
Build Your Own 100% Local AI Second Brain
How the best builders in tech are all converging on AI second brains

A tricky LLM interview question
Your RAG system scores 90% retrieval accuracy on 5k company docs.
But scaling to 500k docs drops the accuracy to just 50%, with the same embedding model and retriever.
Why did this happen?
The simplest answer is that more documents mean more competition for the top-k retrieval slots. That is true, but it doesn’t explain why accuracy drops this dramatically.
The answer comes down to how enterprise docs are distributed in the embedding space.
Today, a single product decision in a company generates meeting transcripts, Slack threads, Confluence docs, Jira tickets, and email threads.
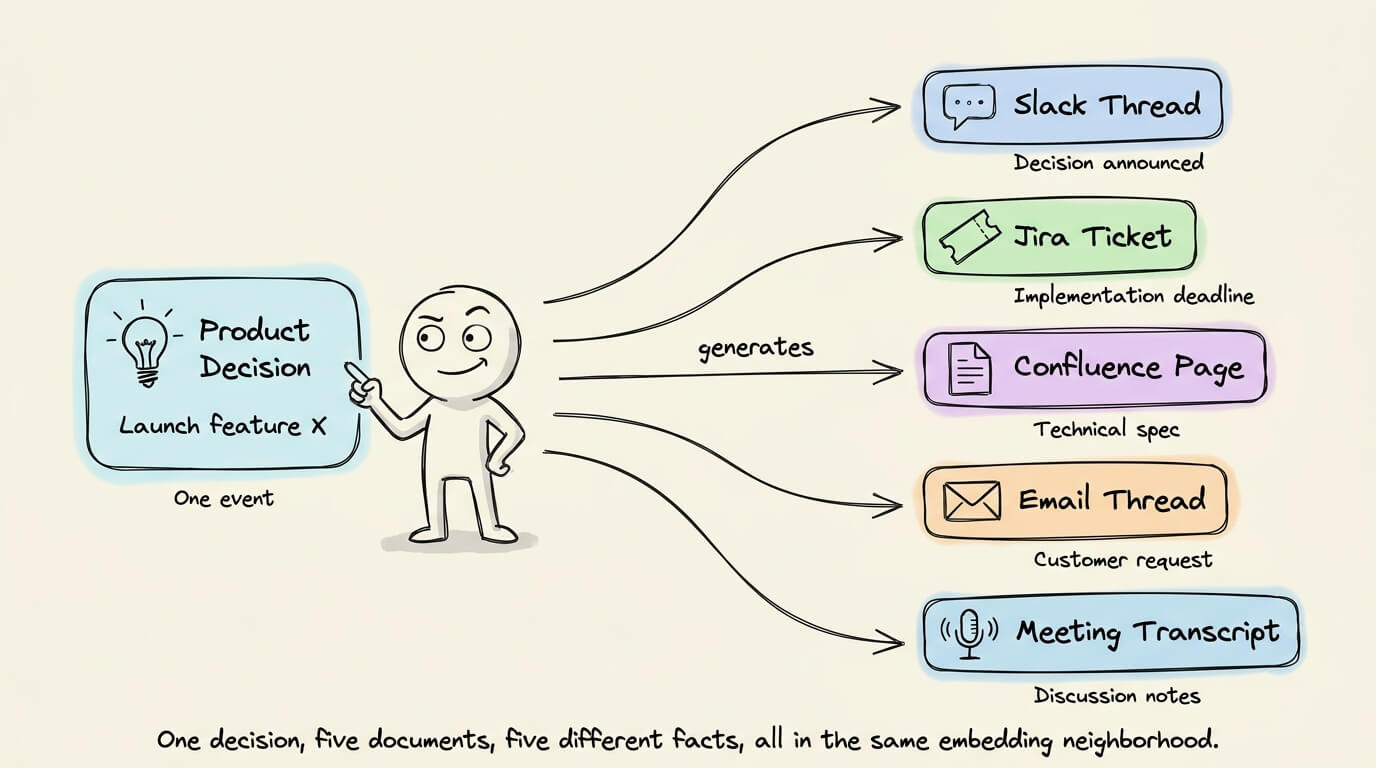
They are related to the same event, so they all land in a similar region of the embedding space.
