
Contextualized Chunk Embedding Model
Cut vector DB costs by ~200x.

AI Agents Illustrated Guidebook!
So many people have resonated and liked what we have been writing about and building with Agents, LLMs, etc.

Therefore, we decided to compile these tutorials into one place, which includes:
Agent fundamentals
LLM vs RAG vs Agents
Agentic design patterns
Building Blocks of Agents
Building custom tools via MCP
12 hands-on projects for AI Engineers
Access here on Google Drive →
Projects covered:
Agentic RAG
Voice RAG Agent
Multi-agent Flight Finder
Financial Analyst
Brand Monitoring System
Multi-agent Hotel Finder
Multi-agent Deep Researcher
Human-like Memory for Agents
Multi-agent Book Writer
Multi-agent Content Creation System
Documentation Writer Flow
News Generator
You can access the book here on Google Drive →
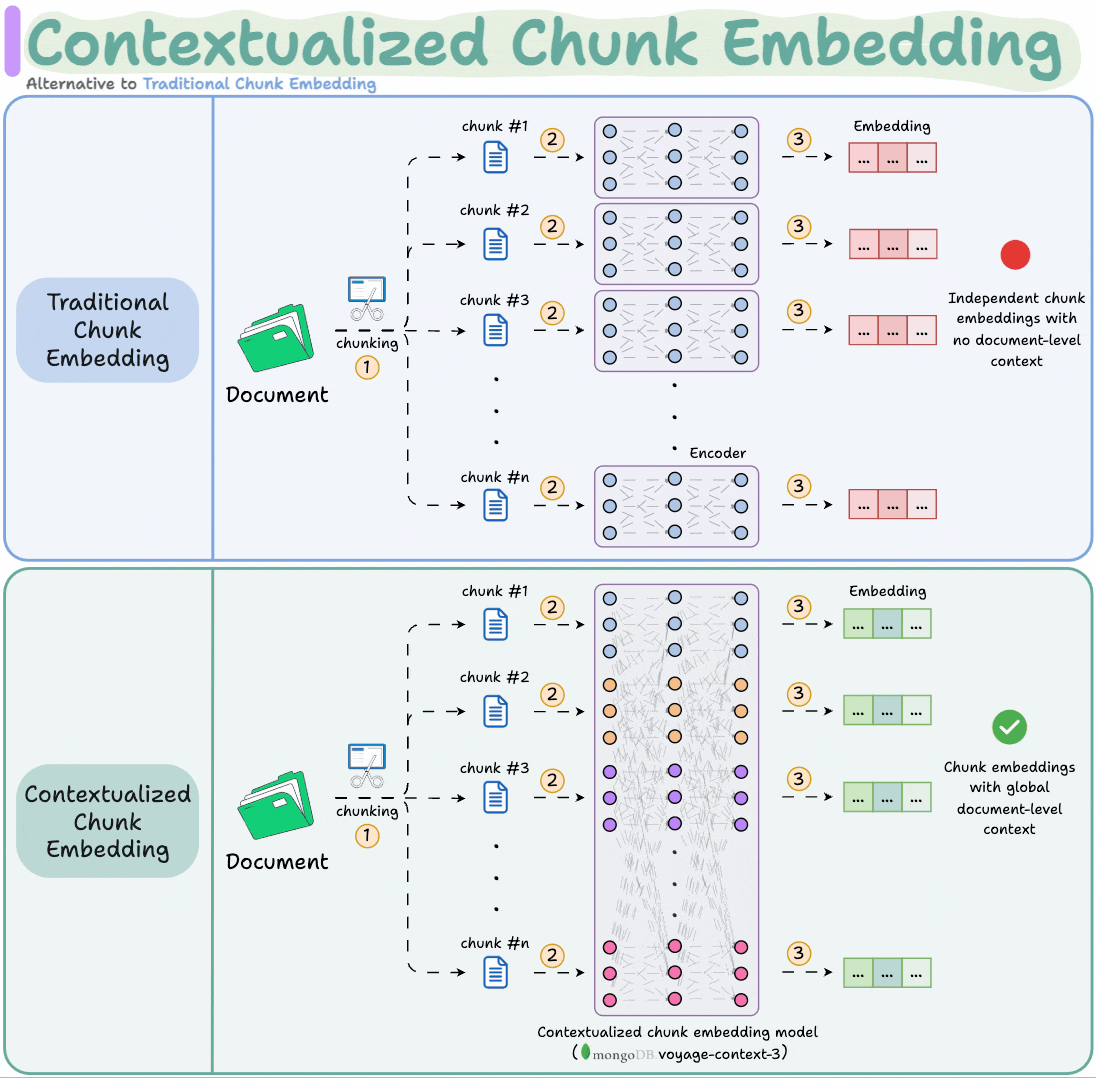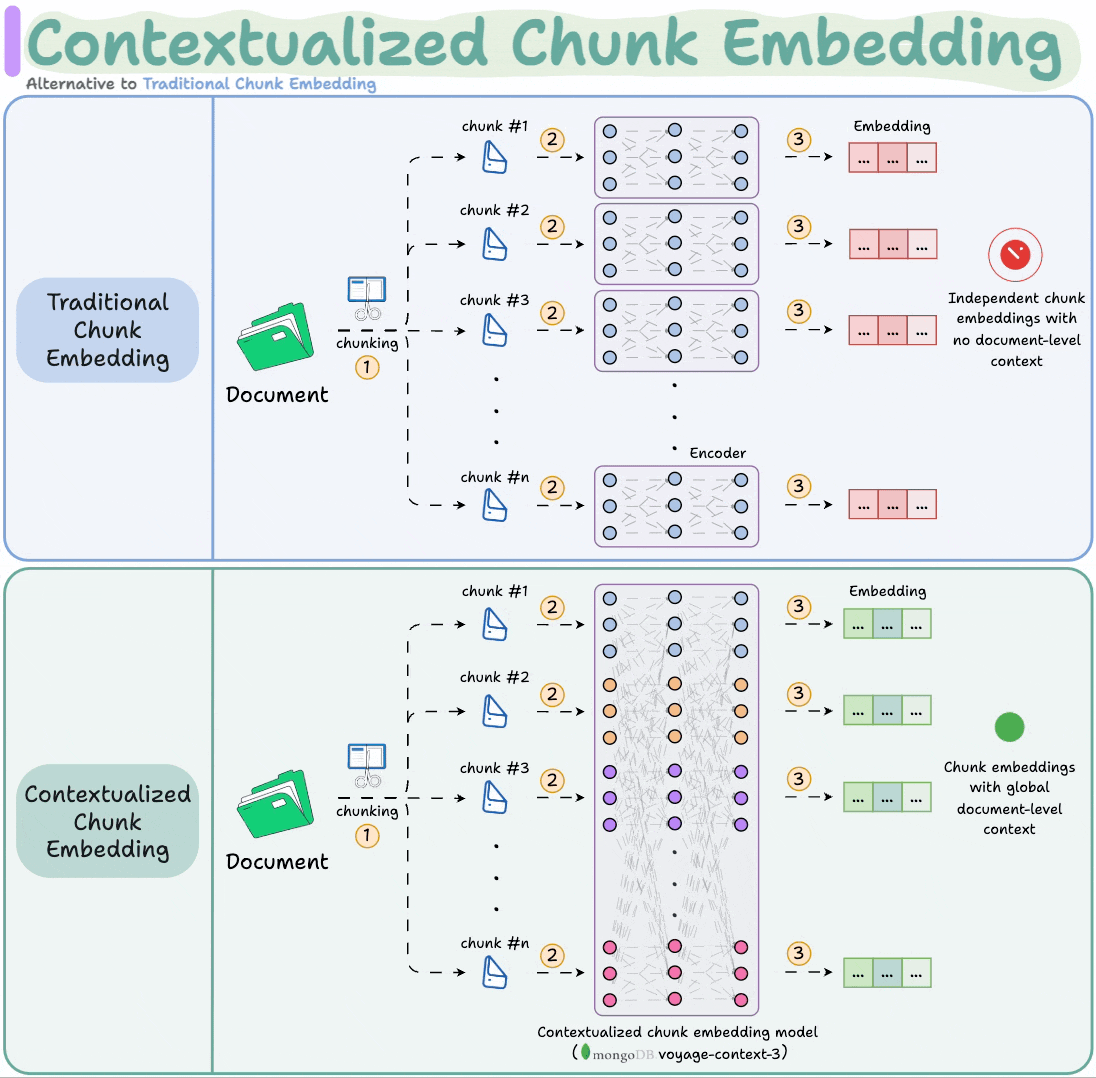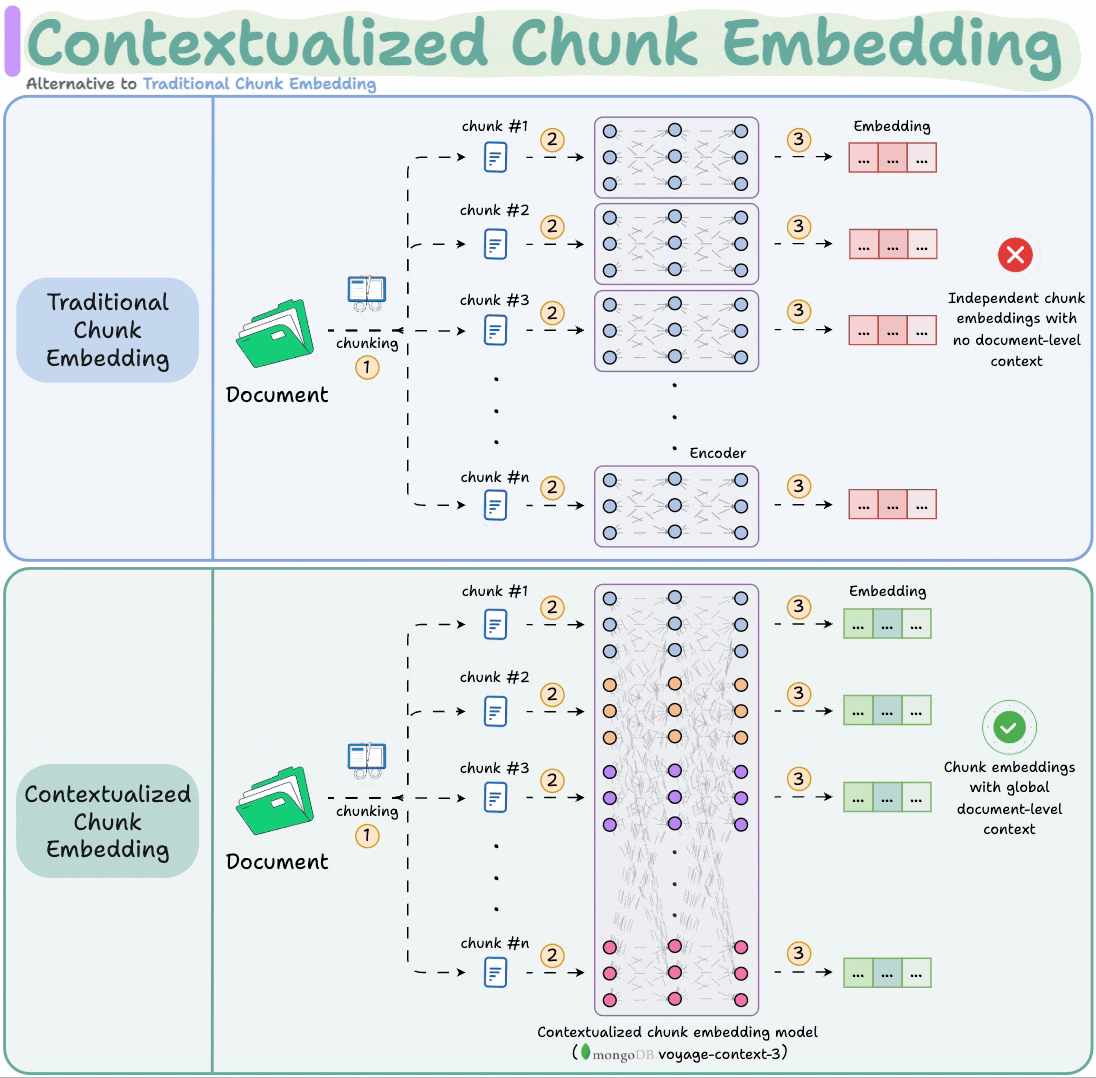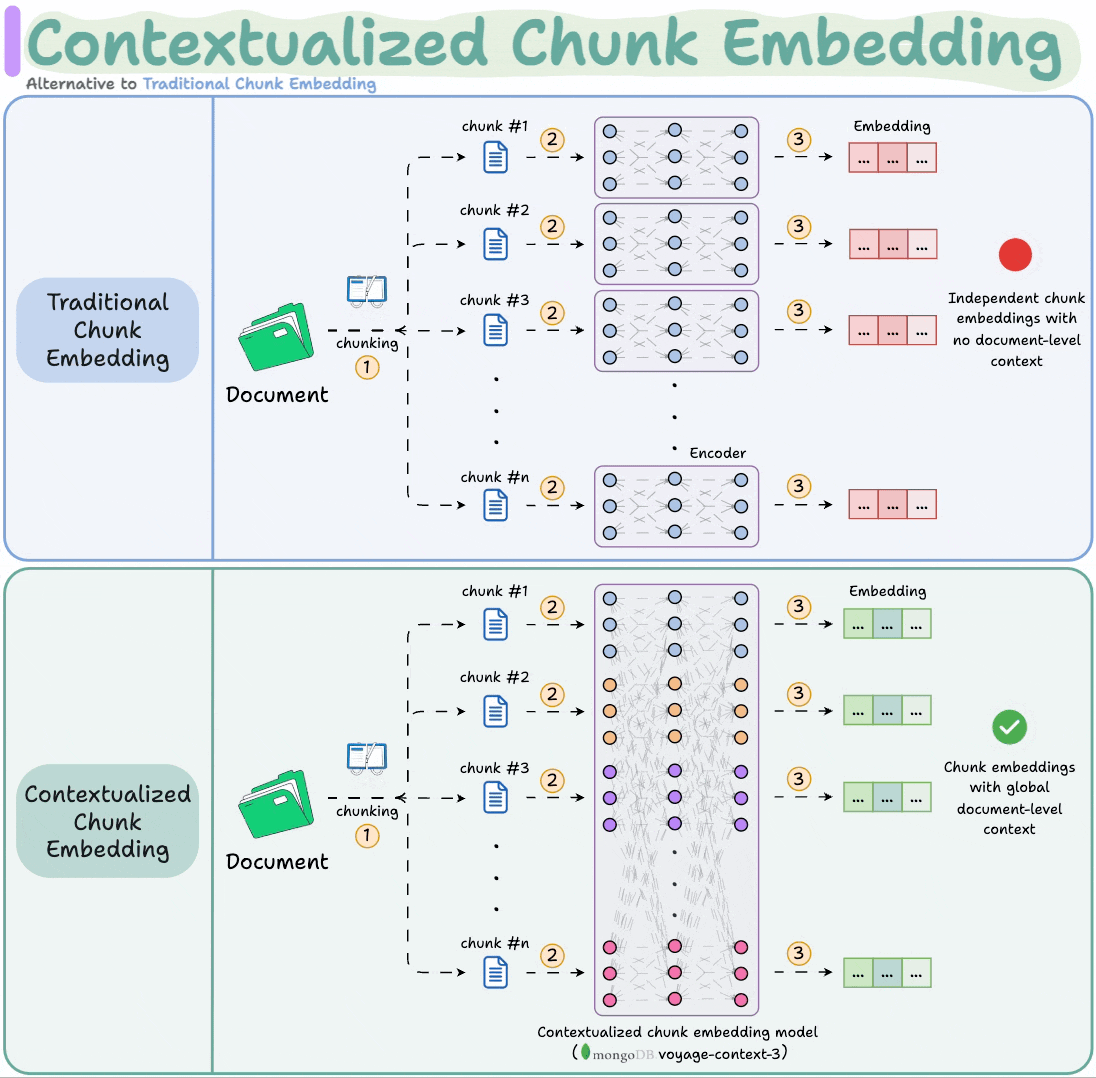
Contextualized Chunk Embedding Model
RAG is 80% retrieval and 20% generation.
