
Claude Subagents vs. Agent Teams
...explained visually.

The query problem SQL was not designed to solve
SQL was never built for relationship queries.
It works fine for simple lookups. But the moment you need to trace connections across multiple hops, queries become unreadable, slow, and unmaintainable.

FalkorDB is an open-source graph database built on GraphBLAS that handles multi-hop traversals with sub-millisecond latency.
It is available as a Native App within Snowflake, so you can run graph queries directly on your Snowflake data.
Your data stays inside Snowflake the entire time, with no infrastructure to manage or security boundaries to worry about.
Try FalkorDB on the Snowflake Marketplace →
Claude Subagents vs. Agent Teams
Most people reach for multi-agent systems the moment a task feels complex.
That’s almost always the wrong instinct.
The right question isn’t “should I use multiple agents?” but rather “what kind of coordination does this task actually need?”
The answer to that determines everything about your architecture.
Claude gives you two distinct multi-agent paradigms: sub-agents and agent teams. They look similar on the surface. Architecturally, they solve completely different problems.

Sub-Agents: Parallelism through isolation
A sub-agent is a specialized Claude instance that runs in its own isolated context window.
Here’s the mental model: imagine you’re a research lead. You don’t read every primary source yourself. You delegate focused questions to researchers, they come back with distilled findings, and you synthesize everything into a coherent output.
That’s exactly what sub-agents do.
Each sub-agent gets:
Its own system prompt defining its specialty
A specific set of tools it can access
A clean, isolated context window
One job to do
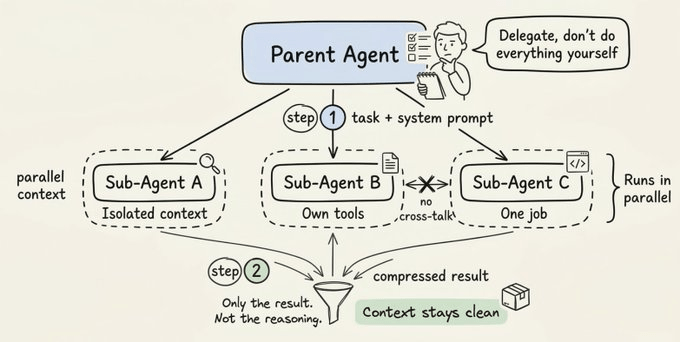
When it finishes, only the final result returns to the parent. Not the full reasoning chain. Not the intermediate steps. Just the compressed output.