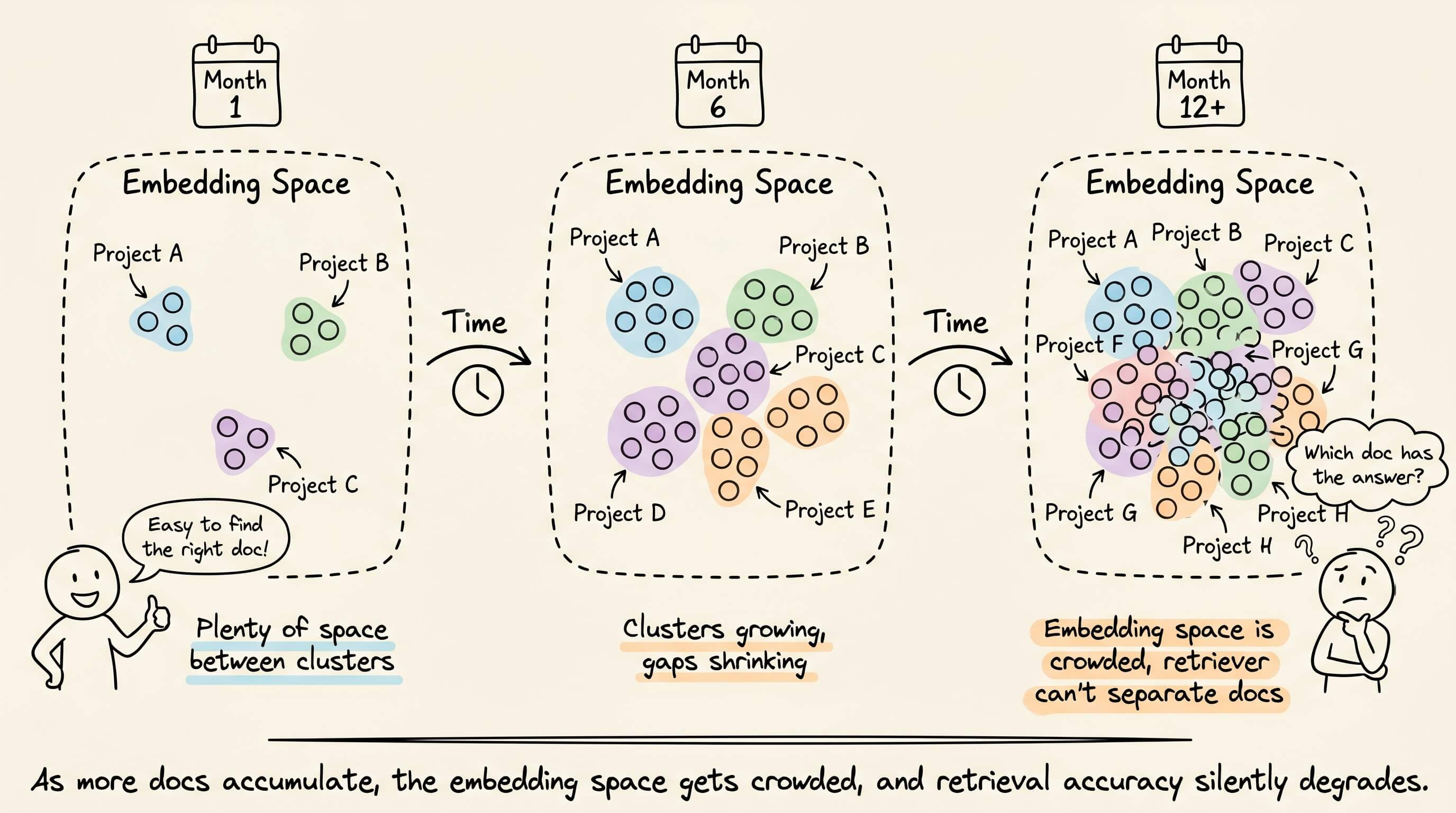
As the company operates over months, this pattern repeats for every project/customer/roadmap, and the embedding space fills up with clusters of closely related documents.
