
Component-level Evals for LLM Apps
Hands-on guide with code.

In today's newsletter:
Build any MCP server in two steps.
Component-level evals for LLM apps.
KV caching in LLM, explained visually.
Build any MCP server in two steps
Here's the easiest way to build any MCP server:
Download the FastMCP repo with GitIngest.
Factory's Droids handle the entire workflow to generate production-ready code with README, usage, error-handling—everything!
Here’s one of our test runs where we asked the Droids to build a stock analysis MCP server in Factory:
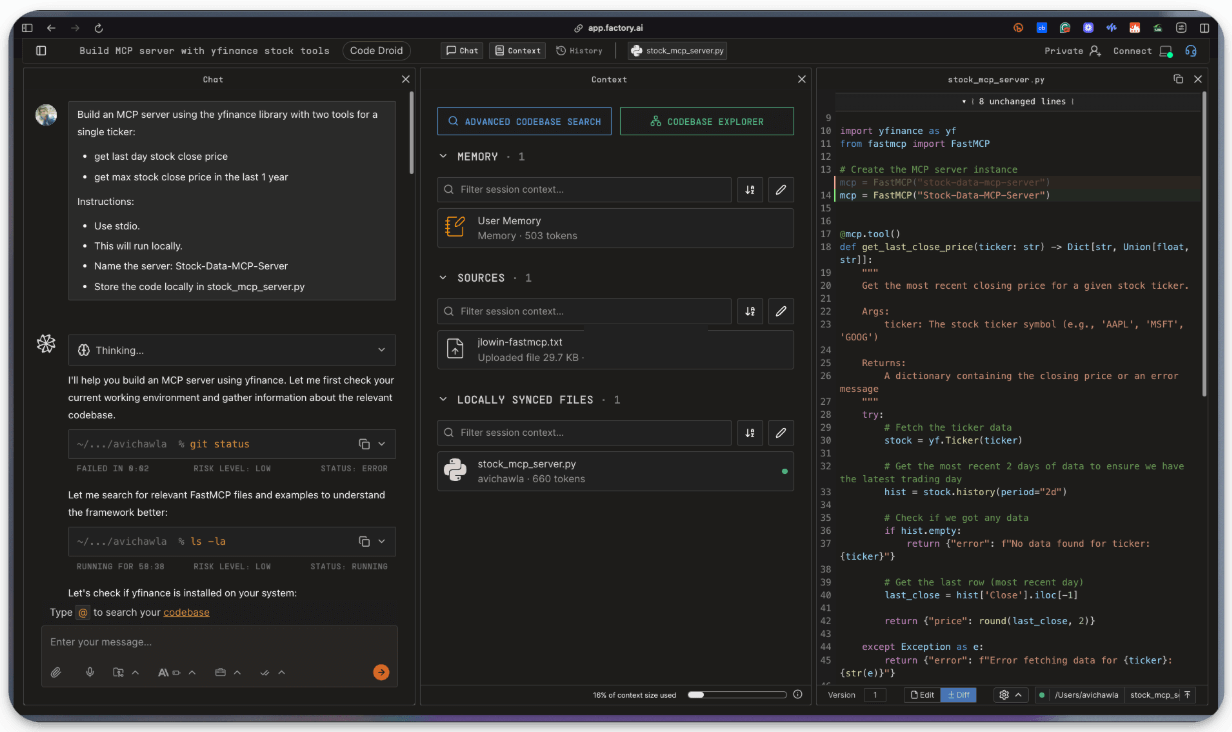
And it did it perfectly with zero errors, while creating a README and usage guide, and implementing error-handling, without asking:

Build your own MCP server here →
Component-level Evals for LLM apps
Most LLM evals treat the app like a black box.
Feed the input → Get the output → Run evals on the overall end-to-end system.

But LLM apps need component-level evals and tracing since the issue can be anywhere inside the box, like the retriever, tool call, or the LLM itself.
In DeepEval (open-source), you can do that in just three steps:
Trace individual LLM components (tools, retrievers, generators) with the
@observedecorator.Attach different metrics to each part.
Get a visual breakdown of what’s working on a test-case-level and component-level.
