
Build an Automated Agent Optimization Workflow
...explained with step-by-step code.

In today's newsletter:
Unified backend framework for APIs, Events, and Agents.
Build an Automated Agent Optimization Workflow.
3 prompting techniques for reasoning in LLMs.
Unified backend framework for APIs, Events, and Agents [Open-source]

Most AI backends are complete chaos with patched-together APIs, scattered cron jobs, and agents that can’t even communicate properly.
They may have five different frameworks just to complete a single workflow.
Motia (open-source) provides a unified system where APIs, background jobs, events, and agents are just plug-and-play steps.
Just like React streamlines frontend development, Motia simplifies AI backend, where you only need one solution instead of a dozen tools.
Key features:
You can have Python, JS & TypeScript in the same workflow.
You can deploy from your laptop to prod in one click.
It has built-in observability & state management.
It provides automatic retries & fault tolerance.
It supports streaming response.
GitHub repo → (don’t forget to star)
Build an Automated Agent Optimization Workflow
Developers manually iterate through prompts to find an optimal one. This is not scalable, and performance can degrade across models.
Today, let’s learn how to use the Opik Agent Optimizer toolkit that lets you automatically optimize prompts for LLM apps.
The idea is to start with an initial prompt and an evaluation dataset, and let an LLM iteratively improve the prompt based on evaluations.
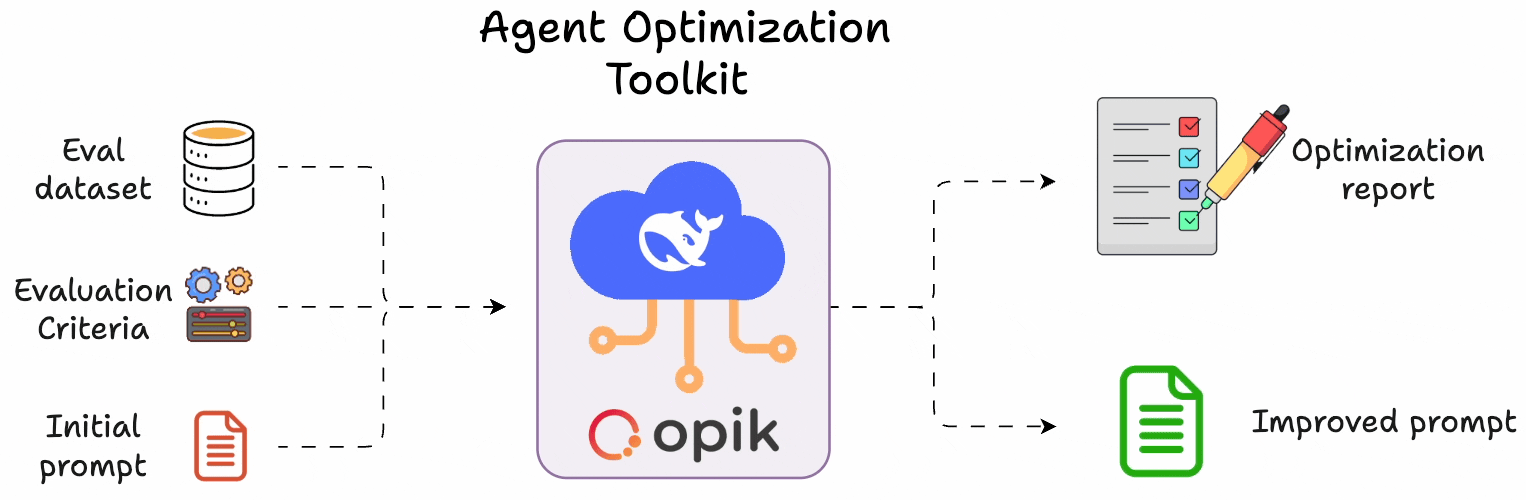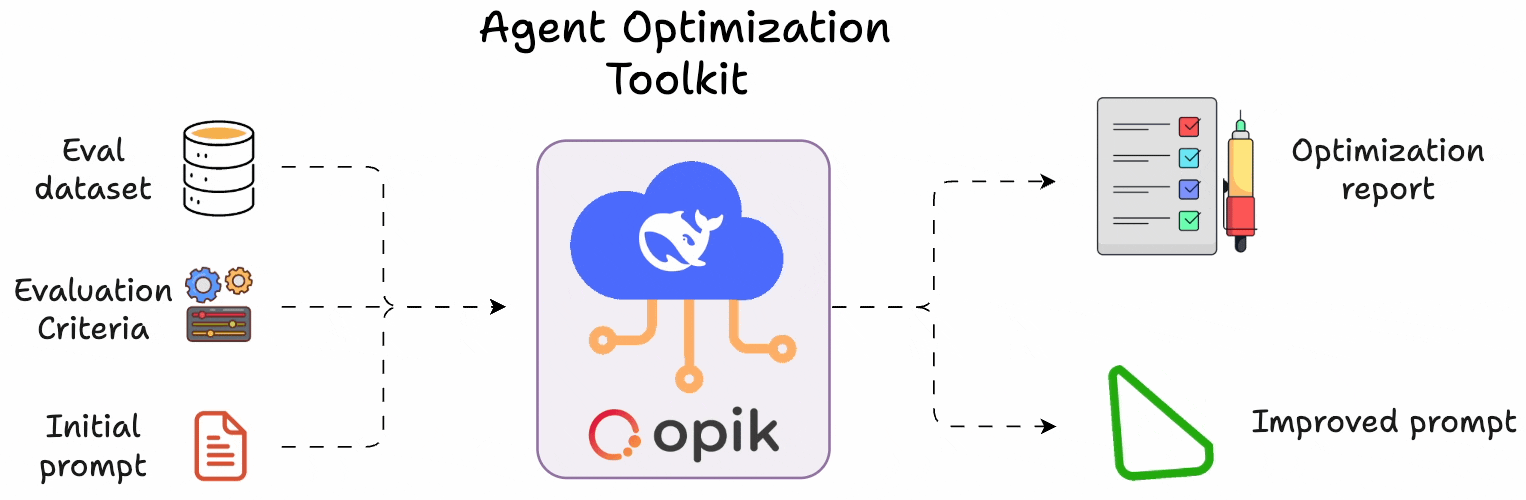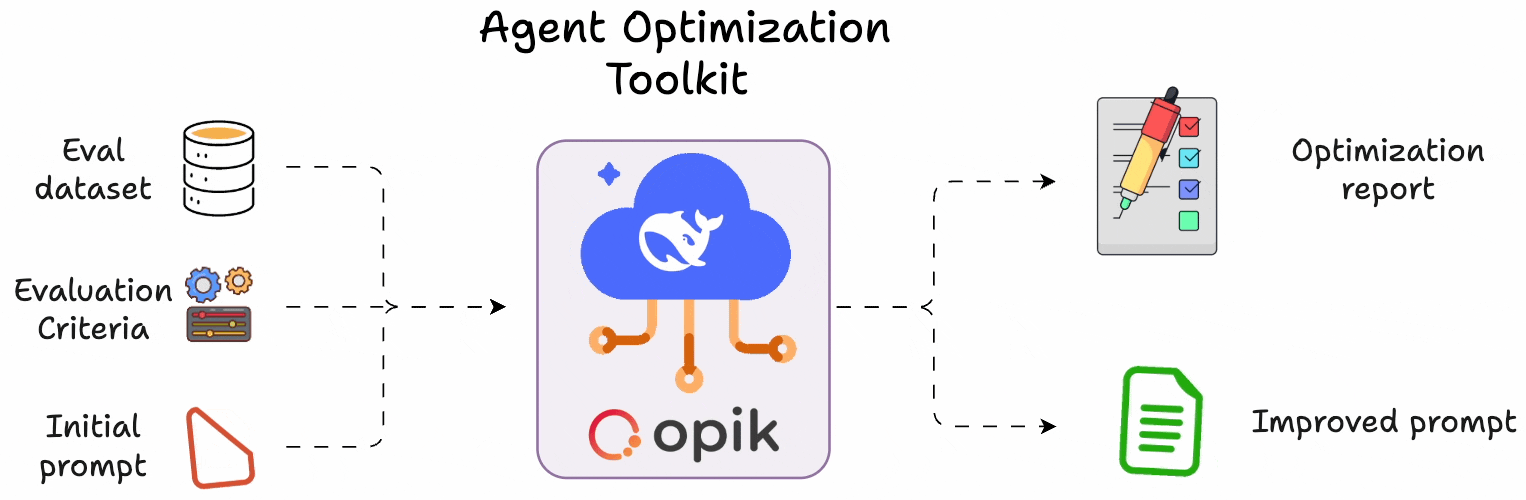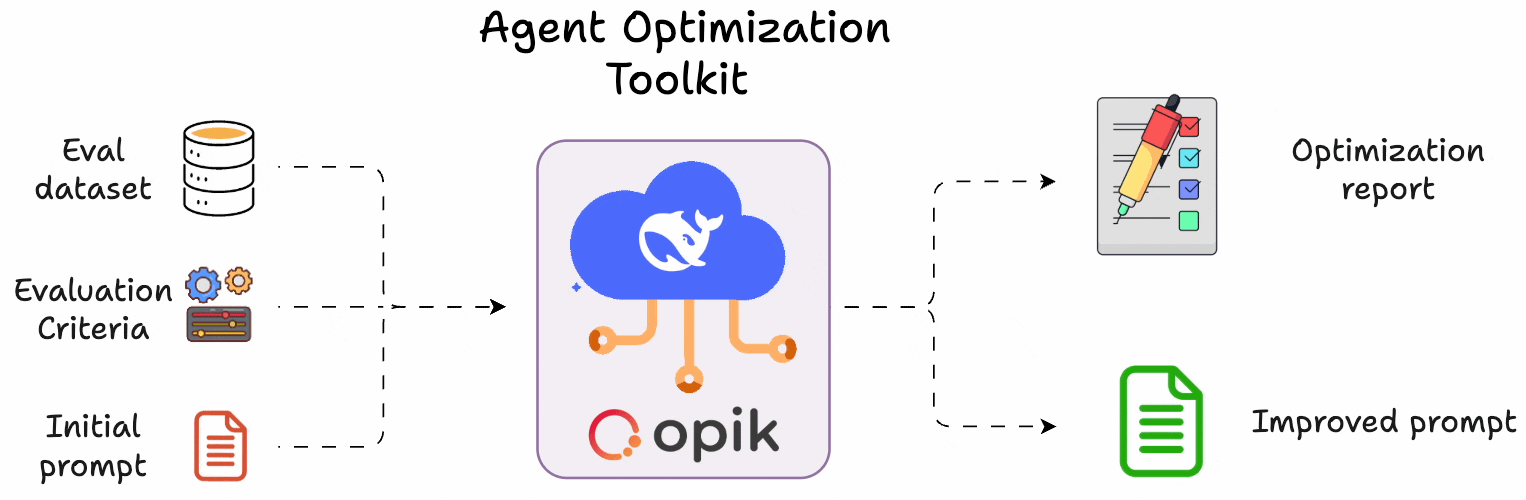
To begin, install Opik and its optimizer package, and configure Opik:

Next, import all the required classes and functions from opik and opik_optimizer:

LevenshteinRatio→ Our metric to evaluate the prompt’s effectiveness in generating a precise output for the given input.MetaPromptOptimizer→ An algorithm that uses a reasoning model to critique and iteratively refine your initial instruction prompt.tiny_test→ A basic test dataset with input-output pairs.
Next, define an evaluation dataset:

Moving on, configure the evaluation metric, which tells the optimizer how to score the LLM’s outputs against the given label:

Next, define your base prompt, which is the initial instruction that the MetaPromptOptimizer will try to enhance:

Next, instantiate a MetaPromptOptimizer, specifying the model to use in the optimization process:

Finally, the optimizer.optimize_prompt(...) method is invoked with the dataset, metric configuration, and prompt to start the optimization process:

It starts by evaluating the initial prompt, which sets the baseline:

Then it iterates through several different prompts (written by AI), evaluates them, and prints the most optimal prompt. You can invoke result.display() to see a summary of the optimization, the best prompt found and its score:

The optimization results are also available in the Opik dashboard for further analysis and visualization:

And that’s how you can use Opik Agent Optimizer to enhance the performance and efficiency of your LLM apps.
While we used GPT-4o, everything here can be executed 100% locally since you can use any other LLM + Opik is fully open-source.
Here is the link to the Opik docs to learn more →
Talking of prompting, let's see 3 techniques that induce reasoning in LLMs below.