But all related docs don’t contain the same facts.
Slack thread covers the decision made
Jira has the implementation deadline
Confluence has the technical spec
Email thread has the customer request
When a query is about a specific fact (like a deadline), the answer lives in one of those docs.
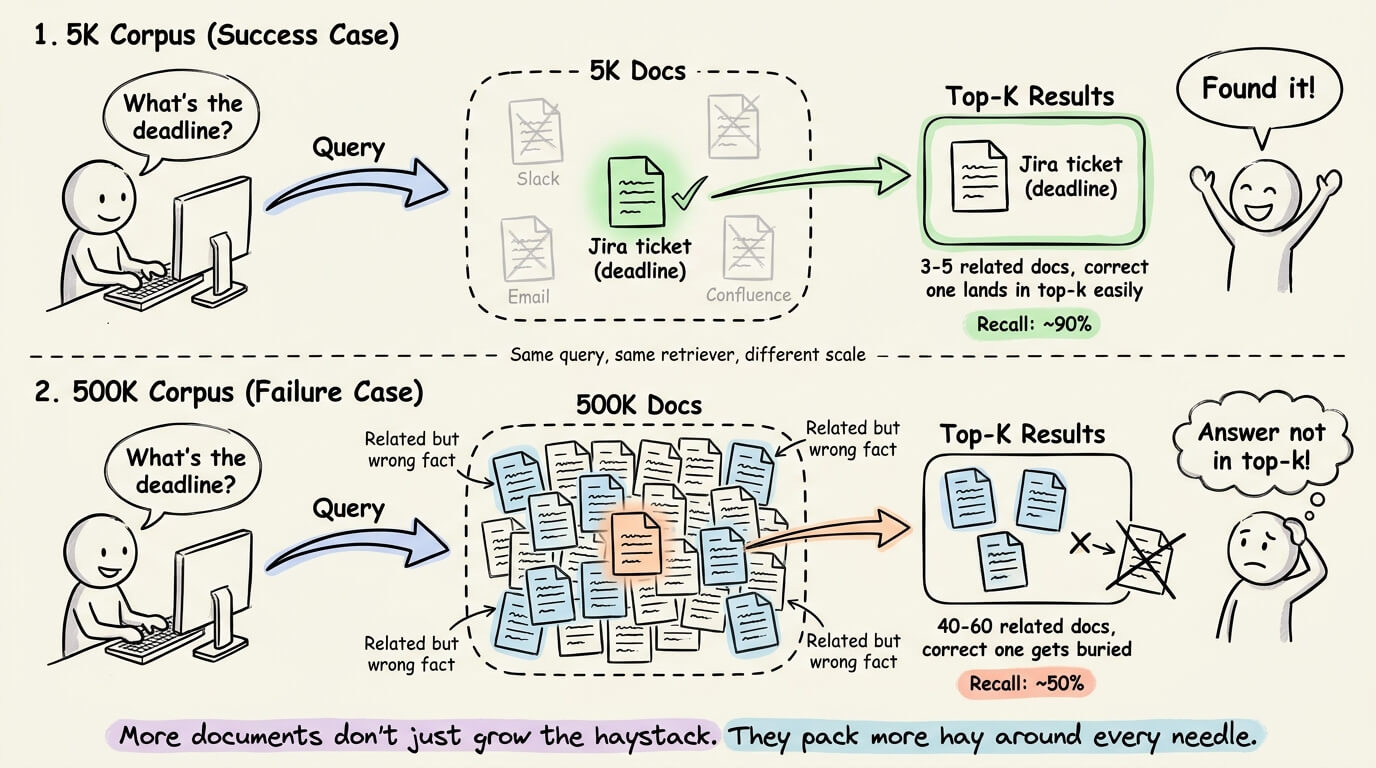
At a 5K corpus size, there might be 3-5 docs touching that topic, and the correct one easily lands in the top-k results.
