
Contrastive Learning Using Siamese Networks
Building a face unlock system.

Announcement
Currently, lifetime access to Daily Dose of DS is available at 2x the yearly price.
From 1st October, it will be available at 3x the yearly price.
You can join below before it increases in the next ~54 hours.
A lifetime plan involves no renewals and gives you lifetime access to the exclusive data science and machine learning resources published here.
Let’s get to today’s post now!
Task
As an ML engineer, you are responsible for building a face unlock system.
Let’s look through some possible options:
Today, we shall cover the overall idea and do the implementation tomorrow.
1) How about a simple binary classification model?
Output 1 if the true user is opening the mobile; 0 otherwise.
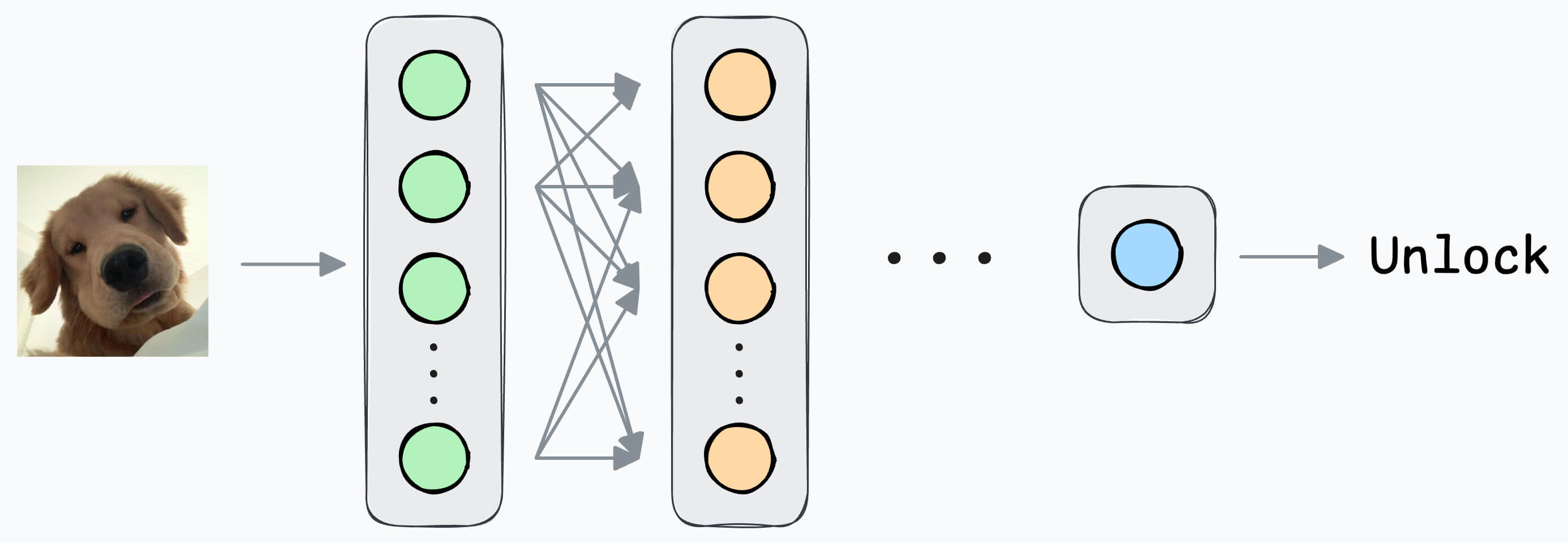
Initially, you can ask the user to input facial data to train the model.
But that’s where you identify the problem.
All samples will belong to “Class 1.”

Now, you can’t ask the user to find someone to volunteer for “Class 0” samples since it’s too much hassle for them.
Not only that, you also need diverse “Class 0” samples. Samples from just one or two faces might not be sufficient.
The next possible solution you think of is…
Maybe ship some negative samples (Class 0) to the device to train the model.