See the example below for a RAG app:
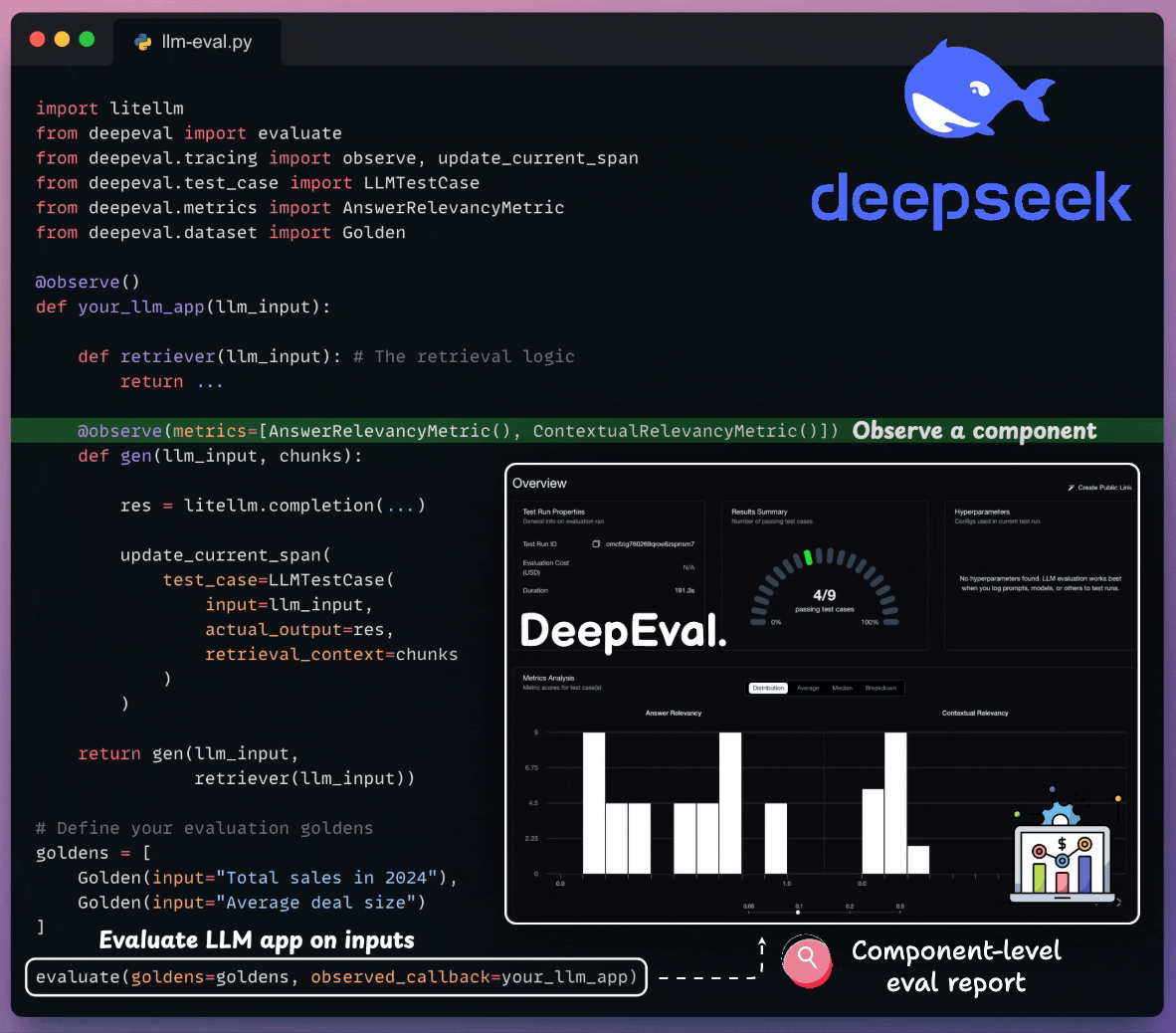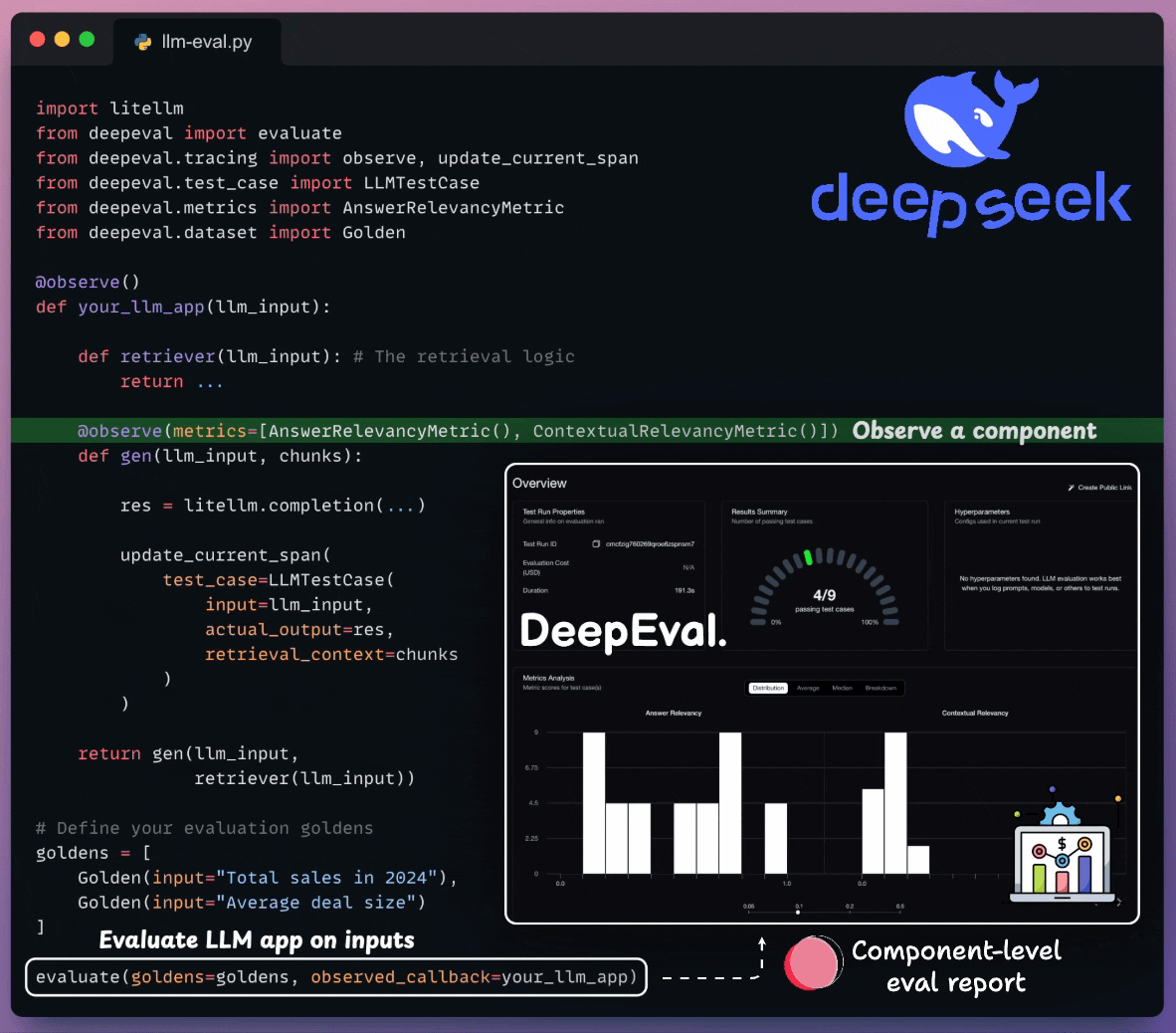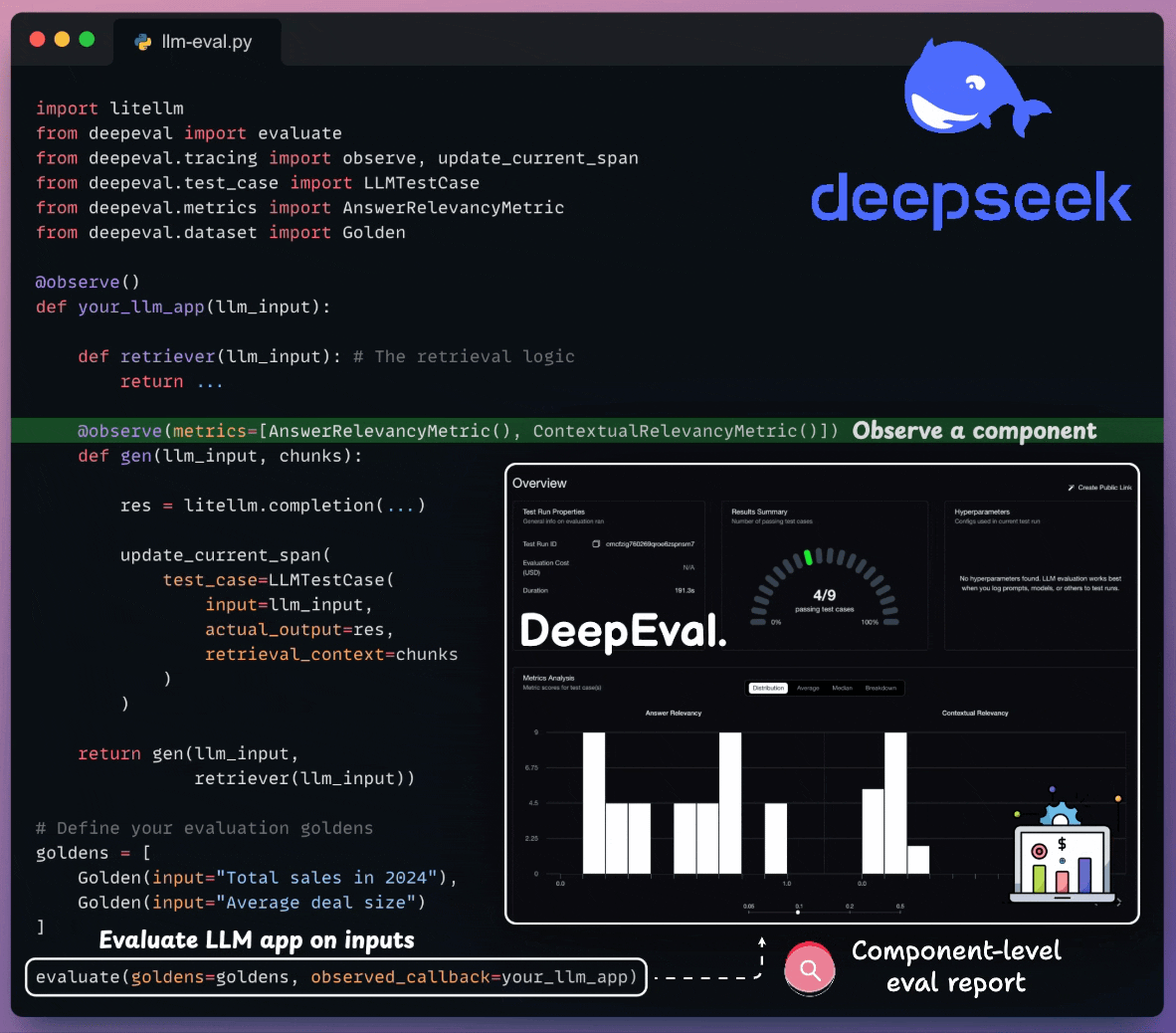