But at a 500K corpus size, there could be 40-60 total docs, and the one containing the actual answer can easily get pushed out of the top-k by other topically relevant docs, degrading retrieval.
A recent research paper from Onyx documented this.
The researchers used their newly open-sourced EnterpriseRAG-Bench dataset.
It has 500k+ synthetic enterprise documents spread across Slack, Gmail, Jira, GitHub, Confluence, Google Drive, HubSpot, Fireflies, and Linear, with realistic noise like misfiled documents, near-duplicates, and conflicting versions.
They ran the same retrievers at five corpus sizes from 5K to 500K.
Vector search accuracy dropped from 90.7% at 5K documents to 50.6% at 500K docs.
BM25 degraded more gracefully, from 85.8% to 68.4%.
At every scale, higher neighborhood density in the embedding space monotonically correlated with lower recall.
The practical implication here is that retrieval accuracy on a 5k test set tells you almost nothing about production-scale performance.
Always test at a realistic volume to measure the neighborhood density in your embedding space to estimate how much headroom the retriever actually has.
The entire EnterpriseRAG-Bench dataset (500K docs with questions, and the whole evaluation harness) is open-source.
Run your retriever against it at 5K, then at 500K, and see where your own accuracy curve breaks.
You can find the GitHub repo here →
Build your own 100% local AI second brain
Karpathy’s LLM Wiki compiles raw sources into a persistent Markdown wiki with backlinks and cross-references.
The LLM reads papers, extracts concepts, writes encyclopedia-style articles, and maintains an index. The knowledge is compiled once and kept current, so the LLM never re-derives context from scratch at query time.
This works because research is mostly about concepts and their relationships, which are relatively stable.
But this pattern breaks when you apply it to actual work, where context evolves across conversations constantly.
A compiled wiki would have a page about a project, but it wouldn’t track that a deadline agreed in one email thread and moved to a later date in another thread, while the team still assumed the original date.
A wiki doesn’t track ground truth effectively.
We wrote about this recently, and Karpathy liked it:
Tracking this requires a different data structure altogether. Not a wiki of summaries, but a knowledge graph of typed entities where people, decisions, commitments, and deadlines are separate nodes linked across conversations.
Rowboat (GitHub Repo) is an open-source implementation of exactly this, built on the same Markdown-and-Obsidian foundation that Karpathy uses, but extended into a work context.
The way it works is that it ingests conversations from Gmail, Granola, and Fireflies, and instead of writing a summary page per topic, it extracts each decision, commitment, and deadline as its own Markdown file with backlinks to the people and projects involved.
That’s structurally different from a wiki because:
A wiki page about “Project X” gives you a summary of what was discussed.
But a knowledge graph gives you every decision made, who made it, what was promised, when it was promised, and whether anything has shifted since.
Next, let’s set up Rowboat from scratch, walk through what the knowledge graph looks like on disk, and see what happens once the graph is live.
Setup
Rowboat is a local desktop app (Mac, Windows, Linux) that runs entirely on your machine and lets you bring your own model from Ollama, LM Studio, or any hosted API.
It stores everything in ~/.rowboat/ as plain Markdown files in an Obsidian-compatible vault. If you already use Obsidian for notes, you can point it at the same vault and browse Rowboat’s knowledge graph alongside your own files.
If you don’t use Obsidian, the Markdown files are still readable in any editor.
To start, download the app here: rowboatlabs.com/downloads
Next, open ~/.rowboat/config/models.json and point it at whatever you’re running.
For a hosted provider, you can specify:
{
"provider": {
"flavor": "openai",
"apiKey": "sk-..."