So if RAG isn't working, most likely, it's a retrieval issue, which further originates from chunking and embedding.
Contextualized chunk embedding models solve this.
Let's dive in to learn more!
In RAG:
No chunking drives up token costs
Large chunks lose fine-grained context
Small chunks lose global/neighbourhood context
In fact, chunking also involves determining chunk overlap, generating summaries, etc., which are tedious.
Moreover, despite tuning and balancing tradeoffs, the final chunk embeddings are generated independently with no interaction with each other.
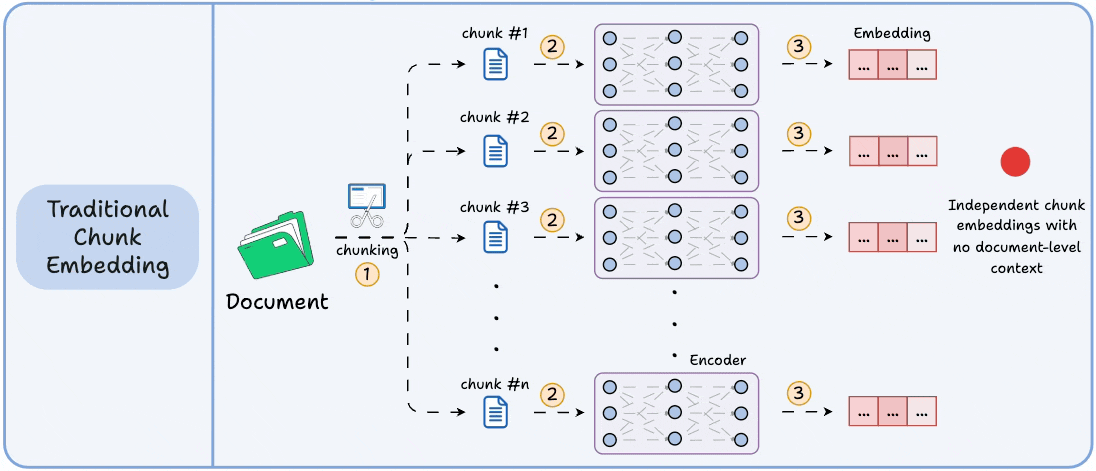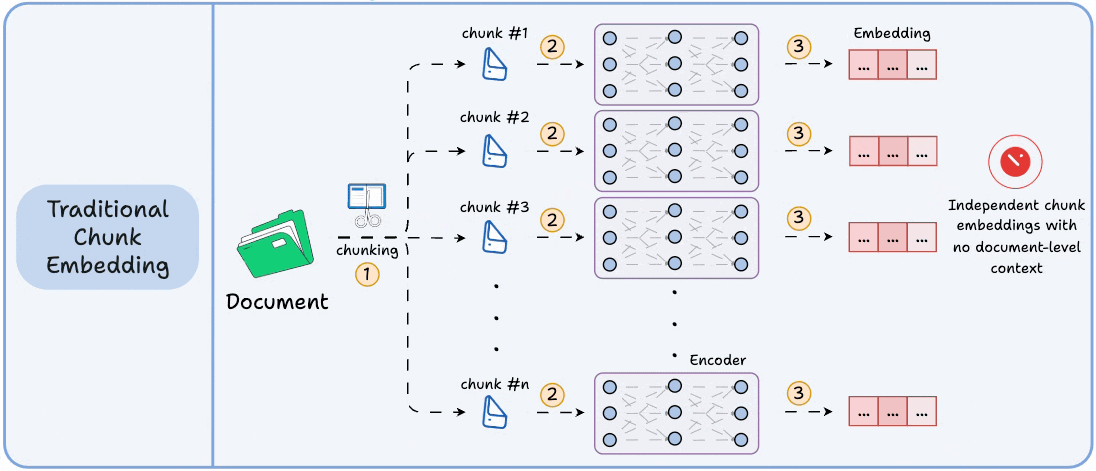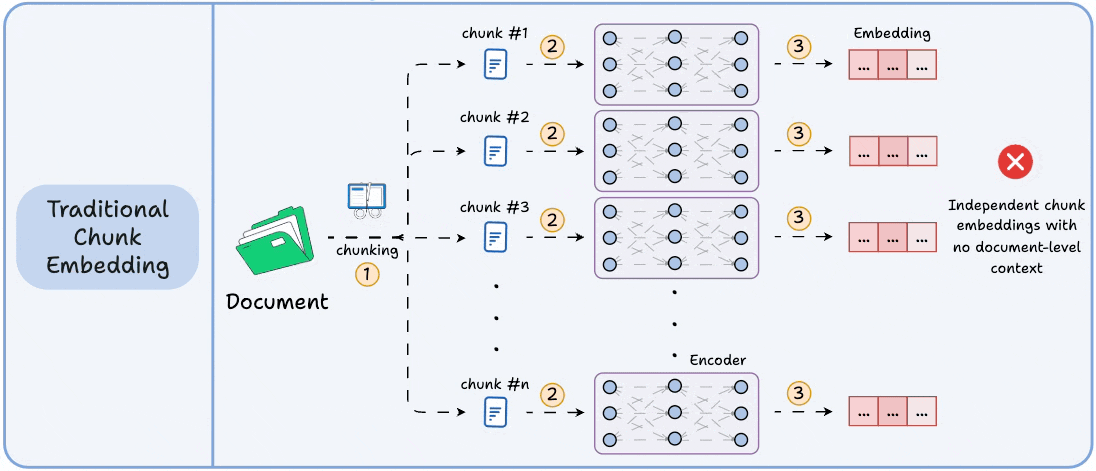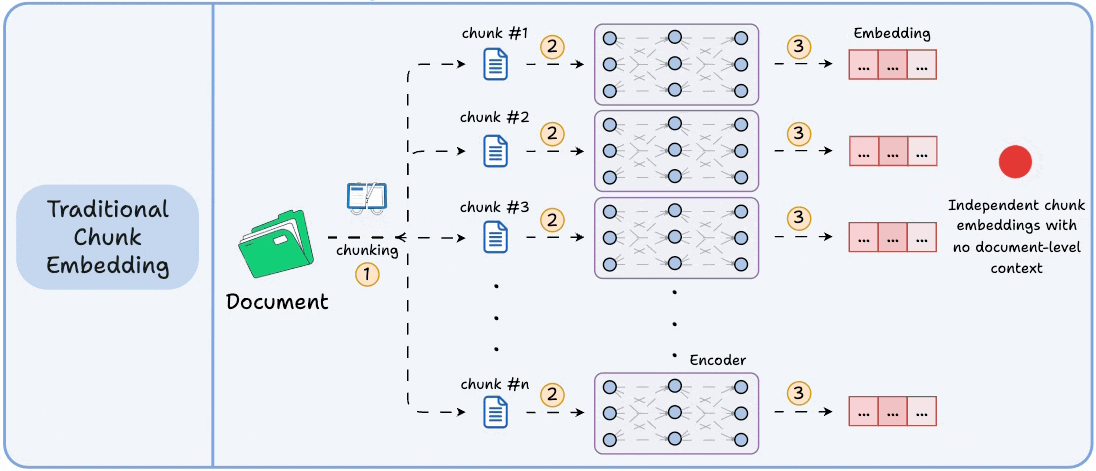
This isn't true with real-world docs, which have long-range dependencies.
voyage-context-3 embedding model by MongoDB solves this.
It is a contextualized chunk embedding model that produces vectors for chunks that capture the full document context without any manual metadata and context augmentation.