The point of sub-agents isn’t just parallelism, it’s compression. You’re distilling a vast amount of exploration into a clean signal, without polluting your parent agent’s context with noise.
One hard constraint: sub-agents can’t spawn other sub-agents, and they can’t talk to each other. Every result flows back to the parent. The parent is the sole coordinator.
This constraint is a feature, not a limitation. It keeps the system predictable. You always know where information flows and where decisions get made.
Here’s a minimal SDK example of defining and invoking sub-agents:
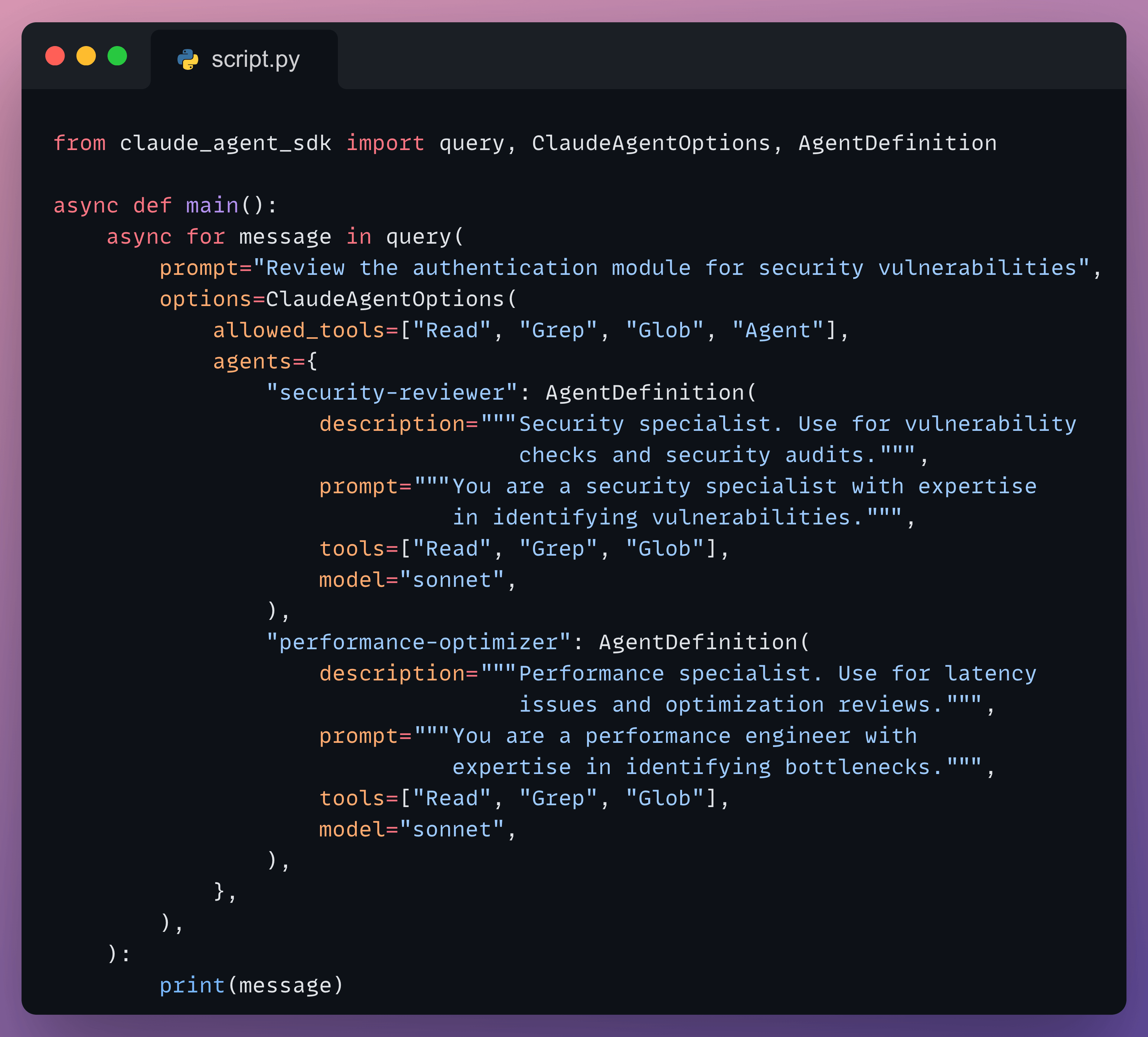
The description field is what tells the parent agent which sub-agent to invoke. Here, the prompt mentions “security vulnerabilities” so the parent routes to security-reviewer, not performance-optimizer. If the prompt had asked about latency or bottlenecks instead, the other agent would have been picked. The description is the routing signal. Keep it specific.
Agent Teams: Coordination through communication
Agent teams are a fundamentally different model.
Where sub-agents are short-lived workers that complete a task and disappear, agent teams are long-running instances that persist, communicate directly with each other, and coordinate through shared state.
Think of it like the difference between hiring contractors for isolated tasks vs. assembling a team that works together in the same room.
An agent team has three moving parts:
A team lead that coordinates work, assigns tasks, and synthesizes results
Teammates that are independent agent instances, each with their own context window, working in parallel
A shared task list that tracks what’s pending, in progress, and done, along with dependencies between tasks
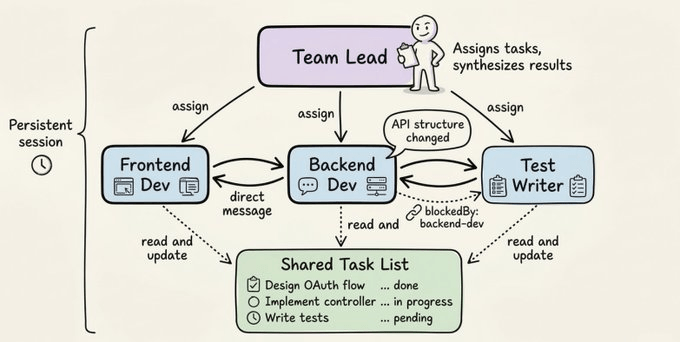
A typical lifecycle looks like this:

Notice the blockedBy field on the test writer. That’s the shared task list doing real coordination work: the test writer won’t start until the backend agent is done, without the lead having to manually manage that sequencing.
