratch takes weeks and requires expertise across vector databases, graph databases, and LLM orchestration.
You’ll hit edge cases you never anticipated.
Cognee provides these capabilities as a single open-source system, so you don’t have to assemble and maintain them yourself.
TinyLoRA: LoRA Scaled Down to 1 Parameter
Researchers from Meta, Cornell, and CMU just dropped a banger.
They turned an 8 billion parameter model into a math and reasoning powerhouse by tweaking just 13 of those parameters.
That’s 26 bytes. Less storage than this sentence.
The model hit 91% accuracy on GSM8K, up from 76% before the tweak.
The method is called TinyLoRA, and it pushes low-rank adaptation to its absolute extreme.
Some quick background on LoRA first:
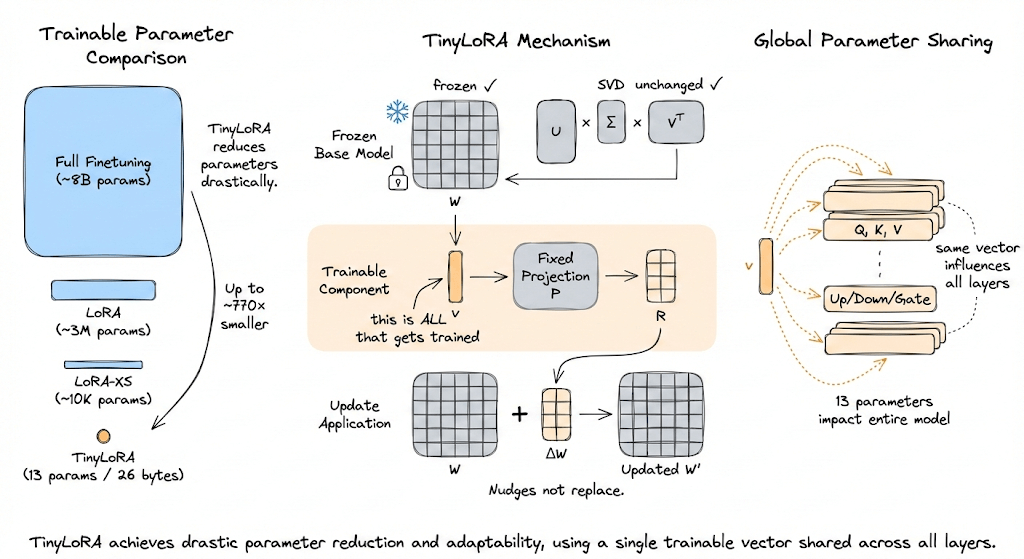
When you finetune a large model, you’re updating billions of parameters. LoRA showed you can instead learn a small low-rank update on top of frozen weights, bringing that down to millions.
LoRA-XS compressed this even further by leveraging the internal structure of the weight matrices, bringing it down to tens of thousands.
TinyLoRA goes all the way down to one.
Here’s how:
Instead of learning a matrix-sized update, learn a tiny vector that gets expanded into a full weight update through a fixed projection. Only the tiny vector is trainable.
Tie this vector across all modules and layers so the entire model shares the same tiny set of trainable parameters.
With full weight tying, the entire model update collapses to as few as one trainable parameter.
But the real insight is not the architecture. It’s that this only works with reinforcement learning.
When they tried SFT with the same tiny updates, performance barely moved. SFT at 13 parameters hits 83%. RL hits 91%. To match RL performance, SFT needs 100x to 1000x more parameters.
Why? Because SFT forces the model to memorize full demonstration trajectories, treating every token as equally important. RL only passes back a sparse reward signal, and through resampling, the useful signal accumulates while the noise cancels out.
This means RL is not teaching the model new knowledge. It’s making a precise, tiny adjustment to unlock reasoning the model already has.
One more surprising finding: as model size grows, the number of parameters needed to reach peak performance shrinks. This suggests trillion-scale models might be tunable for specific tasks with literally a handful of bytes.