3 prompting techniques for reasoning in LLMs
Here are three popular prompting techniques that help LLMs think more clearly before they answer.
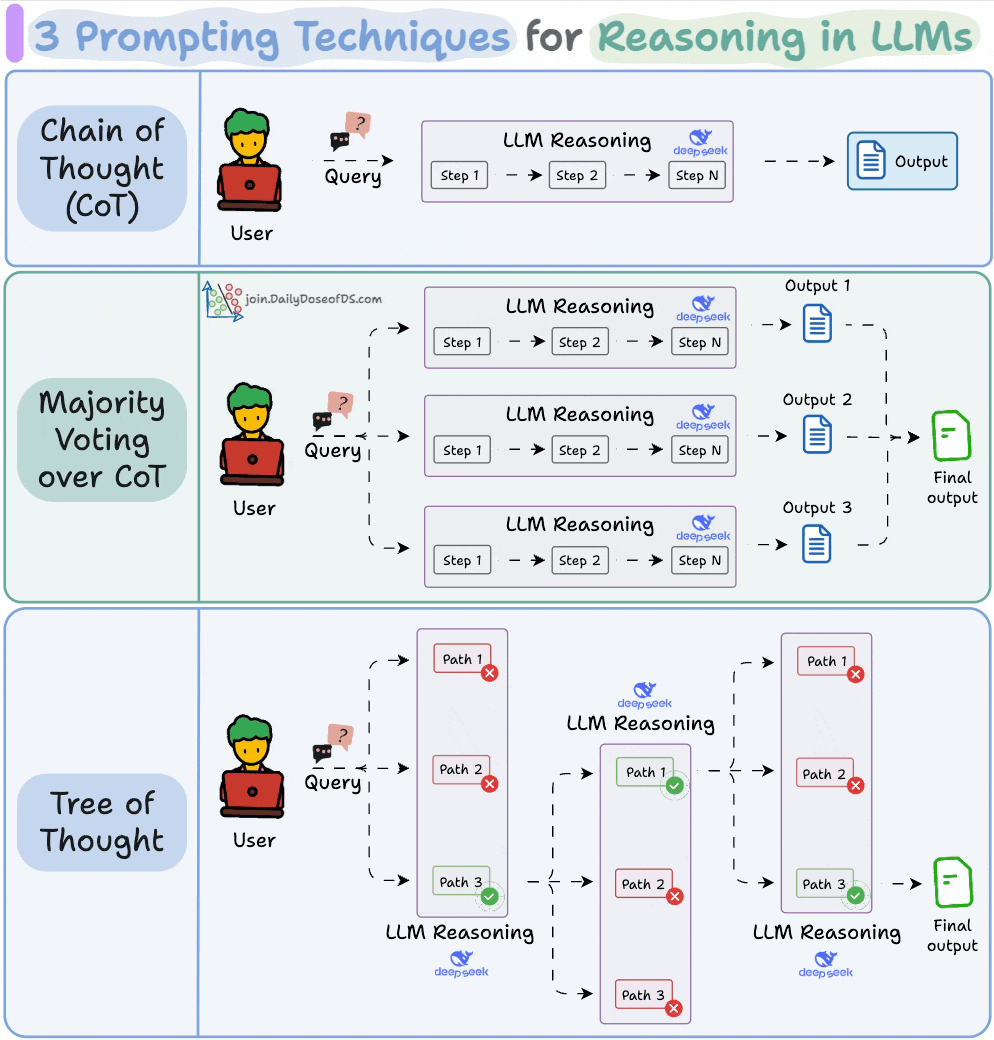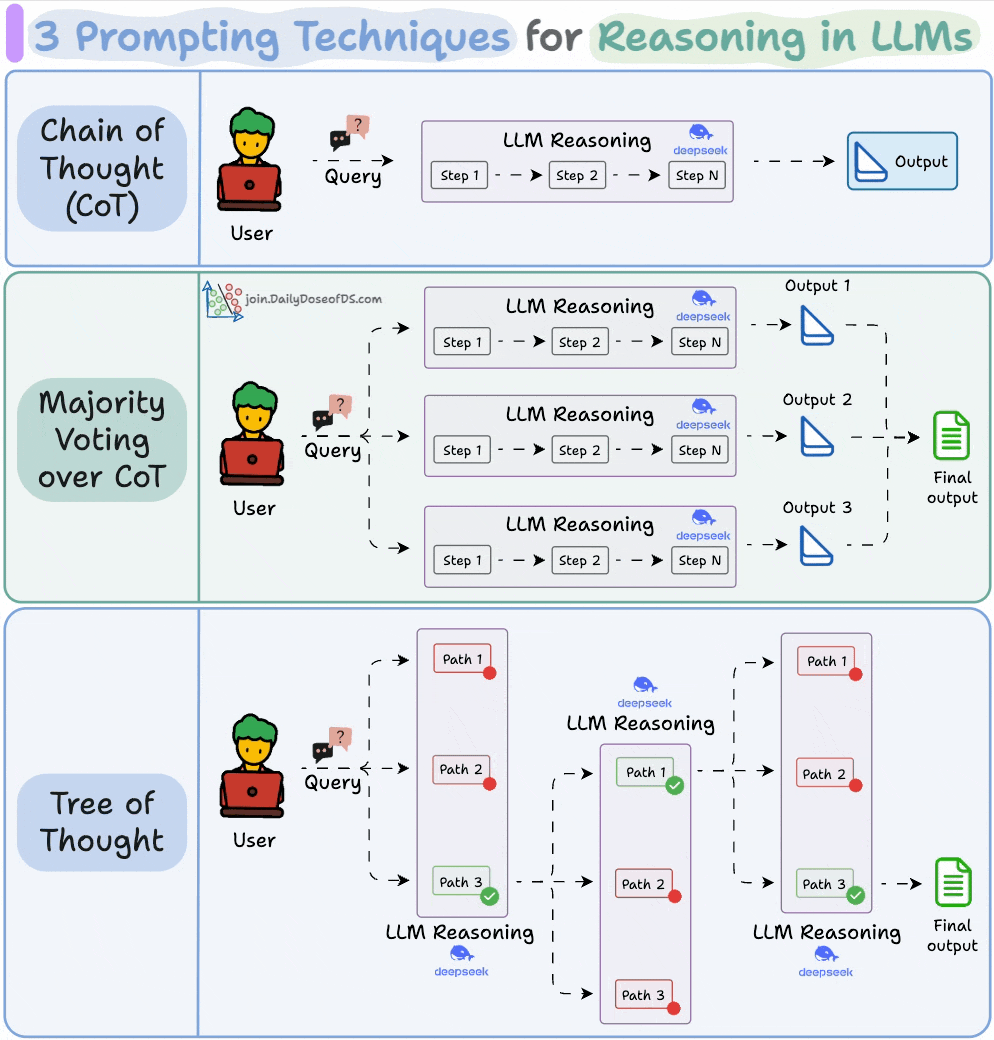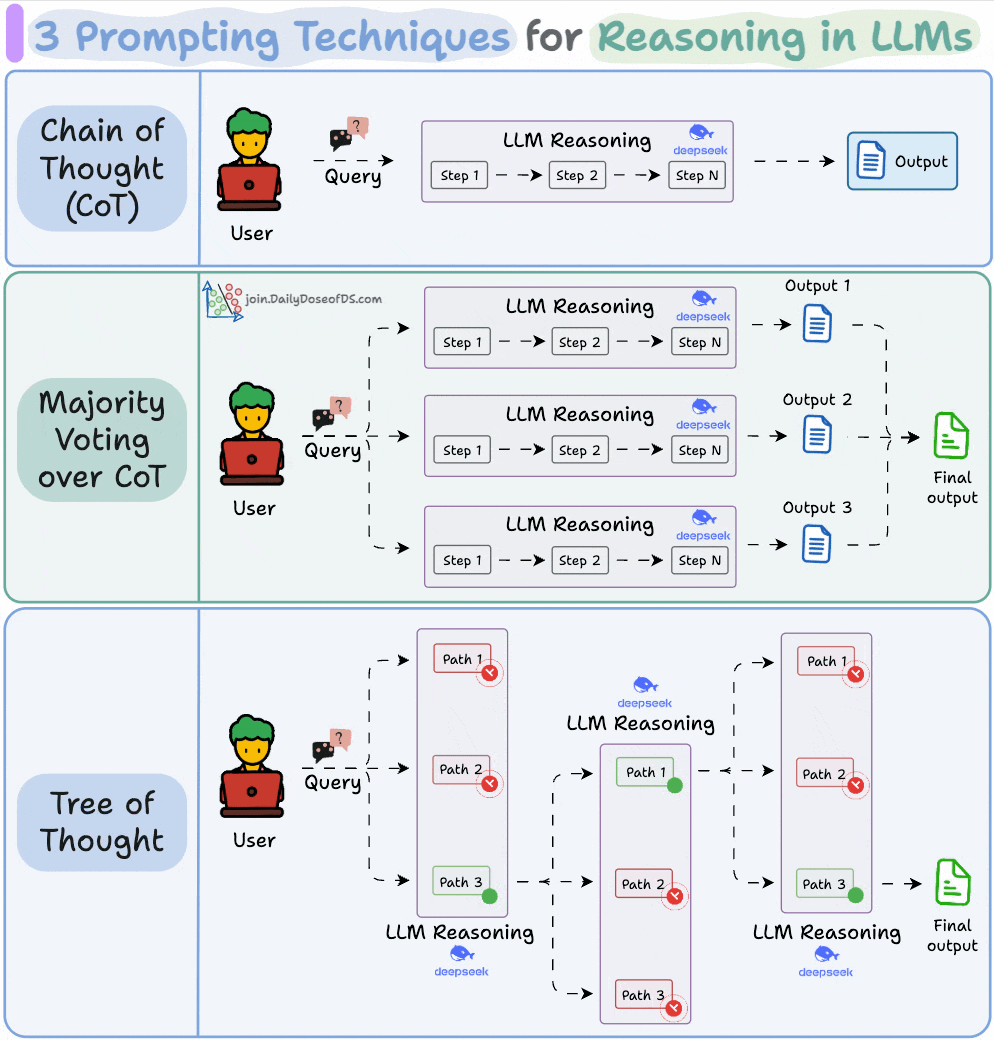