
Claude Sonnet 4 vs OpenAI o4-mini on Code Generation
...building a full pipeline.

Native RAG over Video in just 5 lines of code!
Most RAG systems stop at text.
But a lot of valuable context lives in spoken words and visuals like calls, interviews, demos, lectures, and it’s tough to build production-grade RAG solutions on them.
Here’s how you can do that in just 5 lines of code with Ragie:

Ingest
.mp4,.wav,.mkv, or 10+ formats.Run a natural language query like “Moments when Messi scored a goal?”
Get the exact timestamp + streamable clip that answers it.
Here’s one of our runs where we gave it a goal compilation video, and it retrieved the correct response:

Top image: ARG vs CRO. It determined there’s a penalty and retrieved the score before and after the penalty.
Bottom image: ARG vs MEX: It fetched the score before the goal and how the goal was scored accurately.
Start building RAG over audio and video here →
Build real-time knowledge graphs for AI Agents

RAG can’t keep up with real-time data.
Graphiti builds live, bi-temporal knowledge graphs so your AI agents always reason on the freshest facts. Supports semantic, keyword, and graph-based search.
100% open-source with 11,000+ stars.
GitHub repo (don’t forget to star the repo) →
Claude Sonnet 4 vs OpenAI o4-mini on Code Generation
Claude Sonnet 4 is the newest reasoning model by Anthropic.