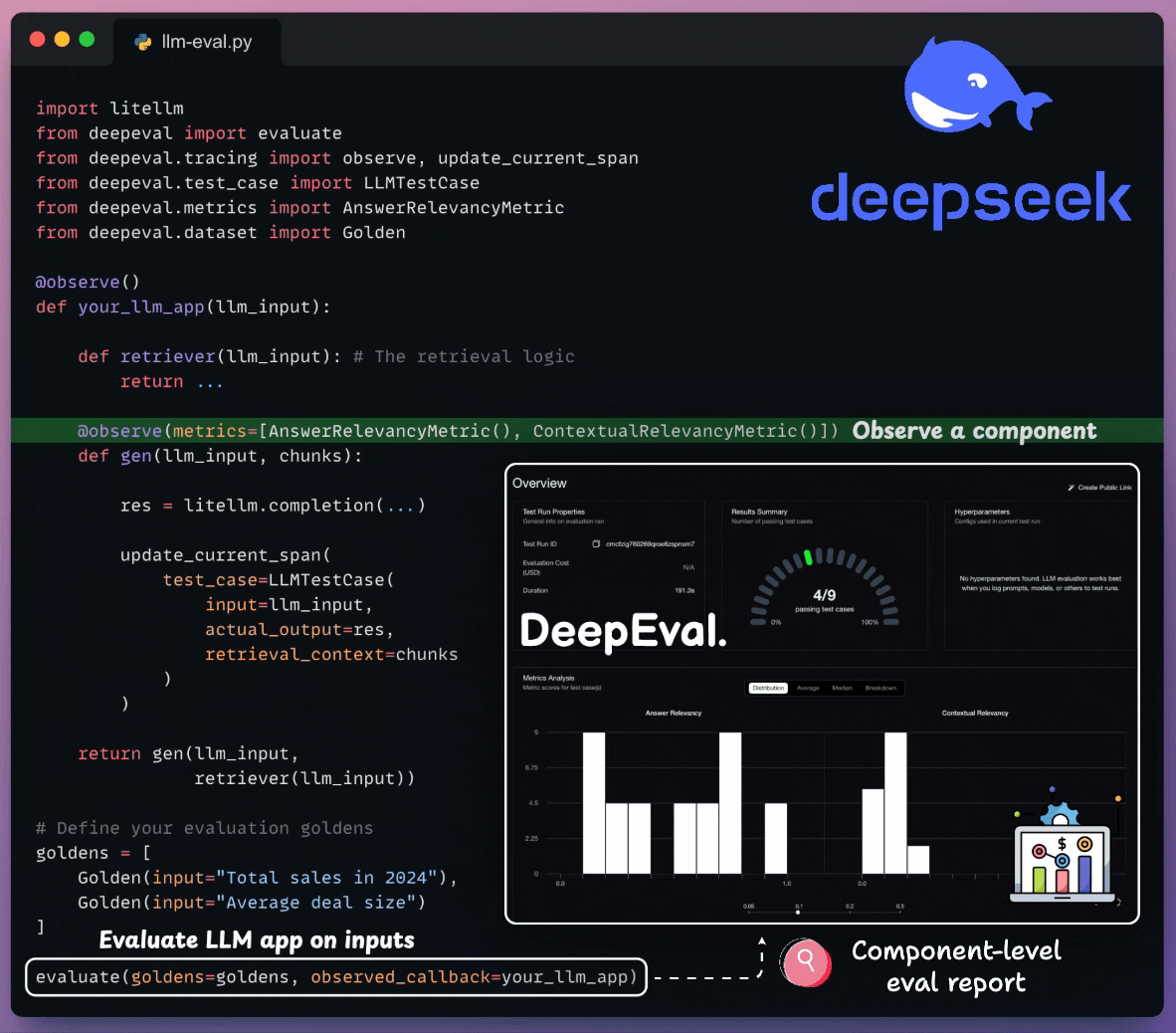
Here’s a quick explanation:
Start with some standard import statements:

Define your LLM app in a method decorated with the
@observedecorator:

Next, attach component-level metrics to each component you want to trace:

Done!