},
"model": "gpt-4o"
}Anthropic, Google, and OpenRouter use the same structure, so you can just swap the flavor property above. If you want inference fully on your machine, Ollama works too:
{
"provider": {
"flavor": "ollama",
"baseURL": "http://localhost:11434"
},
"model": "llama3.2"
}Lastly, you can also set the preferred LLM providers using their respective API Keys from the UI itself. Visit Settings → Models:
Once a model is connected, Rowboat wraps it with system prompts that make the LLM aware of your knowledge graph structure.
The model knows about the knowledge/ directory, understands the entity types (People, Projects, Organizations, Topics), can traverse backlinks between notes, and can read Today.md for current context before responding.
It’s effectively a work-oriented system prompt layer on top of whatever model you chose, so the LLM operates as a context-aware copilot rather than a blank chat session.
Moving on, you’ll need your own Google Cloud project with OAuth credentials so that you can invoke Gmail, Calendar, and Drive directly from your machine using those credentials.
The full walkthrough is in google-setup MD file in the Rowboat GitHub repo.
The core flow is this:
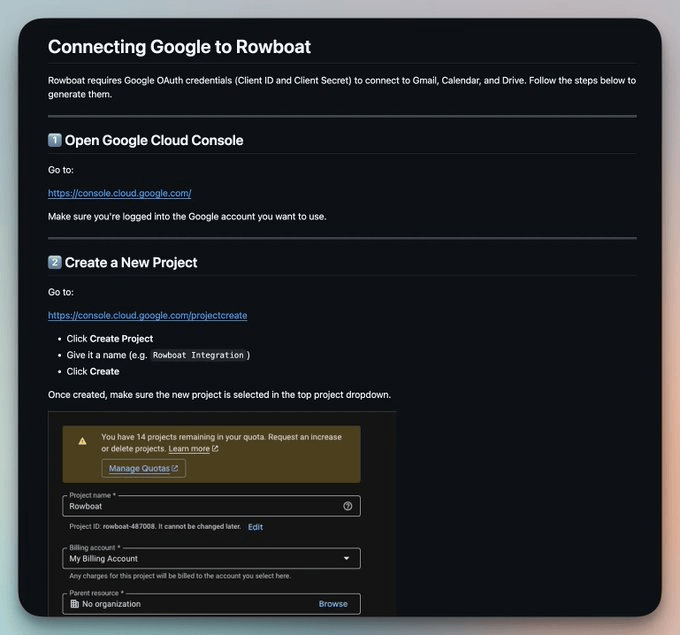
Create a project at console. cloud. google. com
Enable Gmail, Calendar, and Drive APIs
Set up an OAuth consent screen (Testing mode works)
Add your email as a test user
Create an OAuth Client ID (type: Web application)
Set redirect URI to
http://localhost:8080/oauth/callbackPaste your Client ID and Secret into Rowboat when prompted
Once connected, the first sync kicks off, and the graph starts building.
If you use Fireflies or Granola, you can add your API keys here:
// ~/.rowboat/config/fireflies.json # Fireflies meeting transcripts
{
"apiKey": "<your-fireflies-api-key>"
}
// ~/.rowboat/config/granola.json # Granola meeting notes
{
"apiKey": "<your-granola-api-key>"
}The transcripts get pulled into the Meetings/ folder automatically, with decisions and action items extracted into the knowledge graph.
Additionally, you can add other integrations if needed, based on what fits your workflow.
~/.rowboat/config/deepgram.json # voice input and notes
~/.rowboat/config/elevenlabs.json # voice output
~/.rowboat/config/exa-search.json # web research via Exa
~/.rowboat/config/composio.json # external tools
~/.rowboat/config/mcp.json # other MCP toolsOnce the first sync completes, the graph is ready to query.
