
Comparing the Top Open-source OCR Solutions
100% local evaluation app you can run.

Comparing the Top Open-source OCR Solutions
We compared the top open-source OCR solutions and found which one works the best.
This evaluation features:
DeepSeek OCR
Datalab Chandra
Qwen3-VL
Dots OCR
Granite Docling
We also created an app that allows you to run all these OCR models in one place.
The video below details our process and the whole evaluation done using DeepEval:
Datalab Chandra came out to be the winner as per our evaluations, which supports 40+ languages and seamlessly handles text, tables, and formulas.
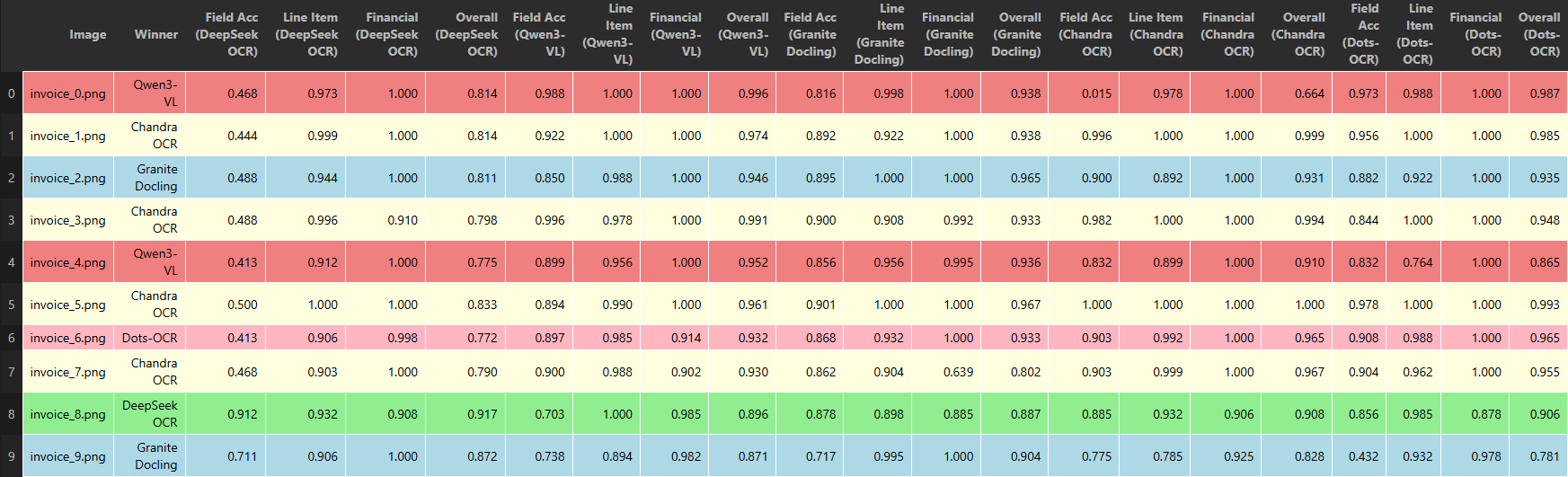
Everything is 100% open-source, and you can run it fully locally.
The Chandra OCR GitHub repo is available here →
The code for this evaluation is available here →
Thanks for reading!
Online hackathon for Agent Builders ($30k in prizes)!

Encode Club is running an AI Agents Hackathon starting January 13th, and the theme is interesting: Build AI Agents that help people actually stick to their New Year’s resolutions.
$30,000 in prizes across six categories: productivity, health, financial wellness, personal growth, and social impact.
Moreover, the “Best Use of Comet Opik” track ($5,000) rewards teams that implement proper evaluation and observability in their AI systems. This is because most AI agent projects fail in production due to no systematic way to track experiments, measure performance, or improve quality with data.
You also get workshops from Comet’s team on agent optimization, plus credits from Google and Vercel.
It’s completely online and free to participate.
Thanks to Comet for partnering today!
These all requires big GPUs. Is there any open source OCR models that we can use on free tier Google colab or Kaggle notebooks ?