Finally, we define some test cases and run component-level evals on the LLM app:
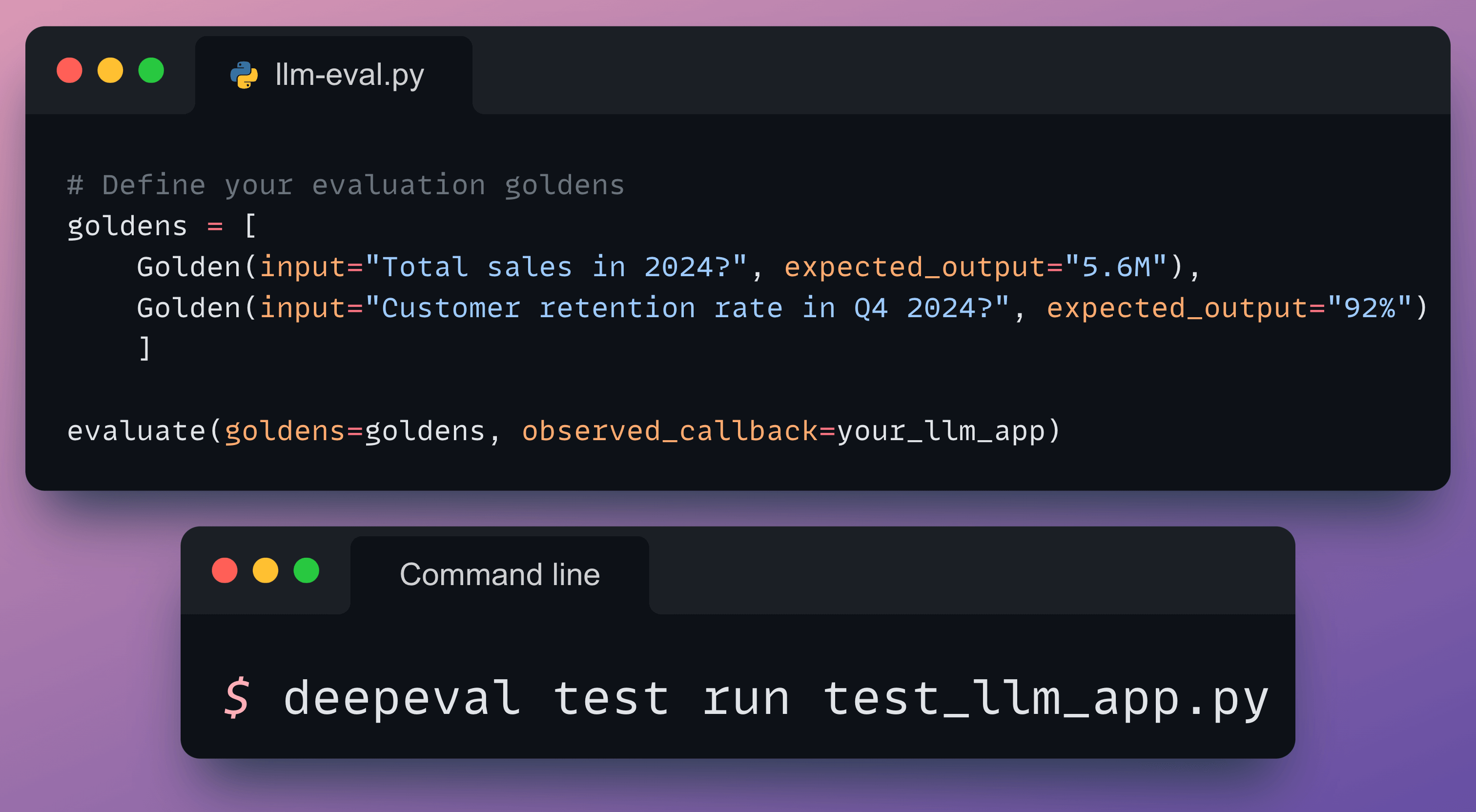
This produces an evaluation report:

You can also inspect individual tests to understand why they failed/passed:

There are two good things about this:
You don't have to refactor any of your existing LLM app’s code.