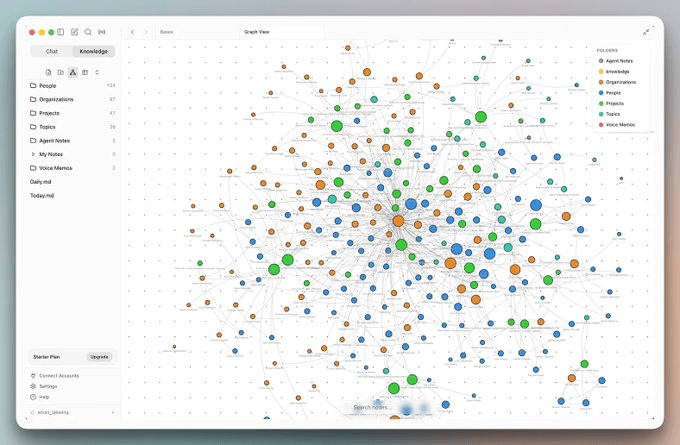
The vault structure on disk
After the first sync, your ~/.rowboat/ directory is live.
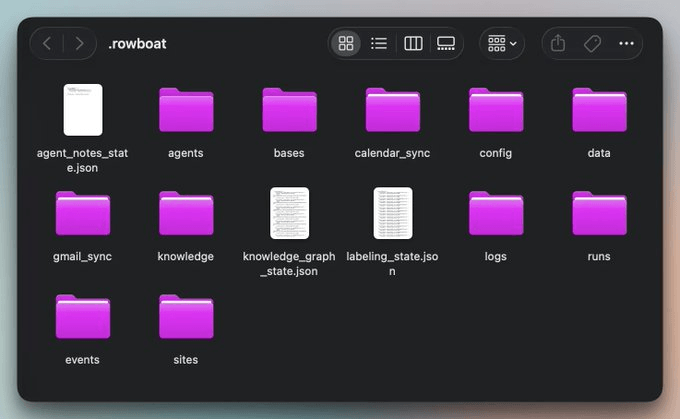
The
config/folder has all your API keys and model configThe
gmail_sync/andcalendar_sync/folder has synced data before it gets processed into the graphThe
events/folder contains the background agent activity, split intodone/andpending/folders.Anything in the
sites/folder gets served athttp://localhost:3210/sites/<slug>/and can be embedded as a live iframe in any note.The
logs/andruns/folders contain the operation history and agent run records.
The more interesting part of the structure is inside the knowledge/ folder:
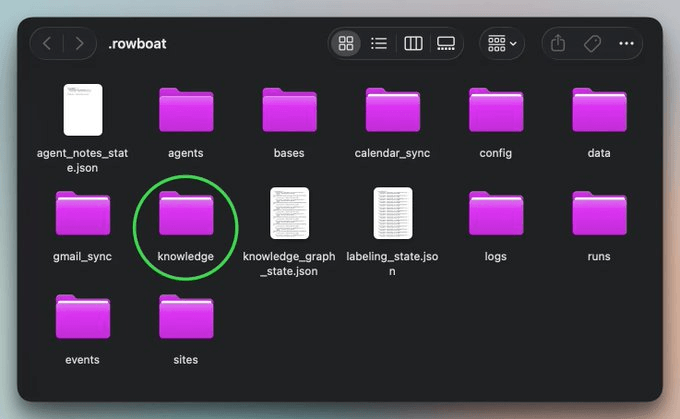
This is what it holds:
Agent Notes/is Rowboat’s memory layer, written from your behavior and writing patterns over time.Meetings/contains processed transcripts from Fireflies or Granola, with decisions and action items extracted.Notes/is for your own Markdown files.Today.mdis the file Rowboat reads first before answering anything. It aggregates recent emails, meeting notes, and drafts into a single entry point for every query.
In addition to this, there are also People/, Organizations/, Projects/, and Topics/ folders.
They all start empty and populate as the signal accumulates. The Rowboat Agent only creates an entity file once there’s enough evidence across emails, meetings, and decisions to justify it.
This is a deliberate design choice because premature entity creation from noisy data (spam senders, marketing emails) would pollute the graph.
Rowboat doesn’t load the full vault on every query. It reads Today.md first, then pulls only the entity files relevant to your request. The graph can grow to hundreds of notes while the query cost stays flat.