Might work.
But then you realize another problem:
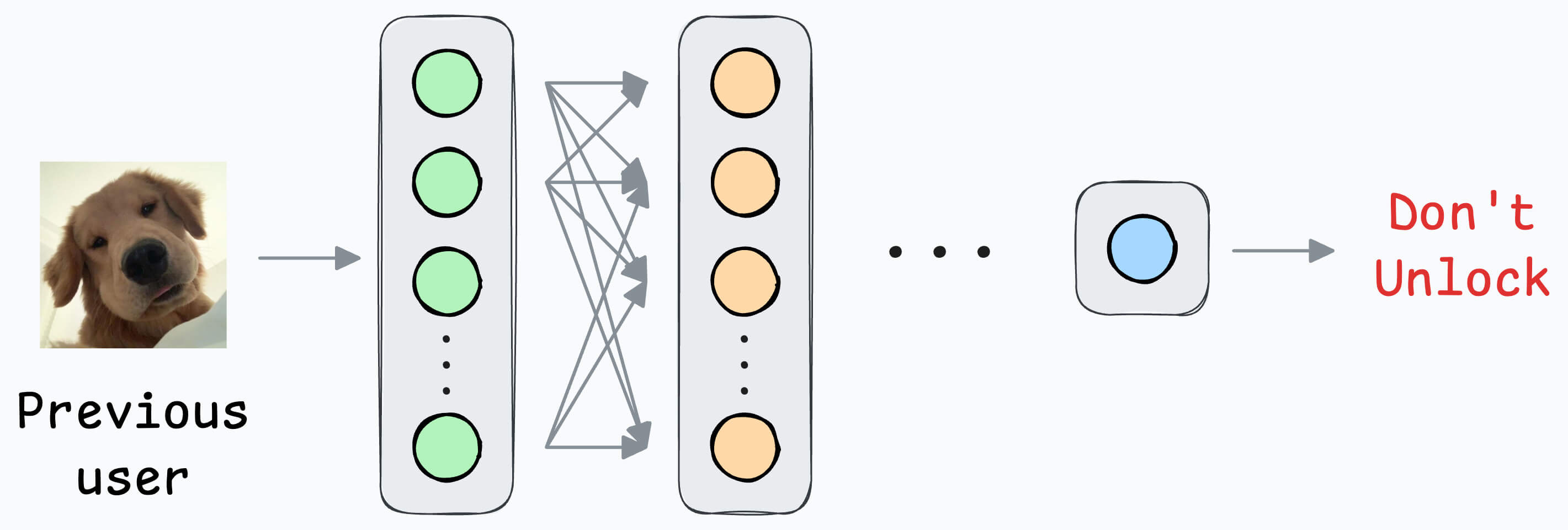
What if another person wants to use the same device?
Since all new samples will belong to the “new face” during adaptation, what if the model forgets the first face?
2) How about transfer learning?
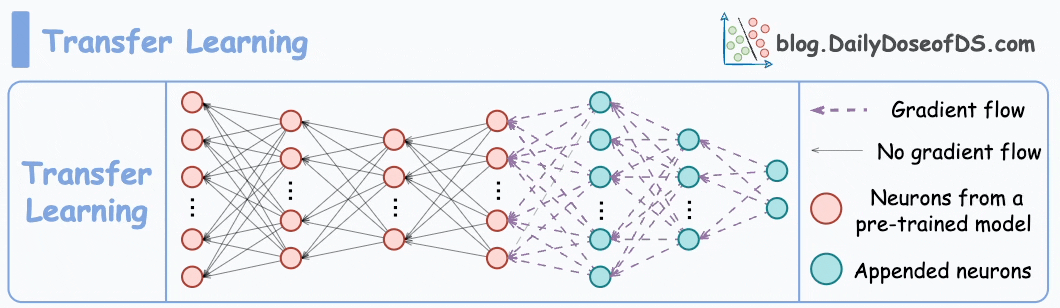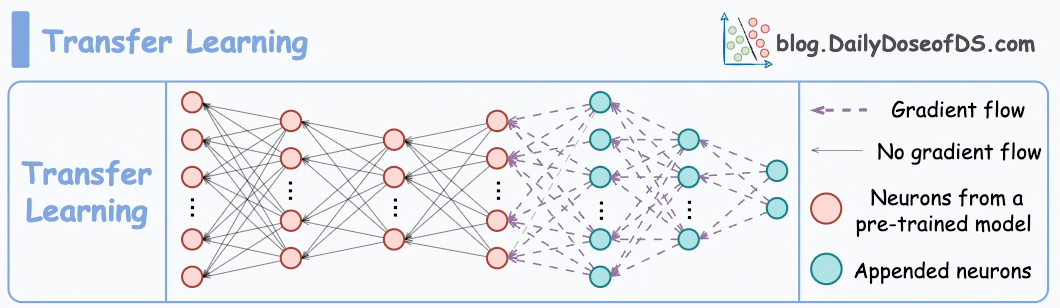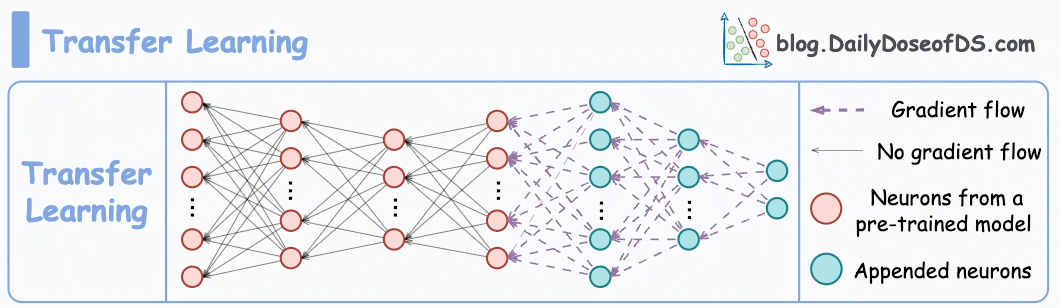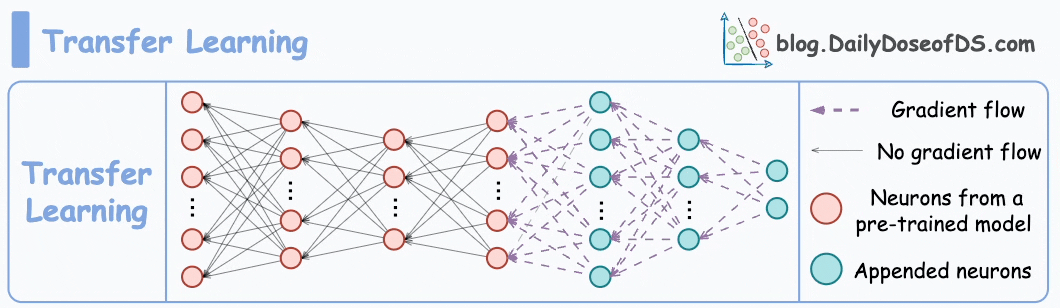
This is extremely useful when:
The task of interest has less data.
But a related task has abundant data.
This is how you think it could work in this case:
Train a neural network model (base model) on some related task → This will happen before shipping the model to the user’s device.
