
Clean ML Datasets With Cleanlab
...in just 4 lines of Python code.

Generate code for any research paper using Factory!
Many research papers do not provide open-source code. Here’s a simple 2-step process to turn any paper into code:
Download the PDF of the paper (eg, DeepSeek-R1)
Give it to Factory to implement a fully modular and working code.
Factory gives you Droids that handle the entire workflow: they take tickets, plan solutions, write and test code, and open production-ready PRs—using your actual tools and codebase.
Here’s one of our test runs where we asked the Droids to implement the DeepSeek model using its PDF:
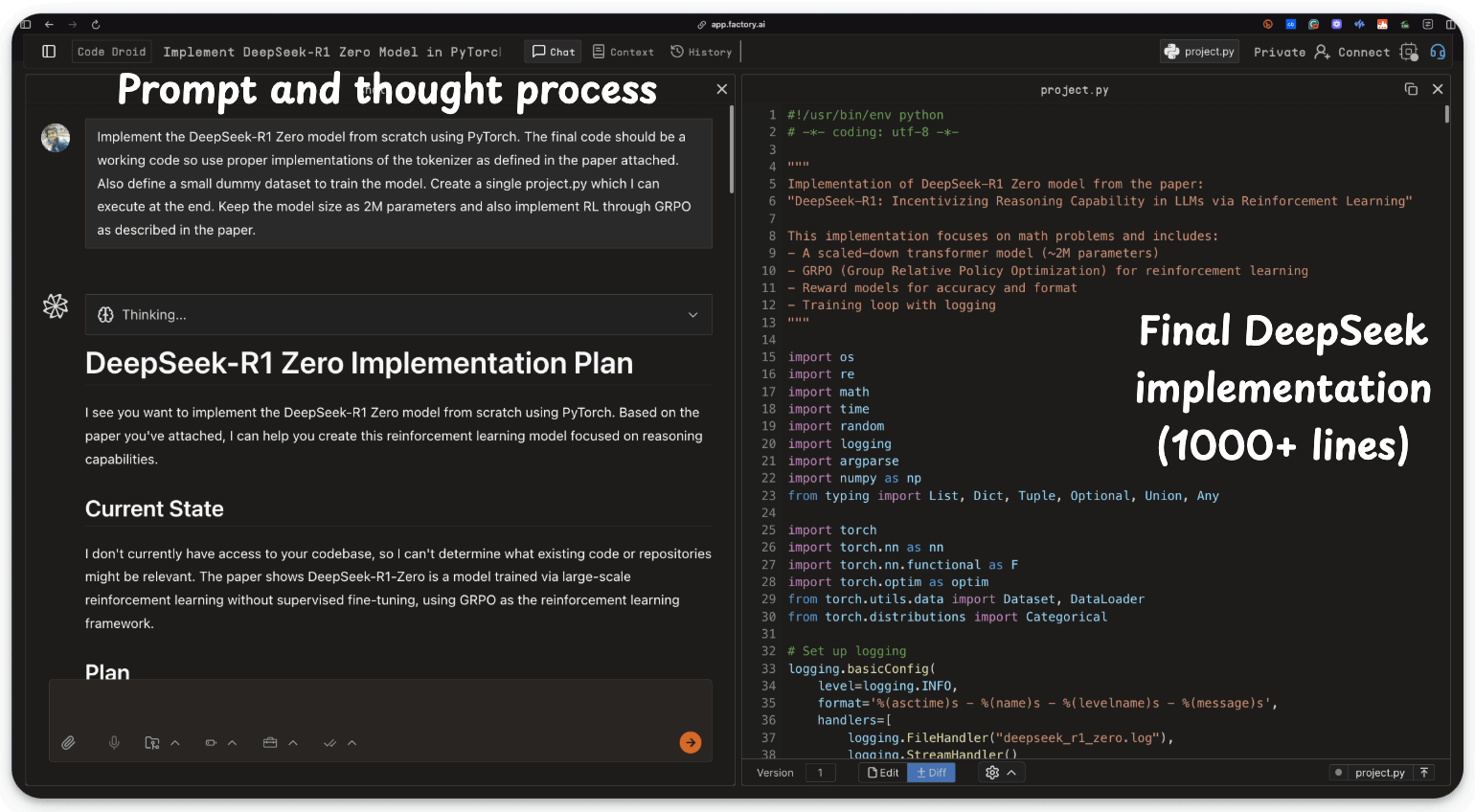
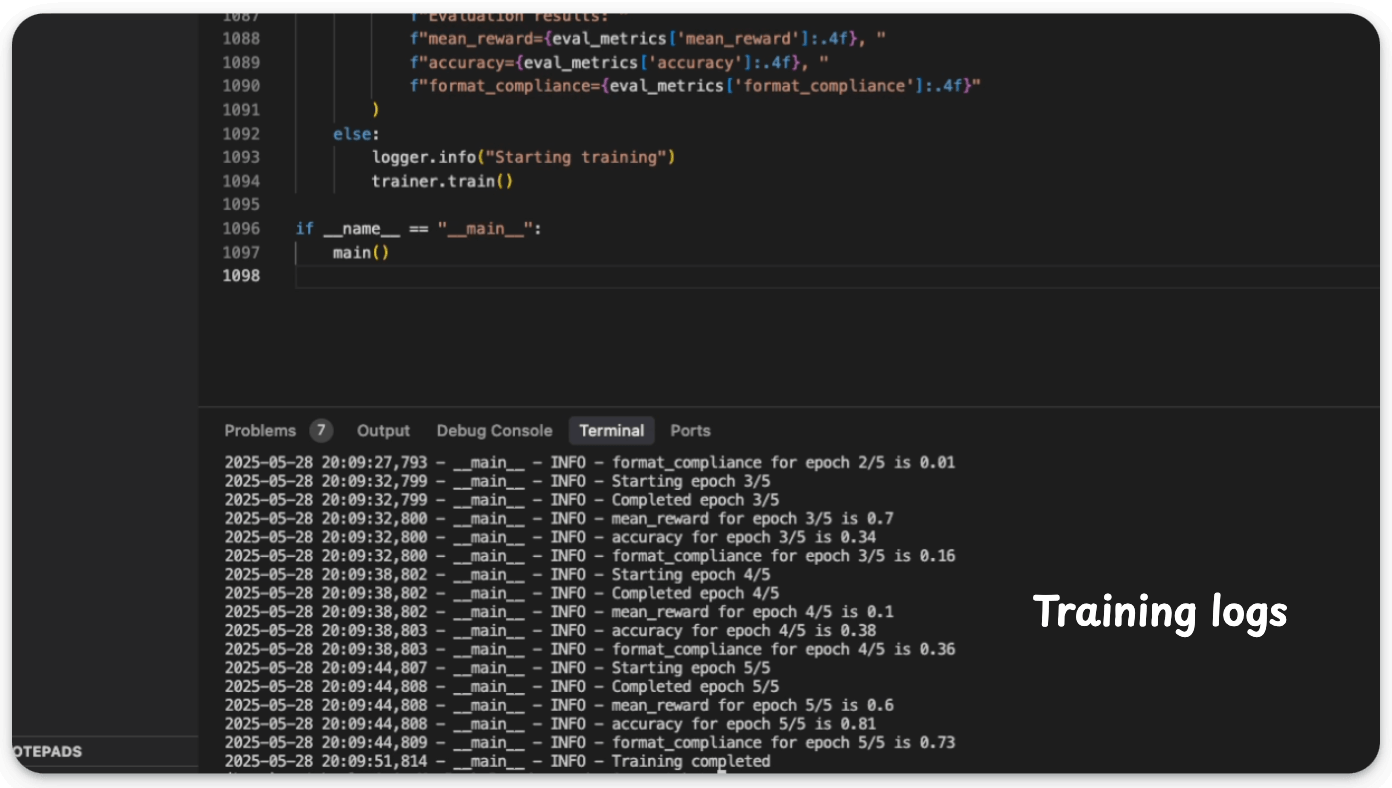
And it did it perfectly:
Start turning paper into code →
Clean ML Datasets With Cleanlab
For the longest time, no one could get past the 91% accuracy on ImageNet (92.4% is quite recent).

This happened because ImageNet had over 100k mislabeled images.
Real-world datasets are messy—noisy labels, missing values, and outliers, that severely degrade your model’s performance.
No sophisticated ML algorithms can compensate for poor-quality data.

Researchers from MIT developed Cleanlab, which is an open-source library that cleans your data in just a few lines of code.

As shown in the image above, Cleanlab can flag errors in any type of data (text, image, tabular, audio), like:
out-of-distribution samples
outliers
label issues
duplicates, etc.
All it takes is just four lines of code:

Import the package.
Pass the dataset and specify the label column.
Find issues by passing the embedding matrix and the probabilities predicted by the model.
Finally, generate the report!
Done!
It will generate a report like the one shown above.
This way, you can easily clean your datasets for training accurate ML models.
Several notebook demos are available here if you want to learn more: Cleanlab demo.
Cleanlab GitHub repo: GitHub repository
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.