Querying the graph
Once sync completes, here’s a useful first query you can ask:
Prep me for my 2pm meeting with Sarah ChenThis depicts the result:
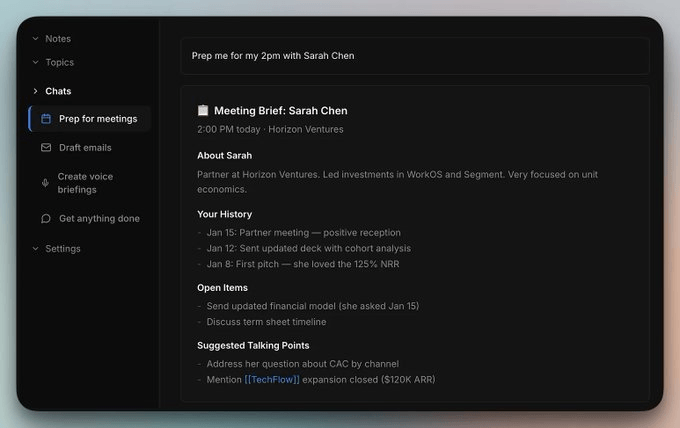
Under the hood, the Rowboat Agent traversed Sarah’s entity node and its backlinks.
Her role and firm came from email signatures and meeting attendees.
Your interaction history was reconstructed from calendar events and threads.
Open items were extracted from past meeting transcripts.
And talking points come from related entities in the graph.
Any [[entity]] reference in the brief is a live backlink that you can click through:
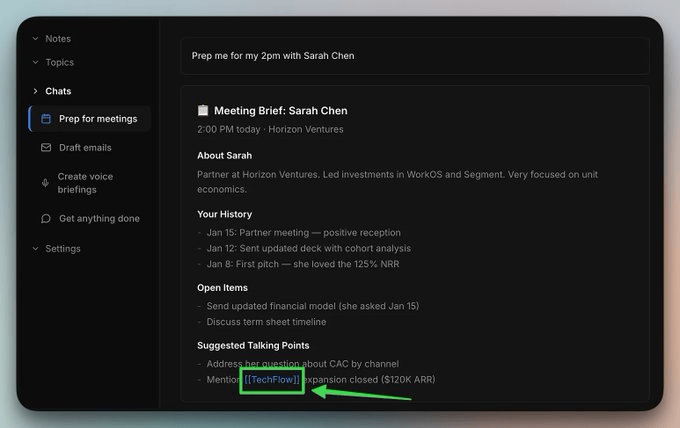
This will show the full entity node, so additional context for any account, person, or project becomes visible in just one hop:
Here’s another query:
Create a voice summary of my day aheadThis depicts the result:
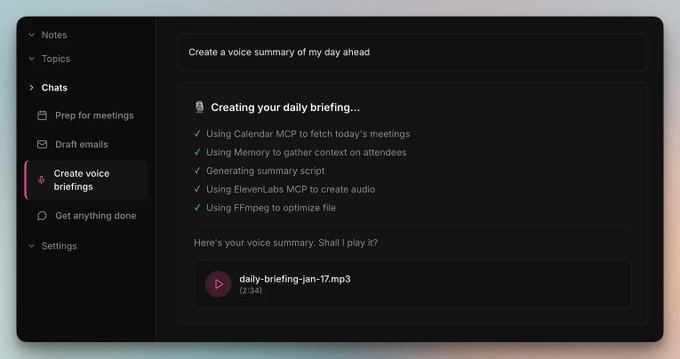
In this case, the Agent pulled today’s meetings from your calendar, gathered context on attendees from the graph, generated a script grounded in your priorities, and handed the audio back as an MP3.
This requires the ElevenLabs or Deepgram integration discussed above for the audio part specifically.
For ongoing tracking, tagging @ rowboat on any note turns it into a live note. Rowboat keeps it updated automatically as new relevant information comes in from connected sources.
For instance, if you’re tracking a deal, a project, or an account across multiple conversations, the note stays current without manual upkeep.
Finally, you can also spin up agents that run on a schedule independently of your queries. You control what runs, when it runs, and what gets written back to the vault.
