
Building An Enterprise-grade Document Parser
100% local, beats GPT-4o.

Build agentic workflows in plain English
Sim’s Copilot (open-source) is a powerful way to build functional Agentic workflows from plain English. We just describe the workflow, and it builds, edits, and optimizes automatically.
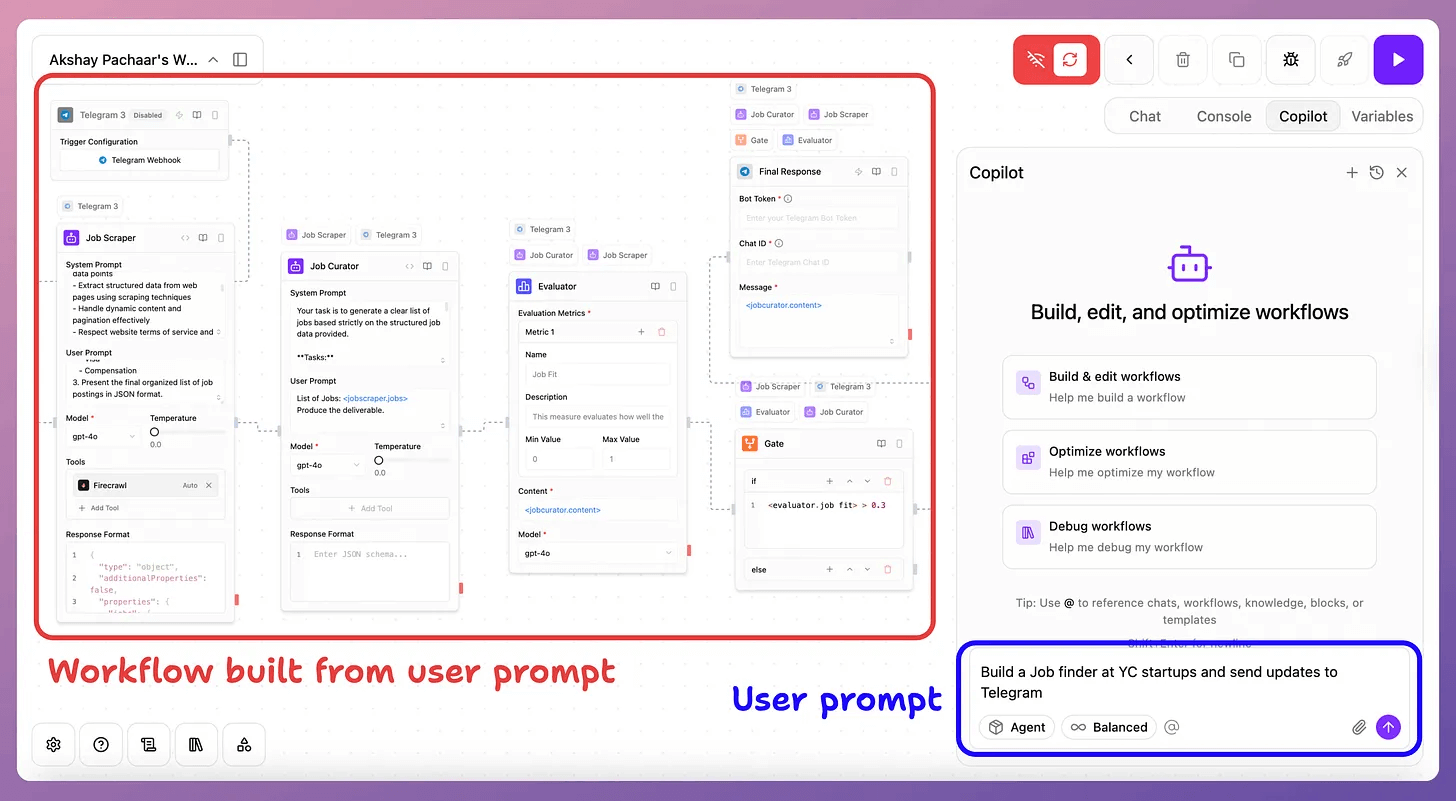
Based on our testing, Sim is a better alternative to n8n with:
An intuitive interface
A much better copilot for faster builds
AI-native workflows for intelligent agents
We also built a demo on this recently. Watch on YouTube here →
Building an enterprise-grade document parser
Today, let’s build a world-class document processing system that can handle complex files packed with tables, figures, and dense text.