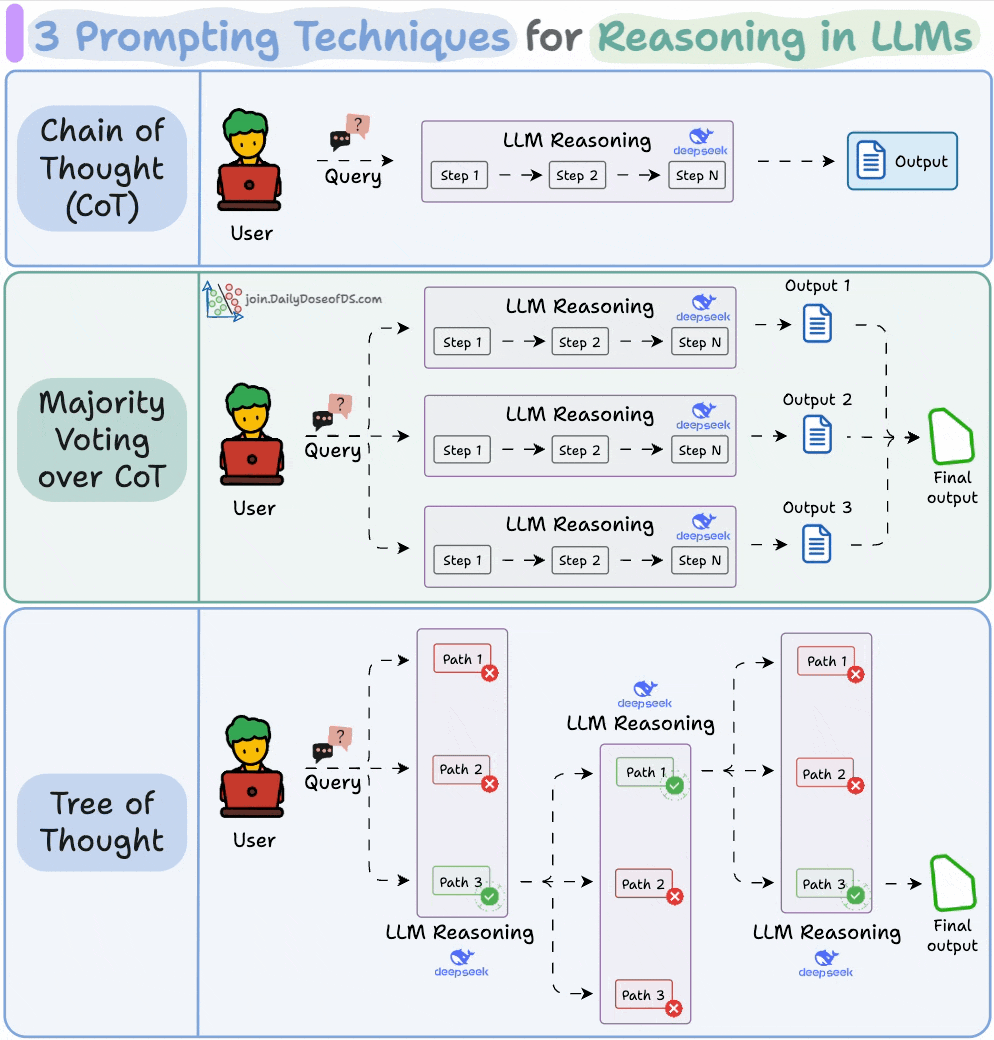
#1) Chain of Thought (CoT)
The simplest and most widely used technique.