Knowledge graph evolution over time
As expected, the knowledge graph gets denser with every email and meeting. New signals attach to existing entity nodes rather than creating isolated files.
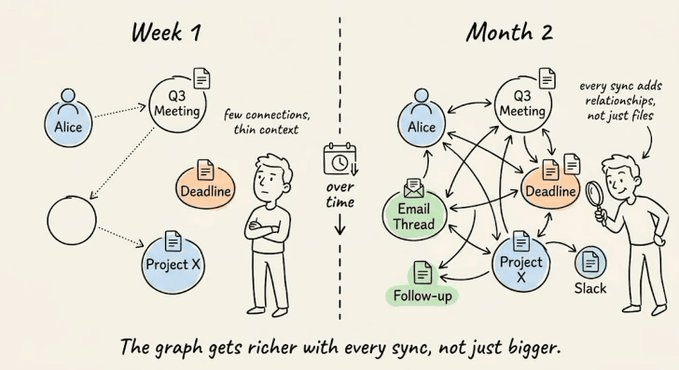
Imagine that Sarah was in the Series B intro call 3 weeks back. That link already exists from day one.
But when she emails term sheet feedback now, that update attaches to the same node as a new line in her activity log.
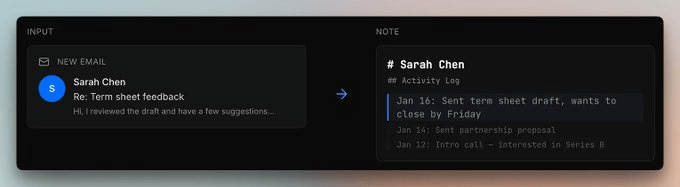
The graph doesn’t create a second “Sarah Chen” file. It extends the existing one.
At month 2, when you query “what has Sarah committed to this quarter,” the Agent traverses connected context across every interaction, not individual threads sitting in separate inboxes.
If you set a live note set on a deal in week one, it stays current because the Agent keeps pulling new relevant context into it automatically.
So you set it once, and the graph maintains it.
This is the structural difference from Karpathy’s wiki pattern. A wiki compiles concepts into pages. A knowledge graph tracks state across conversations, and that state compounds as new interactions link back to existing entities
Rowboat takes the compounding knowledge base Karpathy’s pattern describes and makes it work for the context that actually changes day to day.
It stores everything as plain Markdown in ~/.rowboat/ so nothing is locked into a proprietary format.
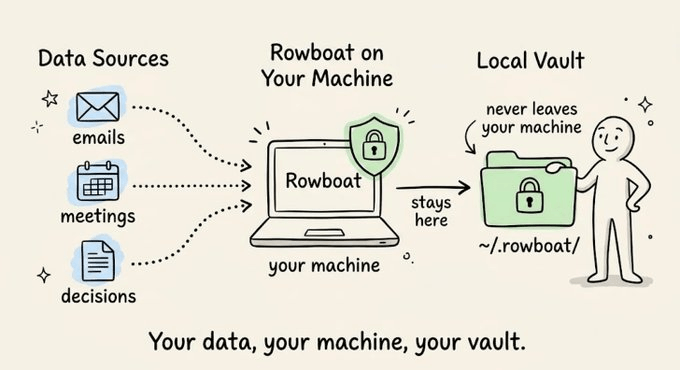
Model calls go to wherever you pointed models. json.
With Ollama, the entire pipeline runs on your hardware.
With a hosted API key, your prompts go directly to that provider under your own account’s terms.
Rowboat doesn’t proxy or intercept model calls.
OAuth credentials for Gmail, Calendar, and Drive live in ~/.rowboat/config/ and call Google’s API directly from your machine. Every integration follows the same architecture, i.e., they are invoked locally and outputs are written to the local vault.
The repo is Apache-2.0 licensed.
GitHub repo here (13k+ stars): github.com/rowboatlabs/rowboat (don’t forget to star it 🌟)
Thanks for reading!