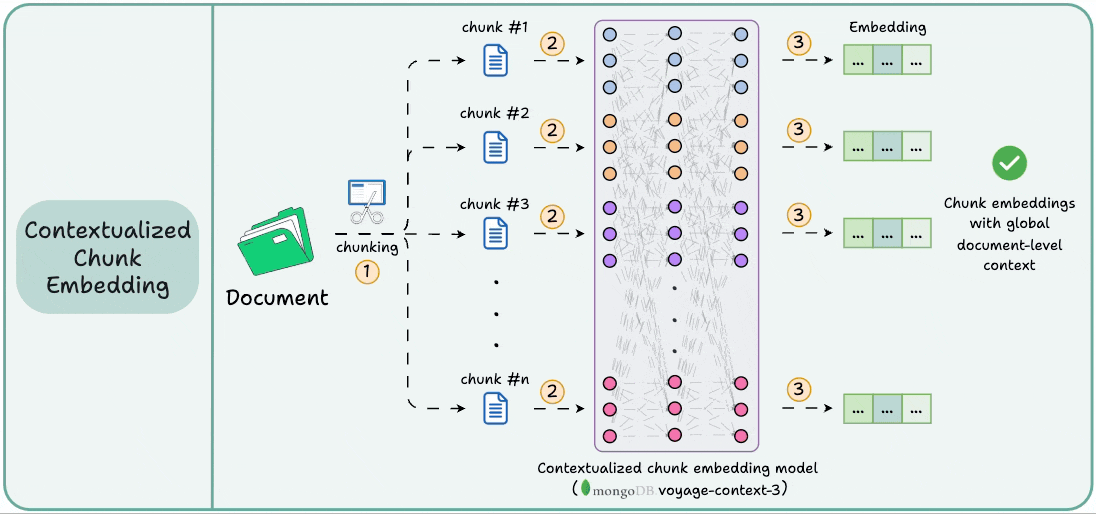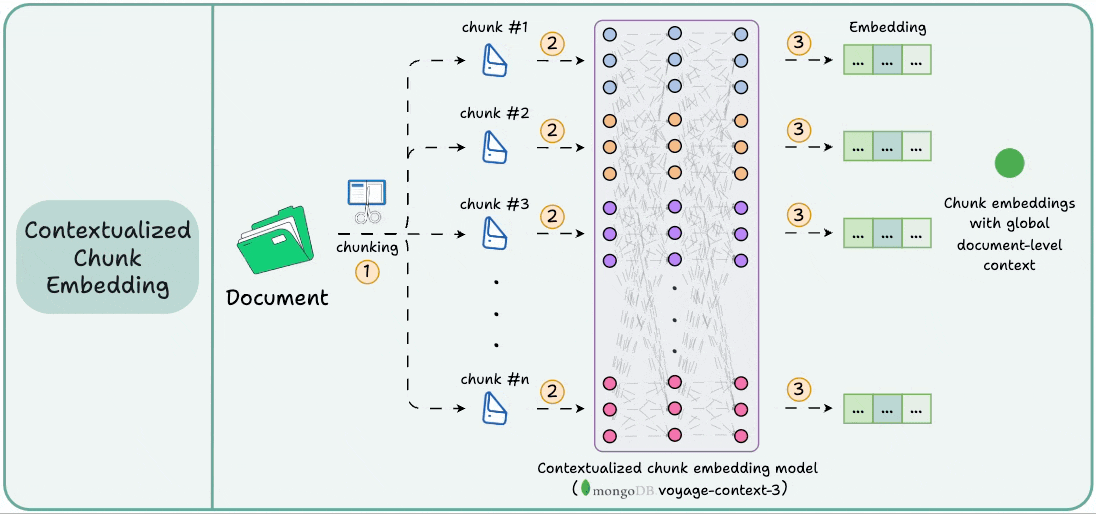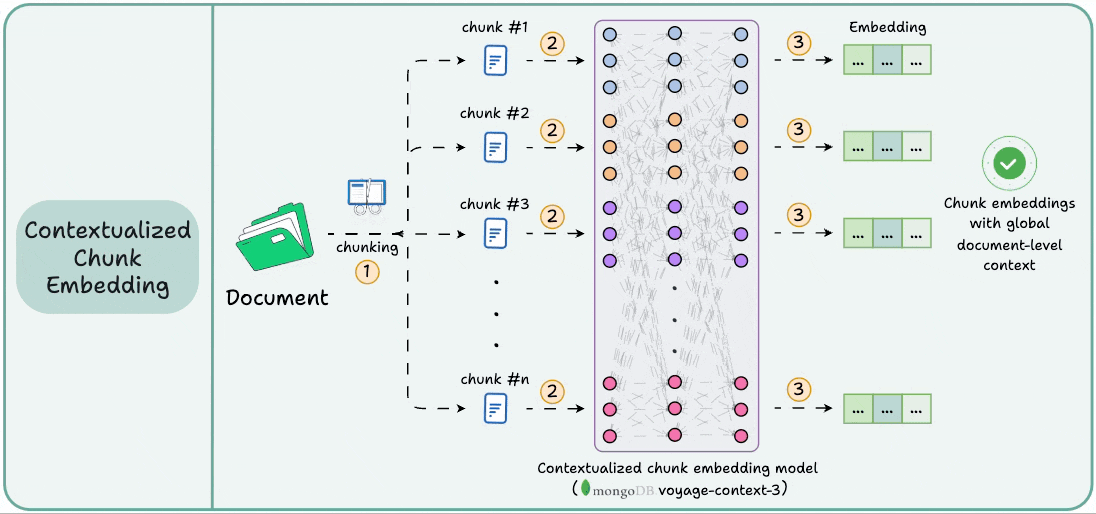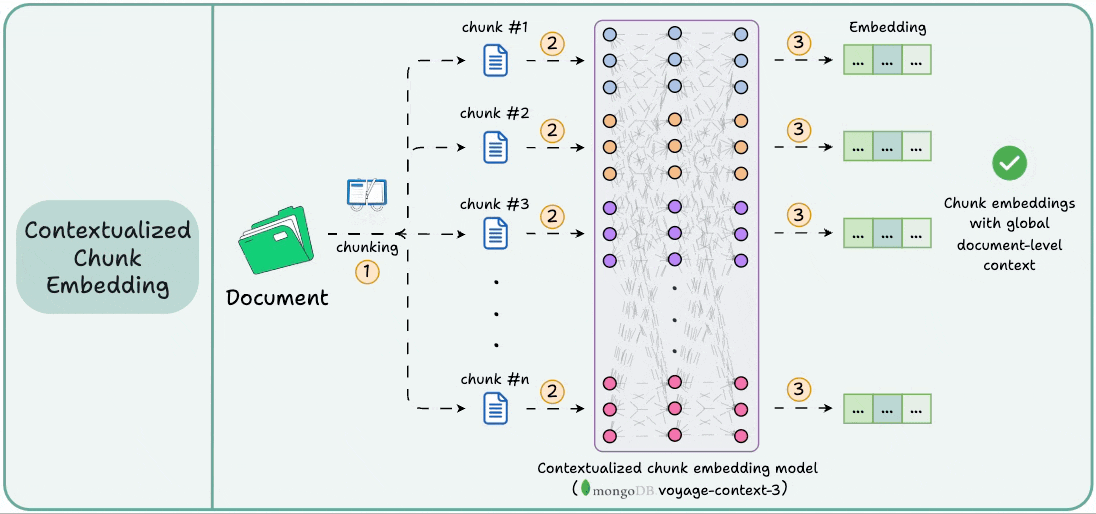
Technically, unlike traditional chunk embedding, the model processes the entire doc in a single pass to embed each chunk.
This way, it sees all the chunks at the same time to generate global document-aware chunk embeddings.
This gives semantically aware retrieval in RAG.