Instead of asking the LLM to jump straight to the answer, we nudge it to reason step by step.

This often improves accuracy because the model can walk through its logic before committing to a final output.
For instance:
Q: If John has 3 apples and gives away 1, how many are left? Let's think step by step:
It’s a simple example, but this tiny nudge can unlock reasoning capabilities that standard zero-shot prompting could miss.
#2) Self-Consistency (a.k.a. Majority Voting over CoT)
CoT is useful but not always consistent.
If you prompt the same question multiple times, you might get different answers depending on the temperature setting (we covered temperature in LLMs here).
Self-Consistency embraces this variation.
You ask the LLM to generate multiple reasoning paths and then select the most common final answer.

It’s a simple idea: when in doubt, ask the model several times and trust the majority.
This technique often leads to more robust results, especially on ambiguous or complex tasks.
However, it doesn’t evaluate how the reasoning was done—just whether the final answer is consistent across paths.
#3) Tree of Thoughts (ToT)
While Self-Consistency varies the final answer, Tree of Thoughts varies the steps of reasoning at each point and then picks the best path overall.
At every reasoning step, the model explores multiple possible directions. These branches form a tree, and a separate process evaluates which path seems the most promising at a particular timestamp.
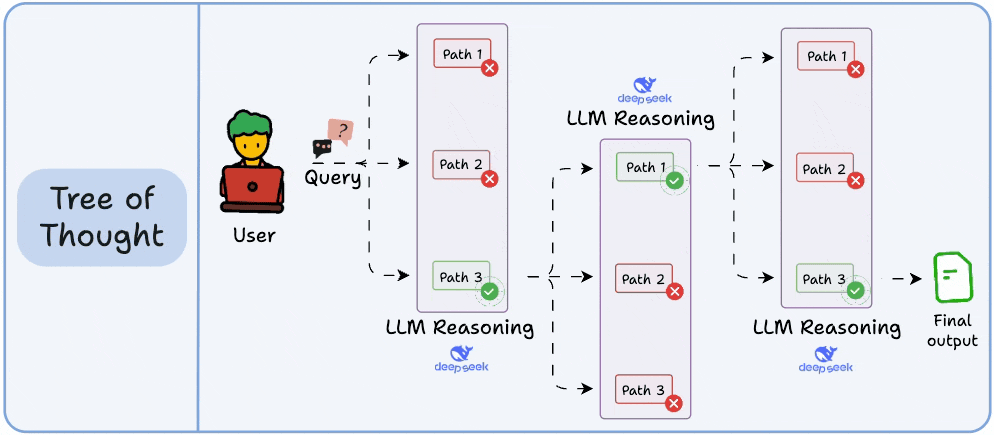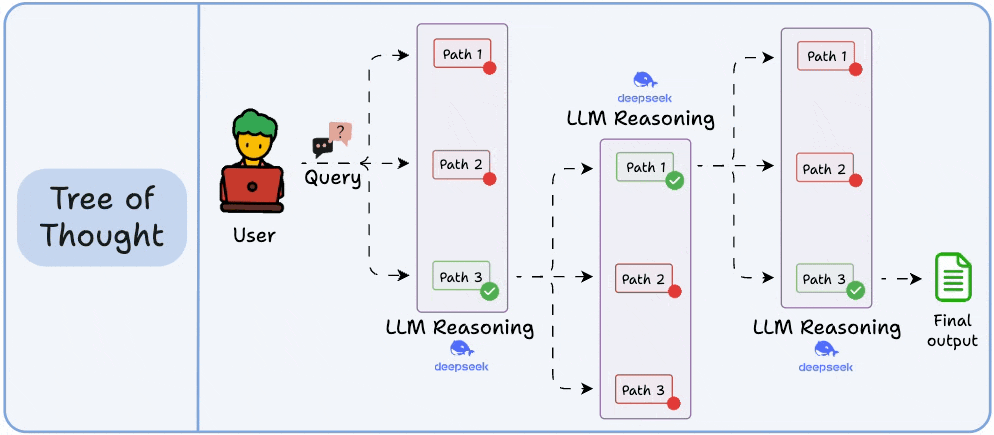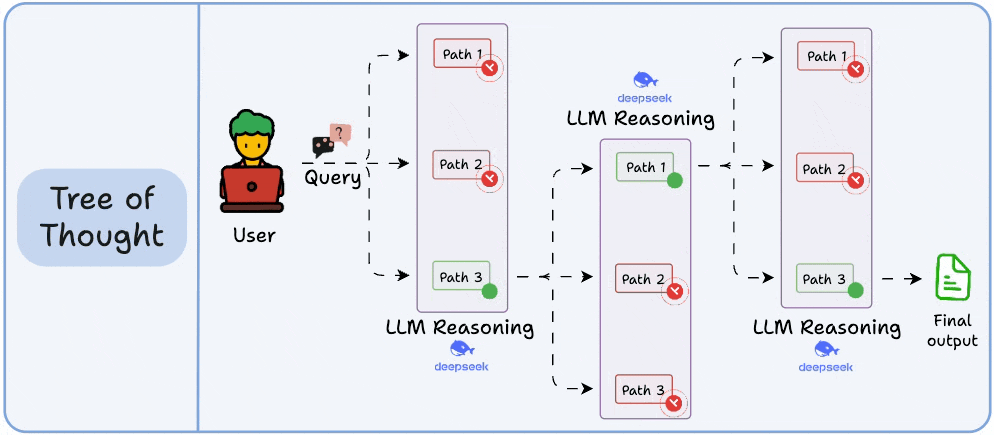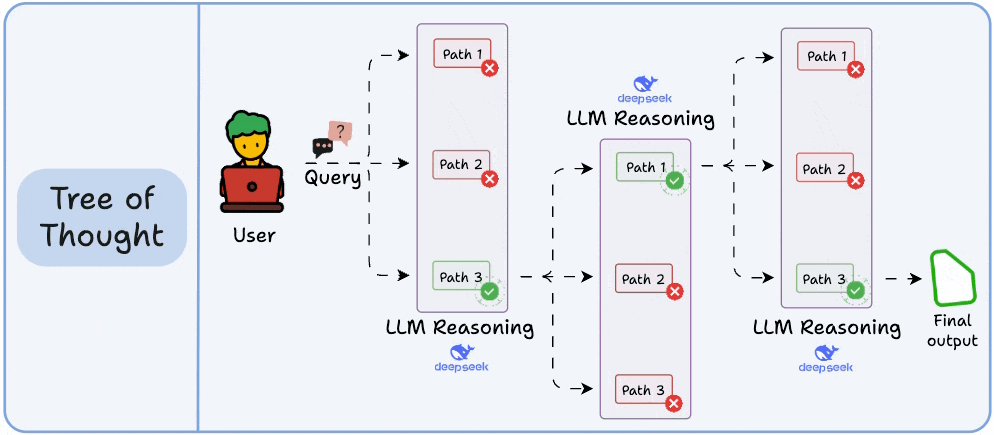
Think of it like a search algorithm over reasoning paths, where we try to find the most logical and coherent trail to the solution.
It’s more compute-intensive, but in most cases, it significantly outperforms basic CoT.
We’ll put together a demo on this soon, covering several use cases and best practices for inducing reasoning in LLMs through prompting.
Let us know what you would like to learn.
That said, the ReAct pattern for AI Agents also involves Reasoning.
We implemented it from scratch here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.