It beats OpenAI’s GPT-4o, and we’ll use a fully open-source stack for this:
GroundX for SOTA parsing
Streamlit for UI
Ollama for serving LLM locally
Here’s the workflow:
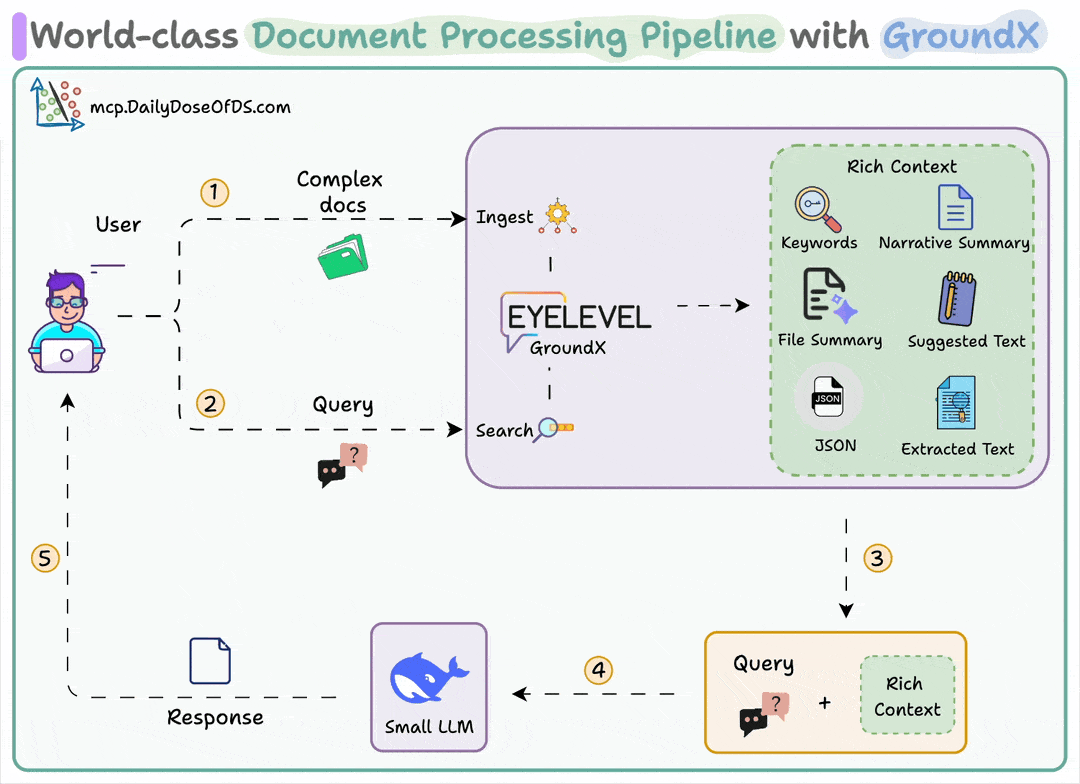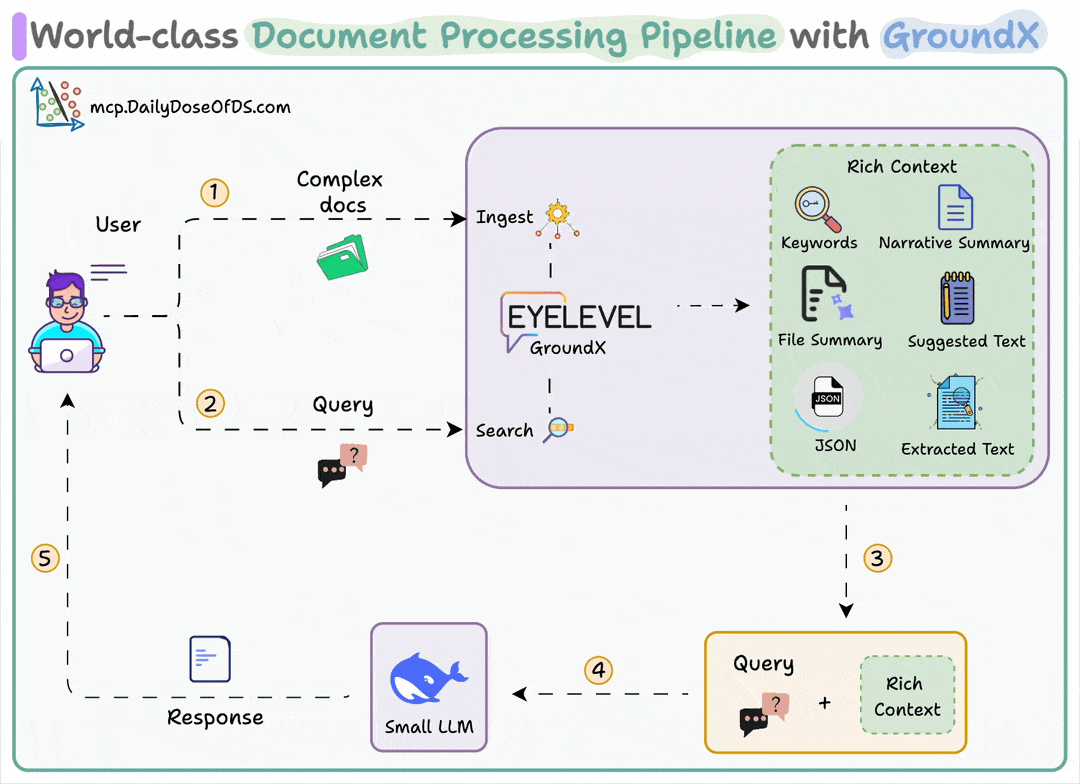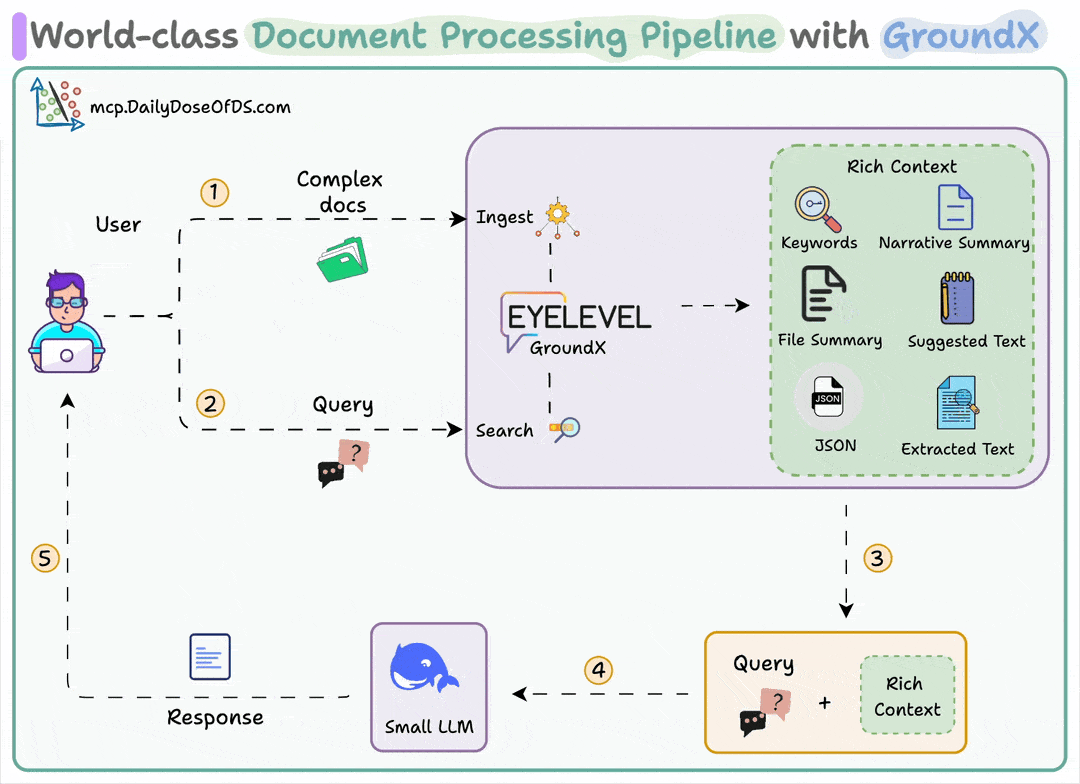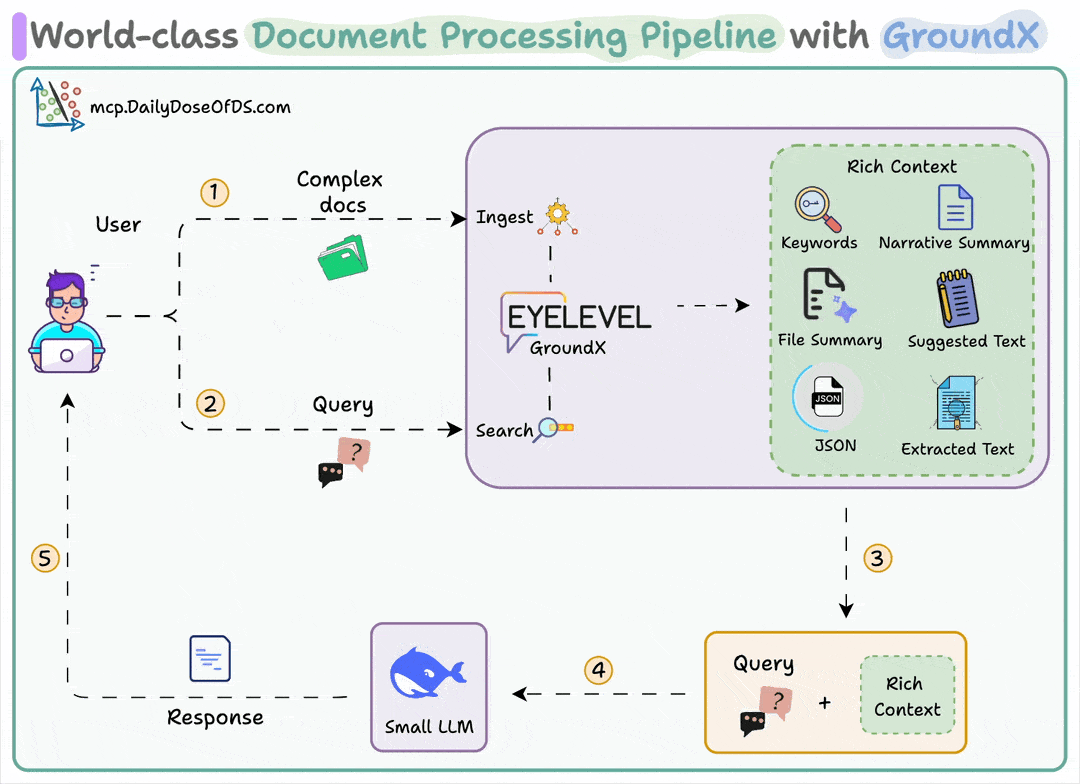