The big difference from sub-agents is direct peer-to-peer communication. Teammates can send messages to each other, share findings, surface blockers, and negotiate without routing everything through the lead.
You can also interact with individual teammates directly. You’re not forced to go through the lead agent for everything.
The core distinction: Fire-and-Forget vs. Ongoing coordination
Here’s how to think about the choice between them.
Sub-agents are fire-and-forget.
You give them a task, they complete it, they report back
No conversation between agents
No shared memory, no ongoing state
Each sub-agent lives and dies within a single session
Agent teams are collaborative.
Agents persist and accumulate context over time
Mid-task discoveries surface to teammates immediately
A frontend agent can tell a backend agent “the API response structure needs to change” and the backend agent adjusts without waiting for the lead to mediate
The clearest way to choose between them:
Use sub-agents when your work is embarrassingly parallel: independent research streams, codebase exploration, or lookups where the parent only needs the summary
Use agent teams when your work requires ongoing negotiation: agents that need to reconcile their outputs before proceeding, or where a discovery in one thread changes what another thread should do
How to design Agent systems from first principles
Most multi-agent designs fail because people split work by role instead of by context.
The intuitive instinct is to split by role: planner, implementer, tester. It feels organized. But it creates a telephone game where information degrades at every handoff.
The implementer doesn’t have what the planner knew
The tester doesn’t have what the implementer decided
Quality drops at every boundary
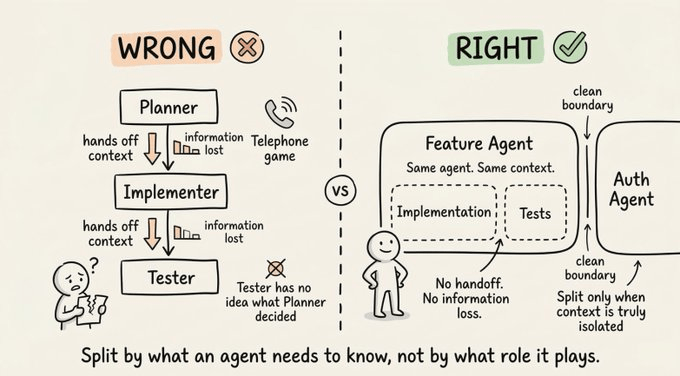
The right mental model is context-centric decomposition.
Ask: what context does this subtask actually need? If two subtasks need deeply overlapping information, they probably belong to the same agent. If they can operate with truly isolated information and clean interfaces between them, that’s where you split.
A practical example: an agent implementing a feature should also write the tests for that feature. It already has the context. Splitting those two into separate agents creates a handoff problem that costs more than the parallelism saves.
Only separate when context can be genuinely isolated.
The five orchestration patterns worth knowing
Regardless of which paradigm you use, these five patterns cover most real-world needs:
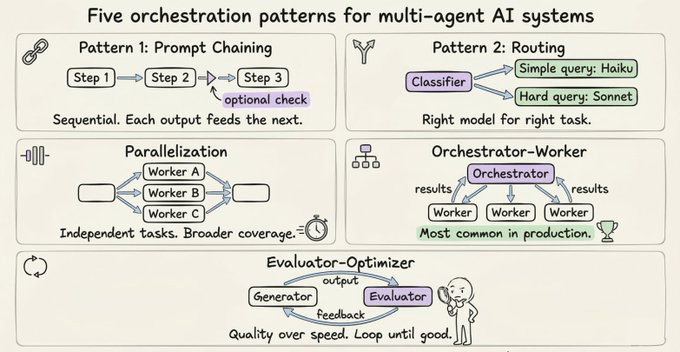
Prompt chaining: Sequential steps where each call processes the previous output. Use when order matters and steps are dependent.