Across 93 retrieval datasets, spanning nine domains (web reviews, law, medical, long documents, etc.):
voyage-context-3 outperforms:
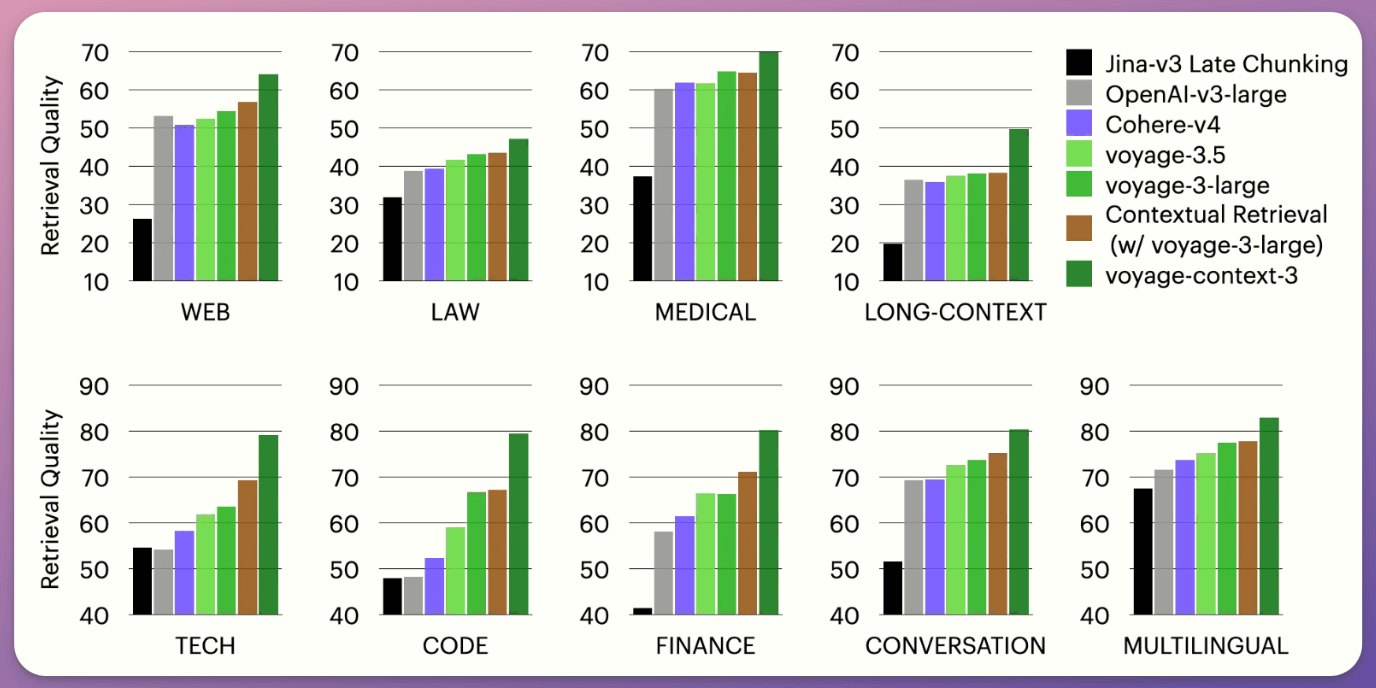
all models across all domains
OpenAI-v3-large by 14.2%
Cohere-v4 by 7.89%
Jina-v3 by 23.66%
voyage-context-3 supports 2048, 1024, 512, and 256 dimensions with quantization.
Compared to OpenAI-v3-large (float, 3072d), voyage-context-3 (int8, 2048):
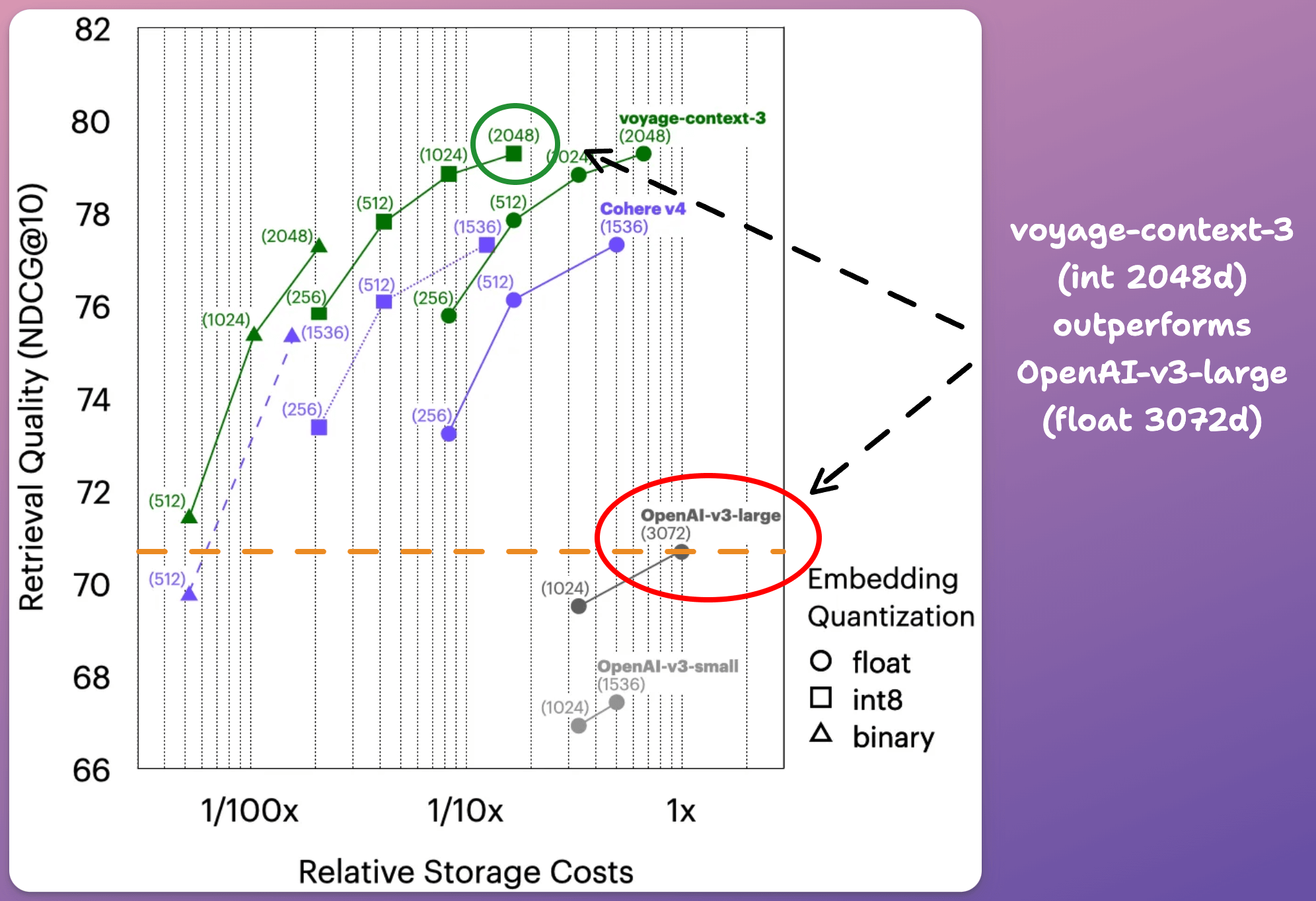
delivers 83% lower vector DB costs
provides 8.60% better retrieval quality
Compared to OpenAI-v3-large (float, 3072d). voyage-context-3 (binary, 512):
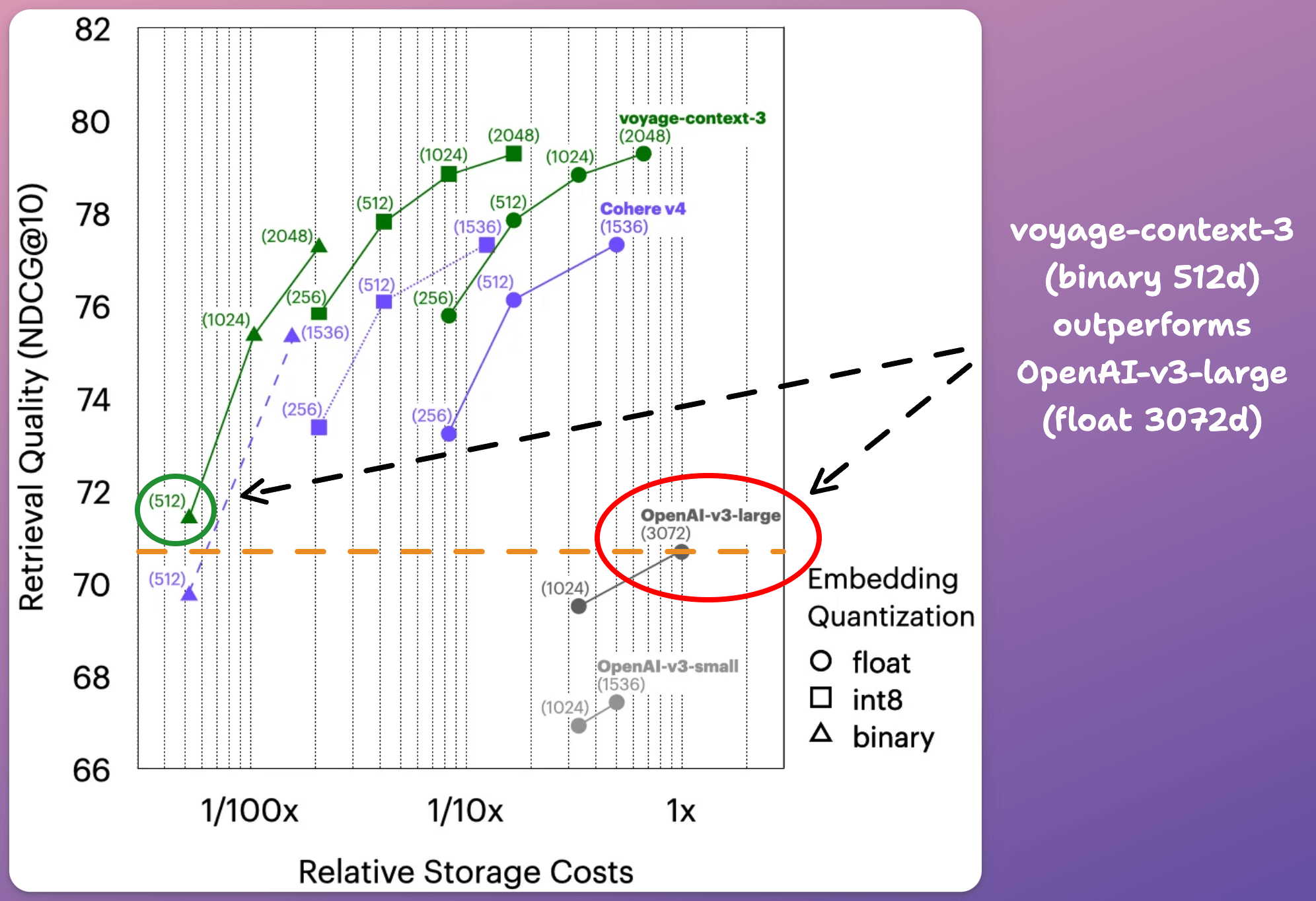
99.48% lower vector DB costs.
0.73% better retrieval quality.
In terms of practical usage...
voyage-context-3 is a drop-in replacement for standard embeddings without downstream workflow changes.
So you can start using it by just changing the model name.
To recap, instead of producing independent chunk embeddings, contextualized chunk embedding models like voyage-context-3 process the entire doc in a single pass to embed each chunk.
This leads to document-aware chunk embeddings that generate semantically aware retrieval in RAG.
Check the visual below:
Thanks to the MongoDB team for working with us on today’s newsletter issue!
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Start here , LLM System Design and Case Studies: https://open.substack.com/pub/naina0405/p/launching-llm-system-design-large-984?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false