User uploads a document
GroundX parses and provides rich analysis with summaries, chunks, and metadata
A small local LLM uses this context to answer complex questions
Before building this demo yourself, you can quickly test GroundX on your own complex document and see how it works here →
Let’s begin!
Connect to GroundX
In GroundX, every document lives in a bucket. We connect to the API and create one for our workflow.
GroundX can run fully self-hosted in a private Kubernetes cluster. But here we’re using the managed cloud for a quick demo.

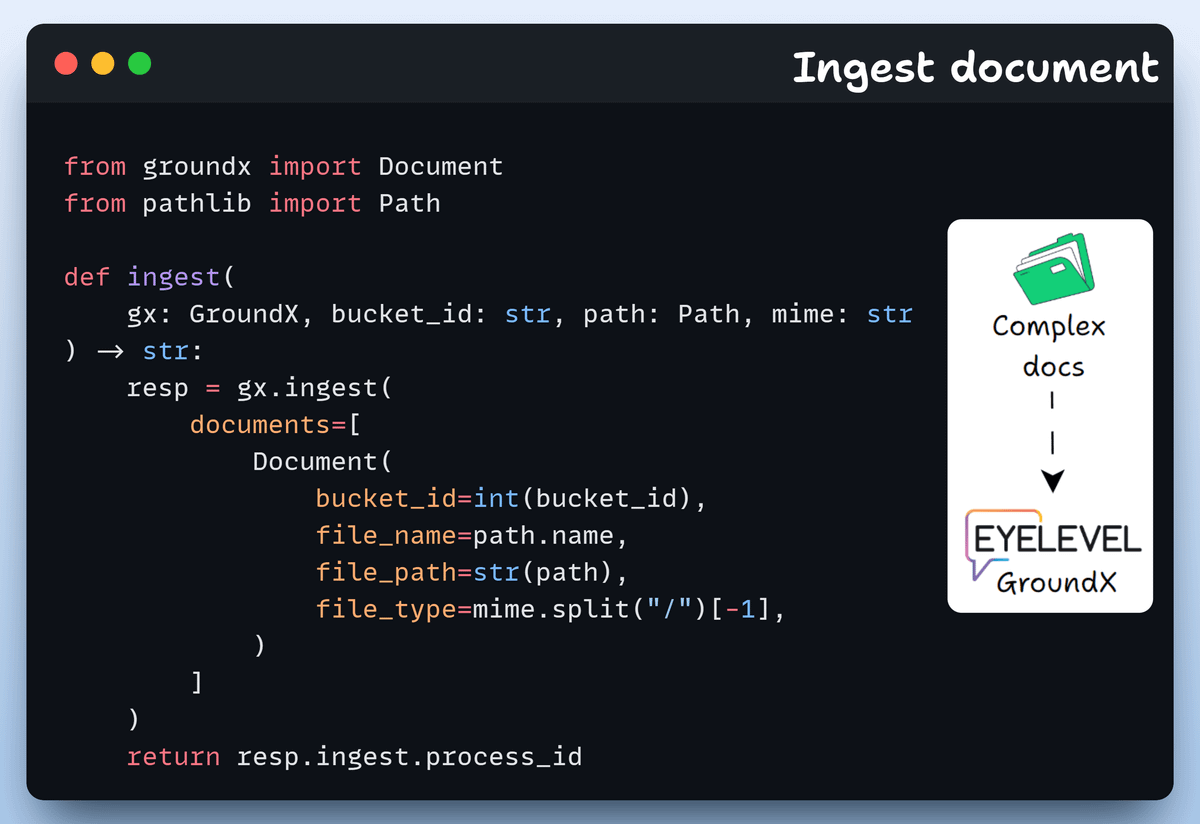
Ingest document
Next, we upload our file to GroundX.