Routing: A classifier decides which specialized handler gets the task. Easy questions go to cheaper, faster models. Hard questions go to more capable ones. This is how you keep costs from exploding.
Parallelization: Independent subtasks run simultaneously. Either the same task runs multiple times for diverse outputs (voting), or different subtasks run at the same time (sectioning).
Orchestrator-worker: A central agent breaks down the task, delegates to workers, and synthesizes results. This is the dominant architecture for both sub-agents and agent teams, and what most production systems actually use.
Evaluator-optimizer: One agent generates, another evaluates and provides feedback in a loop. Useful when quality matters more than speed and a single pass isn’t reliable enough.
When not to use multi-Agent systems at all
This is the part most articles skip.
Teams have spent months building elaborate multi-agent pipelines only to discover that better prompting on a single agent achieved equivalent results.
Start simple. Add complexity only when you can clearly measure that it’s needed.
Multi-agent systems earn their cost in three situations:
Context protection: A subtask generates information irrelevant to the main task. Keeping it in a sub-agent prevents context bloat.
True parallelization: Independent research or search tasks that benefit from simultaneous coverage.
Specialization: The task requires conflicting system prompts, or one agent is juggling so many tools that its performance degrades.
They’re the wrong call when:
Agents constantly need to share context with each other
Inter-agent dependencies create more overhead than execution value
The task is simple enough that one well-prompted agent handles it
One specific warning for coding: parallel agents writing code make incompatible assumptions. When you merge their work, those implicit decisions conflict in ways that are hard to debug. Sub-agents for coding should answer questions and explore, not write code simultaneously with the main agent.
What makes Multi-Agent systems actually fail
Three failure modes show up constantly.
1. Vague task descriptions cause agents to duplicate each other’s work.
Every agent needs a clear objective, an expected output format, guidance on what tools or sources to use, and explicit boundaries on what it should not cover. Without this, two agents will research the same thing and neither will notice.
2. Verification agents declare victory without verifying.
Explicit, concrete instructions are non-negotiable: run the full test suite, cover these specific cases, do not mark as complete until each one passes. Vague approval criteria produce false positives.
3. Token costs compound faster than you expect.
The solution is to tier your models intelligently:
Use your most capable model where it genuinely matters
Route routine work to faster, cheaper models
Build in budget controls so costs can’t run away unchecked
The one design principle that actually matters
Design around context boundaries, not around roles or org charts.
Start with a single agent. Push it until you find where it breaks. That failure point tells you exactly what to add next.
Add complexity only where it solves a real, measured problem.
To learn more...
We did a crash course to help you implement reliable Agentic systems, understand the underlying challenges, and develop expertise in building Agentic apps on LLMs, which every industry cares about now.
Here’s everything we did in the crash course (with implementation):
In Part 1, we covered the fundamentals of Agentic systems, understanding how AI agents act autonomously to perform tasks.
In Part 2, we extended Agent capabilities by integrating custom tools, using structured outputs, and we also built modular Crews.
In Part 3, we focused on Flows, learning about state management, flow control, and integrating a Crew into a Flow.
In Part 4, we extended these concepts into real-world multi-agent, multi-crew Flow projects.
In Part 5 and Part 6, we moved into advanced techniques that make AI agents more robust, dynamic, and adaptable, like Guardrails, Async execution, Callbacks, Human-in-the-loop, Multimodal Agents, and more.
In Part 7, we covered Knowledge of agentic Systems.
In Part 8 and Part 9, we primarily focused on 5 types of Memory for AI agents, which help agents “remember” and utilize past information.
In Part 10, we implemented the ReAct pattern from scratch.
In Part 11, we implemented the Planning pattern from scratch.
In Part 12, we implemented the Multi-agent pattern from scratch.
In Part 13 and Part 14, we covered 10 practical steps to improve Agentic systems.
In Part 15, Part 16 and Part 17, we covered practical ways to optimize the Agent’s memory in production use cases.
Thanks for reading!