DeepEval is 100% open-source with 8500+ stars, and you can easily self-host it so your data stays where you want.
You can read about component-level evals in the documentation here →
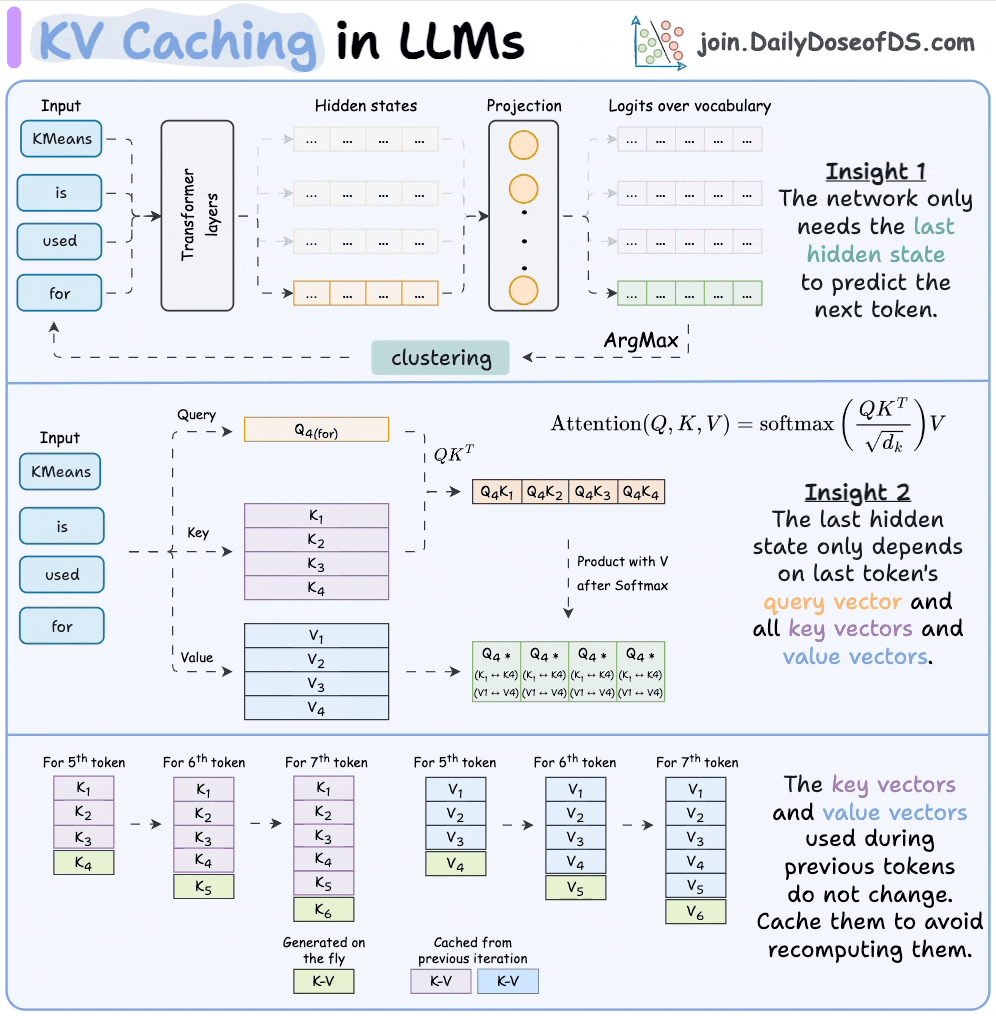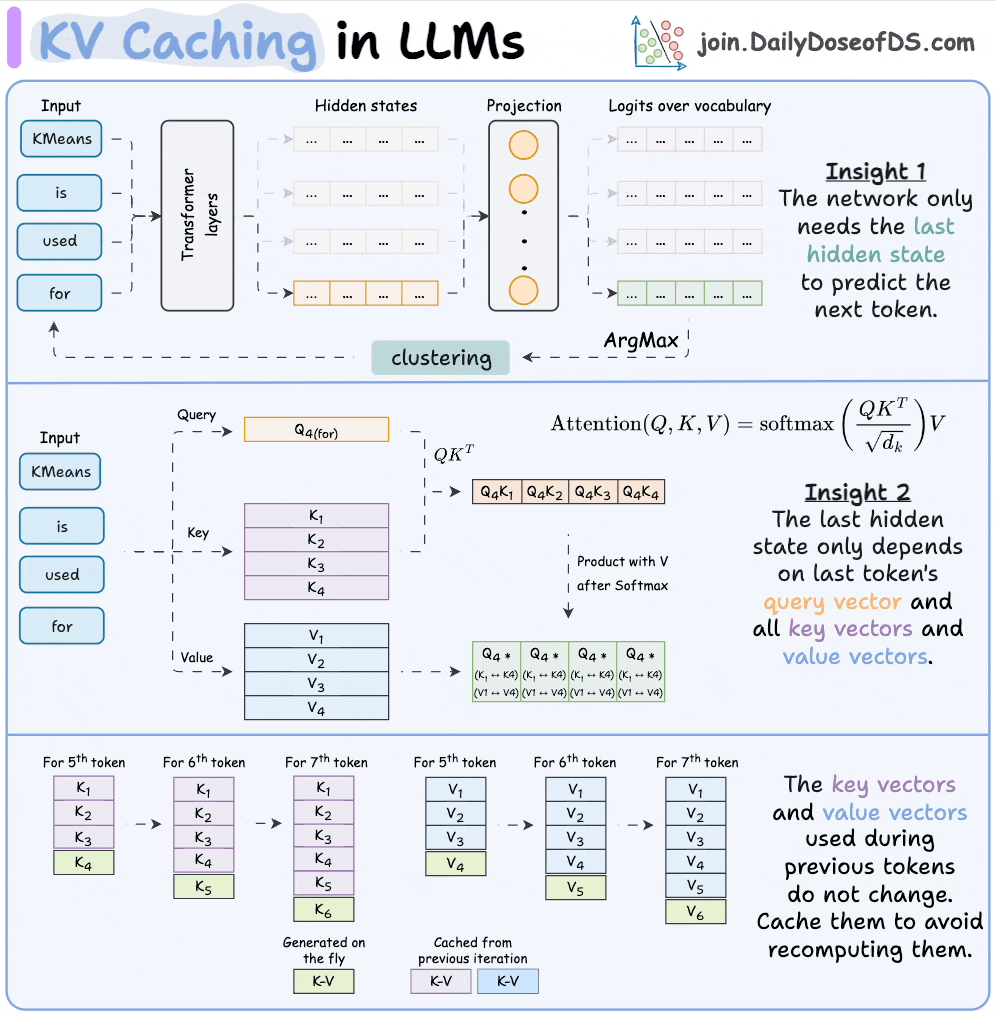