Next, replace the last few layers of the base model with untrained layers and ship it to the device.
It is expected that the first few layers would have learned to identify the key facial features.
From there on, training on the user’s face won’t require much data.
But yet again, you realize that you shall run into the same problems you observed with the binary classification model since the new layers will still be designed around predicting 1 or 0.
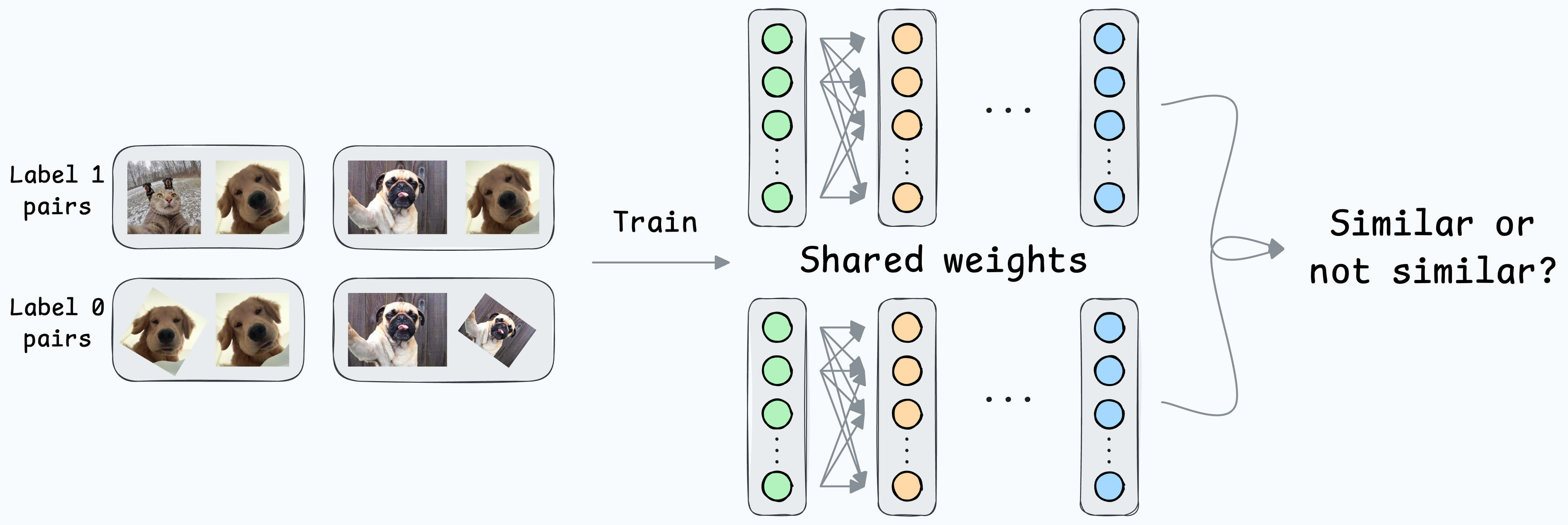
Solution: Contrastive learning using Siamese Networks
At its core, a Siamese network determines whether two inputs are similar.