This can be a PDF, Word doc, or even an image. GroundX will handle the parsing.
Fetch X-Ray
Once the document is processed, we fetch its X-Ray outputs packed with:
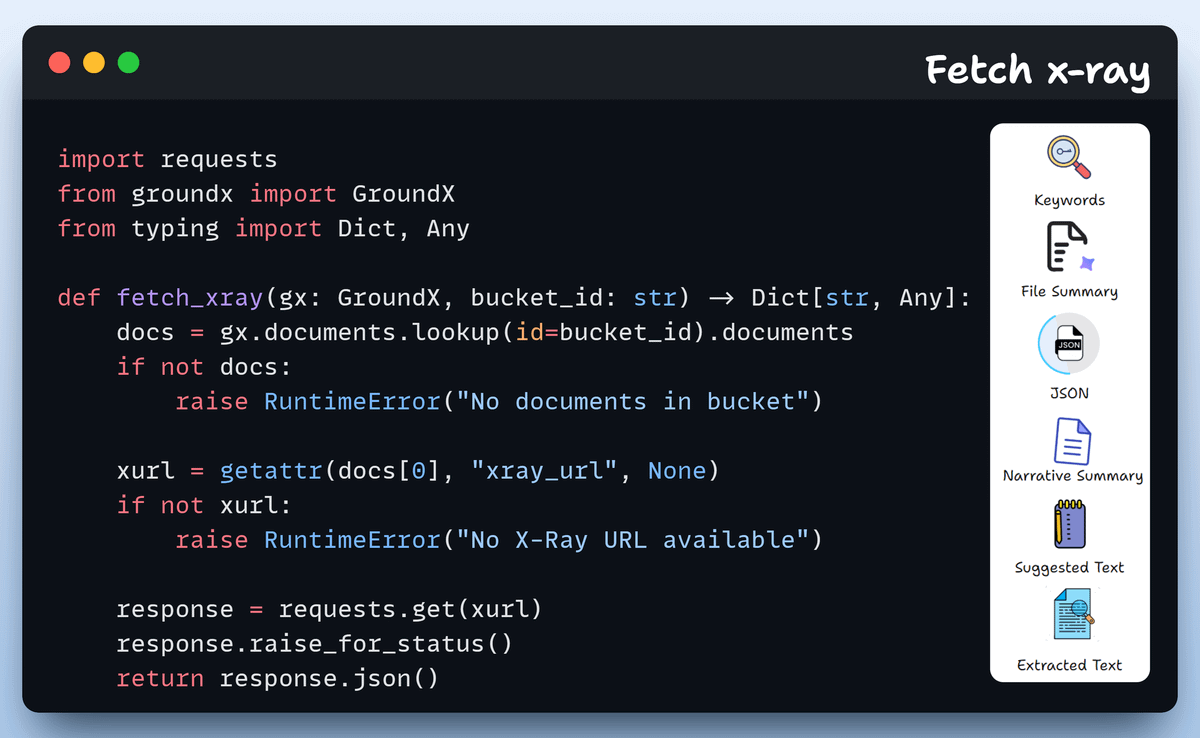
JSON Output
Narrative Summary
File Summary
Suggested Text
Extracted Text
Keywords
Prepare context
Next, we fetch a richer context for the model.