Today, let’s build a pipeline to compare it with OpenAI o4-mini on coding tasks.
We'll use:
LiteLLM for orchestration (open-source).
DeepEval for evaluation (open-source).
AnthropicAI Sonnet 4 and OpenAI o4-mini as LLMs.
Here's our workflow:
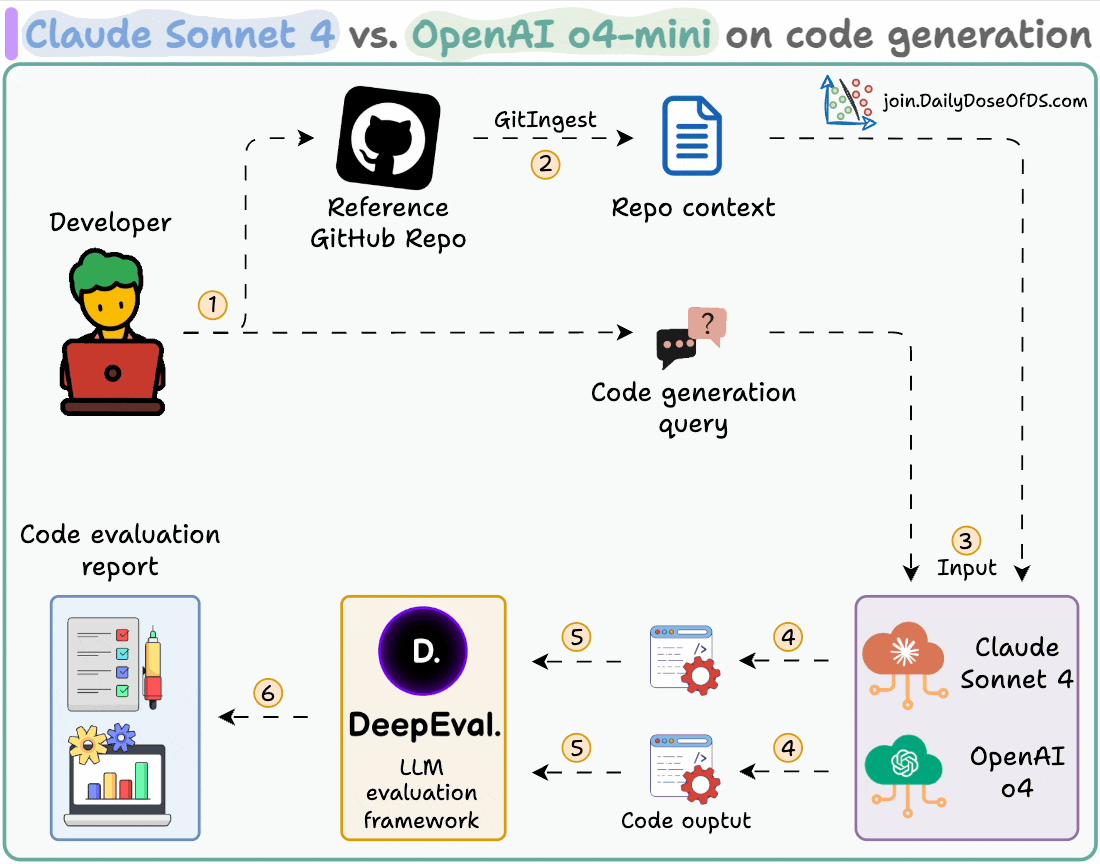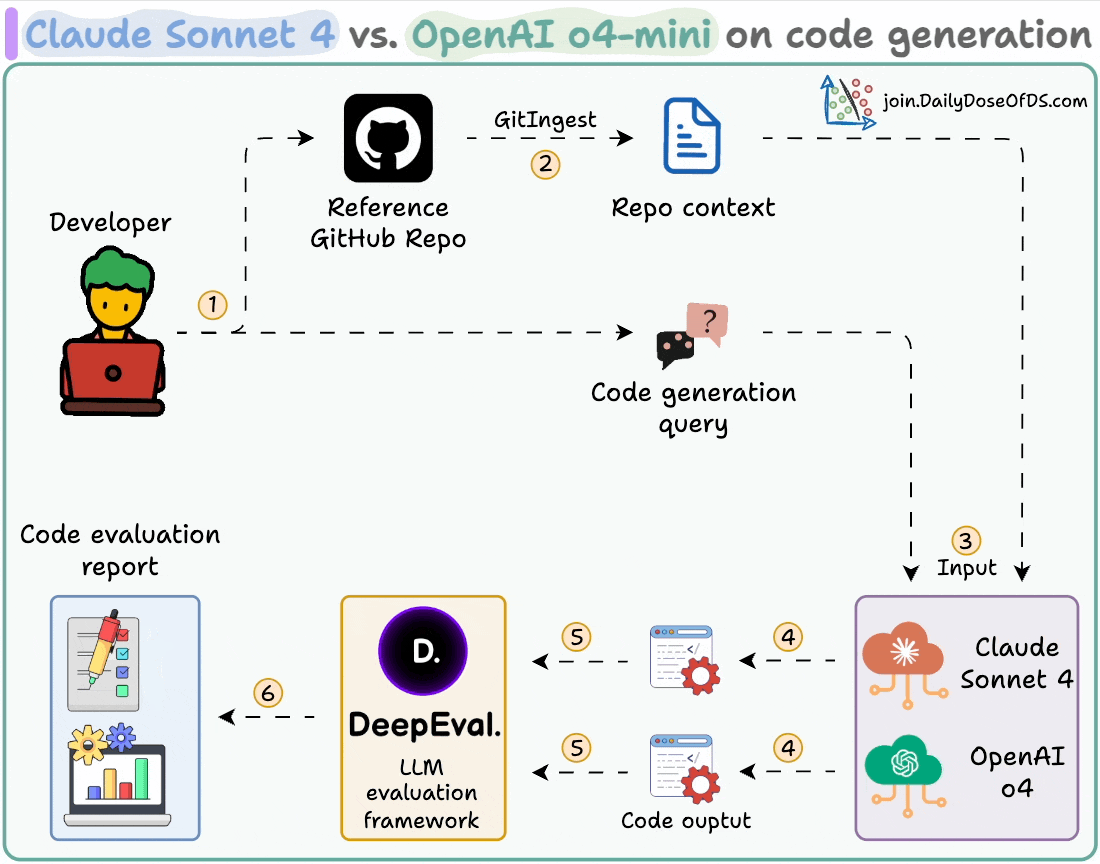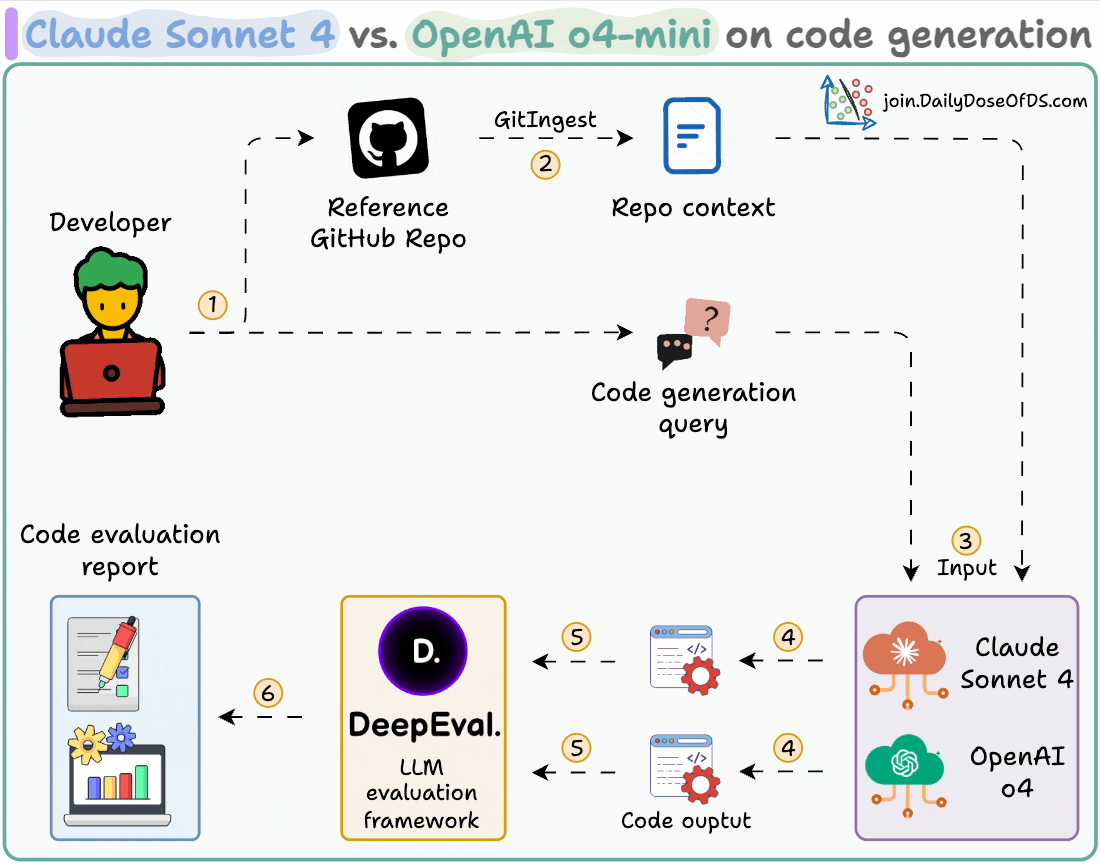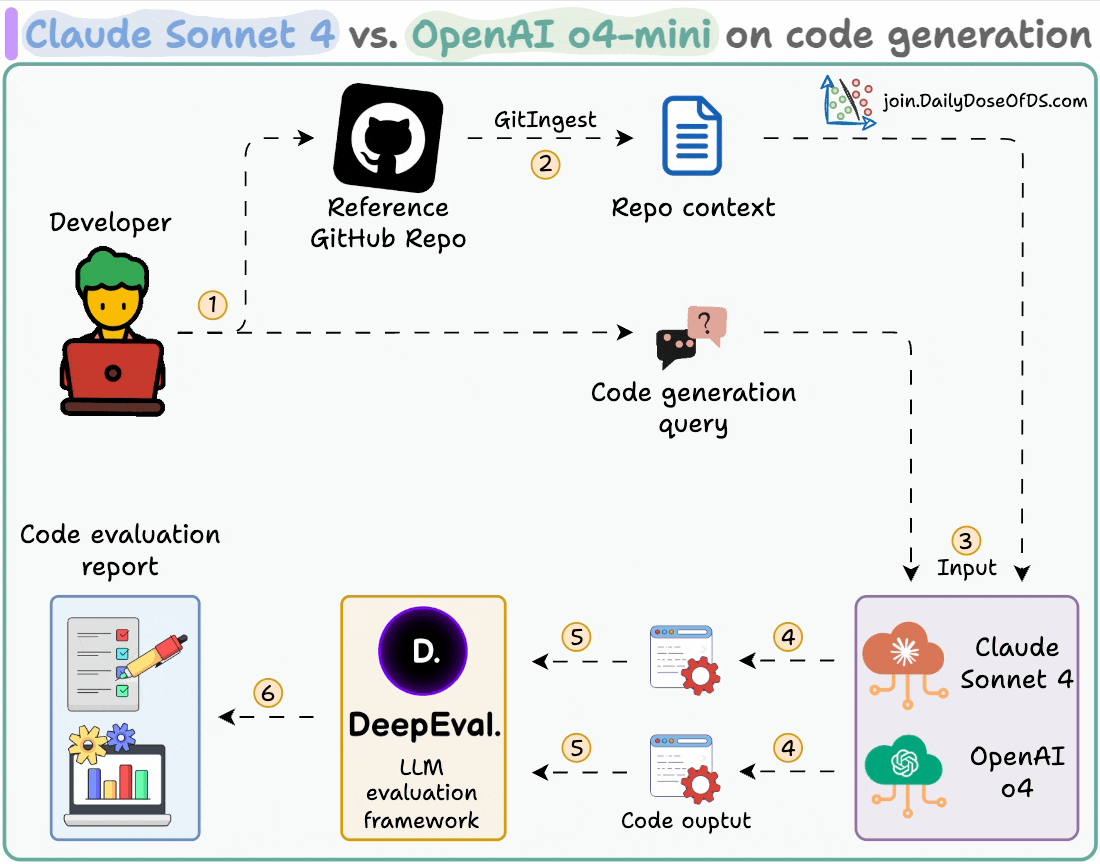
Ingest a GitHub repo and provide it as context to the LLMs.
Generate code using both models.
Evaluate and compare the generated code using DeepEval.
Let’s implement this!
Load API keys
Before we begin, store your API keys in a .env file and load them into your environment.

