
Concepts of LLM Serving in LLMOps
...covered with API-based access, inference with vLLM, and practical decisions.

DailyDoseofDS is now on Instagram!

This newsletter regularly breaks down RAG architectures, AI agents, LLM internals, and everything in between.
Now we’re bringing all of that to Instagram too, in a format that’s quick to consume and hard to ignore.
We’re already 240 posts deep with content on RAG vs HyDE, agentic RAG, specialized AI models, prompt techniques, Bayesian optimization, active learning, and a lot more.
You can find the account and follow it here →
Concepts of LLM Serving
After covering LLM inference optimization in the full LLMOps course, we now move to the fundamentals of LLM serving.
Read Part 14 of the full LLMOps course here →
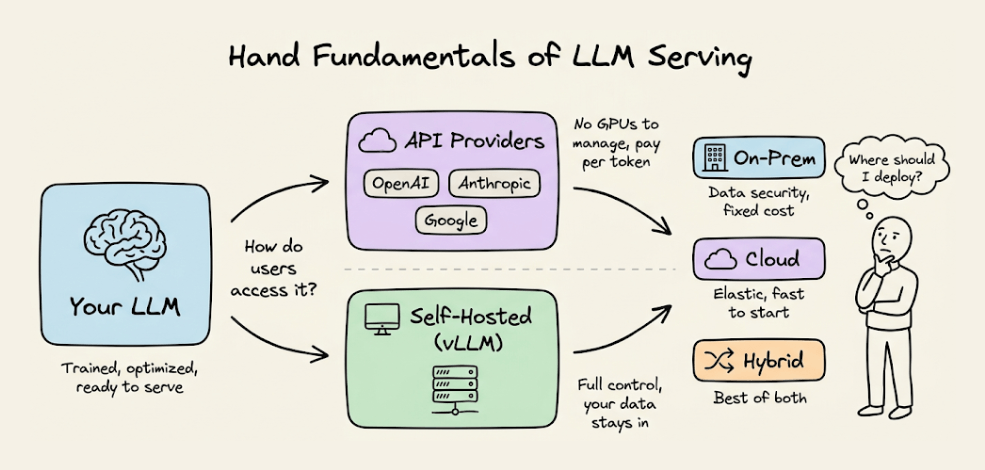
It covers how to actually make a language model accessible as a service: API-based providers vs. self-hosted inference, deployment topology decisions (on-prem, cloud, hybrid), serving with vLLM, and the practical trade-offs that determine how your LLM runs in production.
Read Part 14 of the full LLMOps course here →
Why care?
Optimizing inference (the previous chapter) is about making a single model run faster. Serving is about making that model reliably available to users.
These are different problems. You can have the most optimized inference stack in the world, but if your serving layer cannot handle concurrent users, if cold starts block requests, if you have no strategy for scaling up and down, none of that optimization matters in practice.
The serving layer is where engineering decisions directly translate into user experience and cost. Choosing between API providers and self-hosting changes your cost structure, latency profile, and data privacy posture. Choosing between on-prem and cloud changes your operational burden and scaling flexibility.
This chapter gives you the conceptual framework to make these decisions thoughtfully, along with hands-on experience serving models with vLLM.
Read Part 2 on understanding the core building blocks of LLMs →
Read Part 11 on evaluation of multi-turn systems, tool use evaluations, tracing, and red teaming →
Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!