We combine the document’s summary with a few top chunks so the LLM has just enough detail to answer accurately without being overloaded.
Generate response
Now we chat with the document using a small local LLM.
With GroundX’s rich context, even a small LLM like phi3:mini can generate clear, accurate responses, handling complex questions with ease.

Here is the document, the query, and the response generated by our workflow.
To provide the correct answer, GroundX needed to parse and comprehend the entire layout, including tables, and understand how all the information is interconnected.

Finally, we wrap everything up into a clean Streamlit interface to improve accessibility.
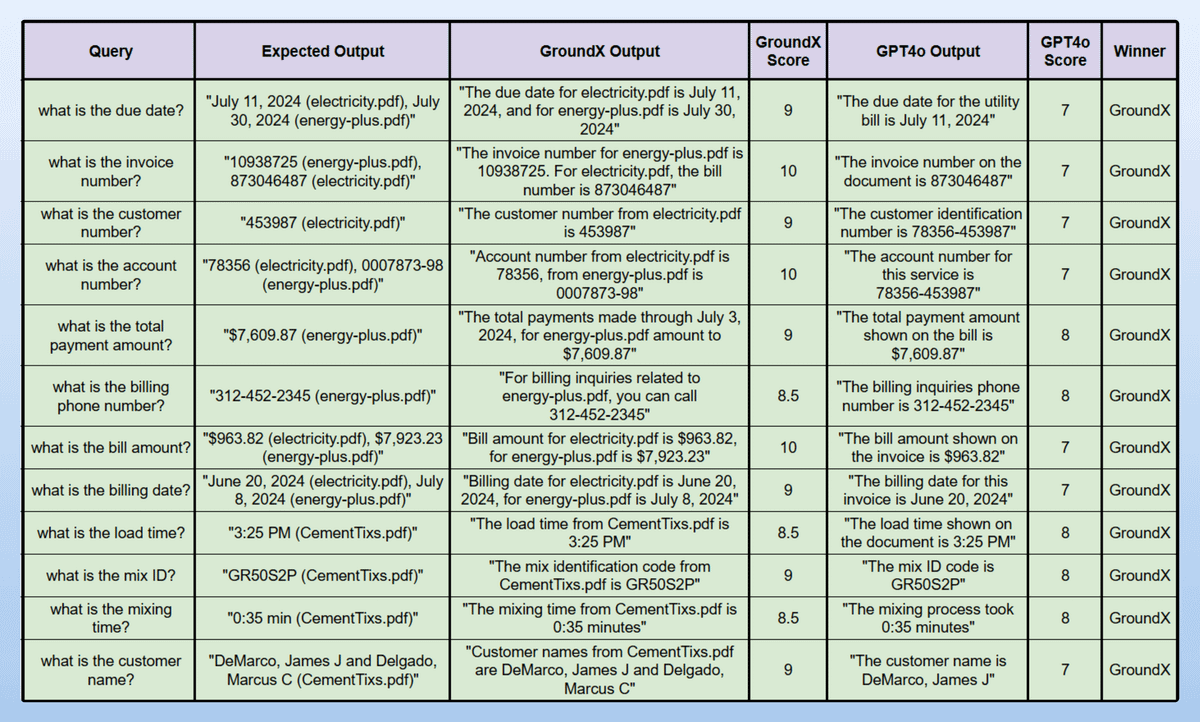
Additionally, we ran parsing evals using Opik comparing GroundX and GPT-4o across 3 different invoices.
GroundX won every time, finding & answering questions specific to the files with added context, while GPT-4o mostly pulled text as-is.
GroundX is open-source, and you can find the GitHub repo here →
The open-source package requires some setup so you can quickly test GroundX on your own complex document and see how it works here →
Thanks for reading!