Ingest GitHub repo
We use GitIngest to turn the user-specified GitHub repo into simple LLM-ready text data.
LLMs will use this as context to answer the user's query.

Code correctness metric
We will now create evaluation metrics for our task using DeepEval.
This metric compares the quality and correctness of the generated code against a reference ground truth code.

Code readability metric
This metric ensures the code adheres to proper formatting and consistent naming conventions.
It also assesses the quality of comments and docstrings that make the code easy to understand.

Best practices metric
This metric ensures that the code is modular, efficient, and implements proper error handling.

Generate model response
Now we are all set to generate responses from both models.
We specify the ingested codebase as context in the prompt, and stream the responses from both models in parallel.

Evaluate generated code
We use GPT-4o as the judge LLM.
It evaluates both responses, produces the metrics declared above, and also provides detailed reasoning for each metric.

Streamlit UI
Finally, we create a nice Streamlit UI that makes comparing and evaluating both models in a single interface easy.
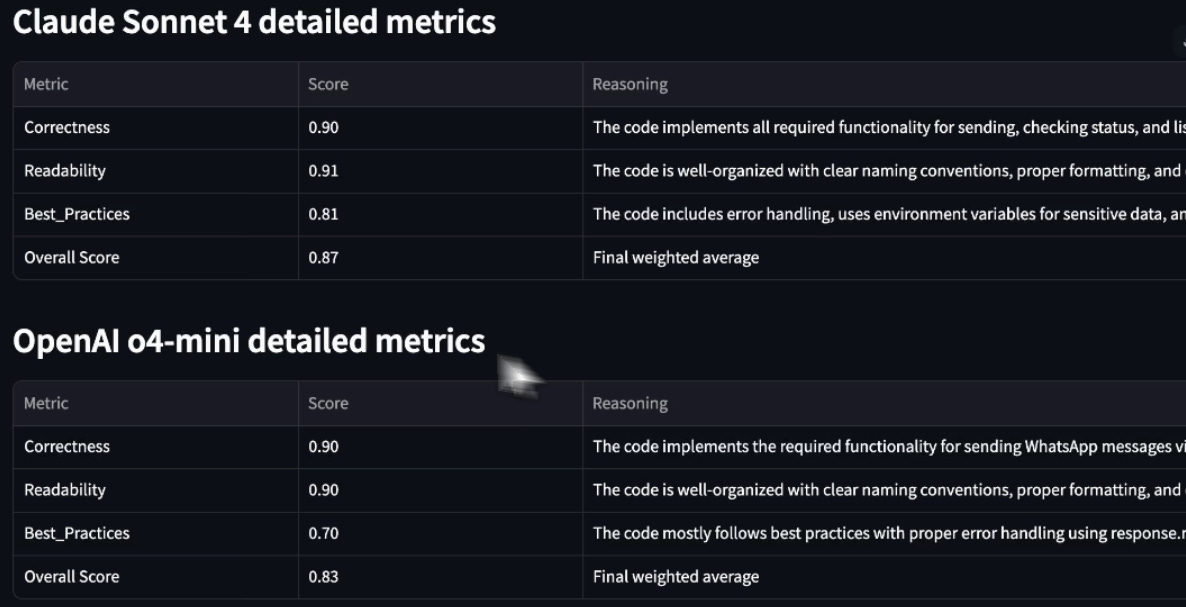
Results across all four metrics suggest that Sonnet 4 is more performant than o4-mini:

During evaluation, we also get specific reasoning insights into the scores, which is immensely useful in such comparisons:
You can find the code for this newsletter issue here →
Thanks for reading!