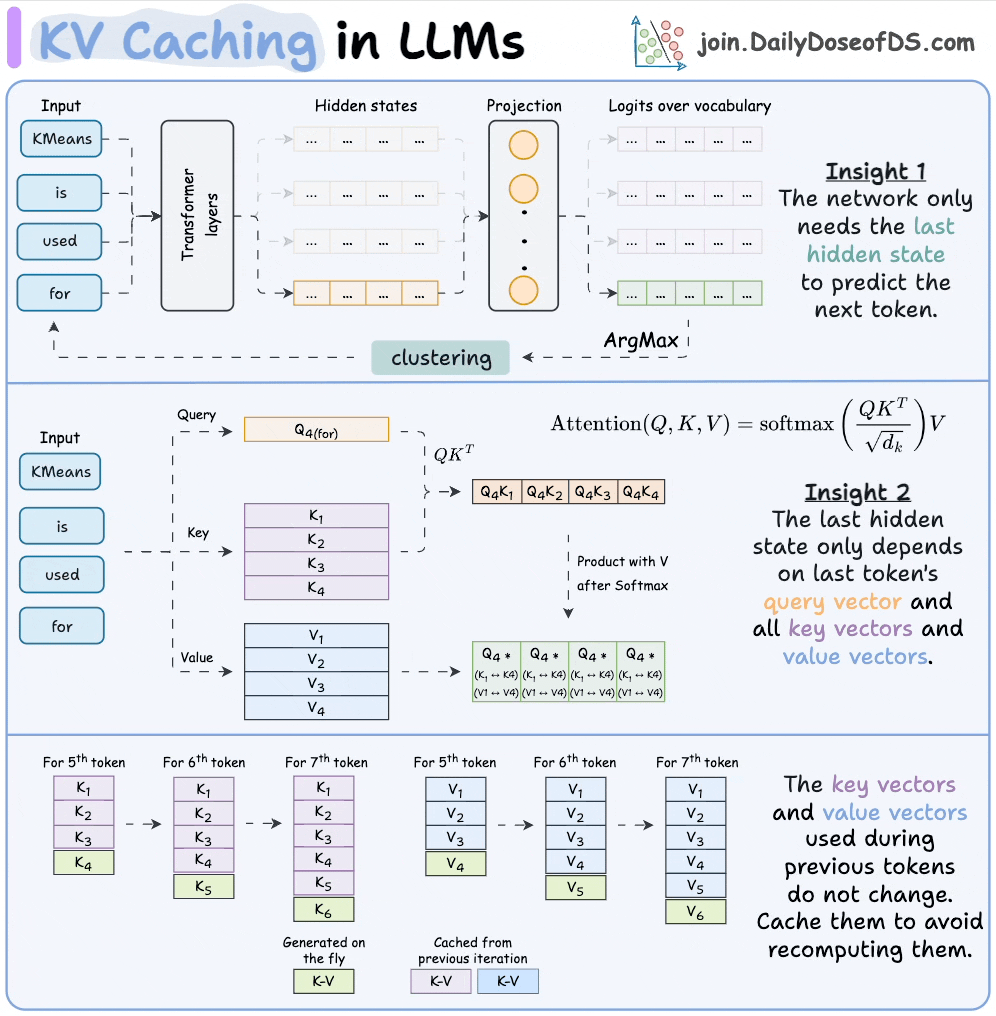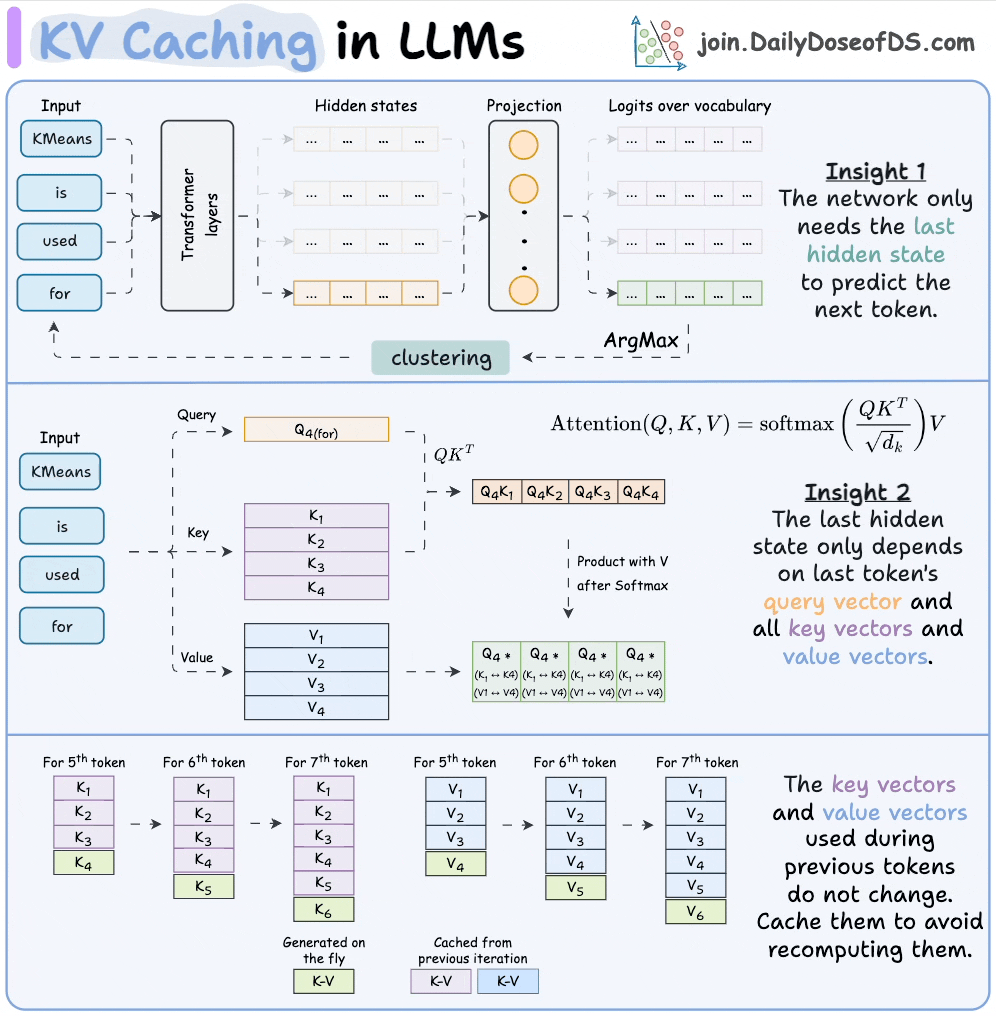
KV caching in LLMs, explained visually
KV caching is a popular technique to speed up LLM inference.
To get some perspective, look at the inference speed difference from our demo:

with KV caching → 9 seconds
without KV caching → 40 seconds (~4.5x slower, and this gap grows as more tokens are produced).
The visual explains how it works:
We covered this in detail in a recent issue here →
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.