It does this by learning to map both inputs to a shared embedding space (the blue layer above):
If the distance between the embeddings is LOW, they are similar.
If the distance between the embeddings is HIGH, they are dissimilar.
They are beneficial for tasks where the goal is to compare two data points rather than to classify them into predefined categories/classes.
This is how it will work in our case:
Create a dataset of face pairs:
If a pair belongs to the same person, the true label will be 0.

If a pair belongs to different people, the true label will be 1.


After creating this data, define a network like this:

Pass both inputs through the same network to generate two embeddings.
If the true label is 0 (same person) → minimize the distance between the two embeddings.
If the true label is 1 (different person) → maximize the distance between the two embeddings.

Contrastive loss (defined below) helps us train such a model:
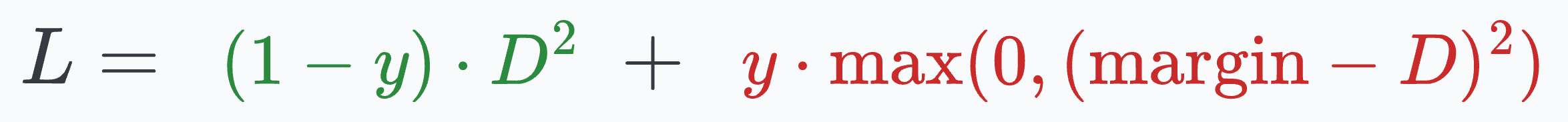
where:
yis the true label.Dis the distance between two embeddings.marginis a hyperparameter, typically greater than 1.
Here’s how this particular loss function helps:
When
y=1(different people), the loss will be: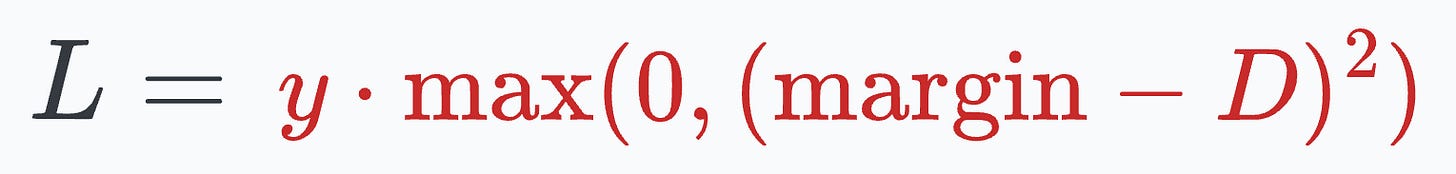
The above value will be minimum when D is close to the
marginvalue, leading to more distance between the embeddings.
When y=0 (same person), the loss will be:

The above value will be minimum when D is close to
0, leading to a low distance between the embeddings.


This way, we can ensure that:
when the inputs are similar, they lie closer in the embedding space.
when the inputs are dissimilar, they lie far in the embedding space.
Siamese Networks in face unlock
Here’s how it will help in the face unlock application.
First, you will train the model on several image pairs using contrastive loss.
This model (likely after model compression) will be shipped to the user’s device.
During the setup phase, the user will provide facial data, which will create a user embedding:
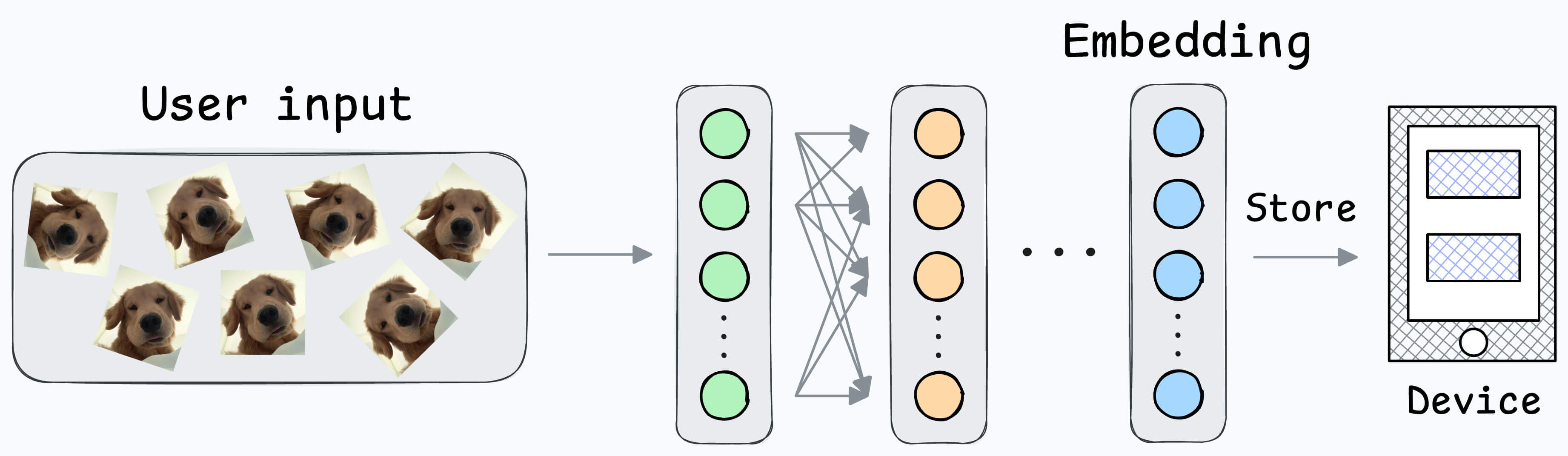
This embedding will be stored in the device’s memory.
Next, when the user wants to unlock the mobile, a new embedding can be generated and compared against the available embedding:
Action: Unlock the mobile if the distance is small.
Done!
Note that no further training was required here, like in the earlier case of binary classification.
Also, what if multiple people want to add their face IDs?
No problem.
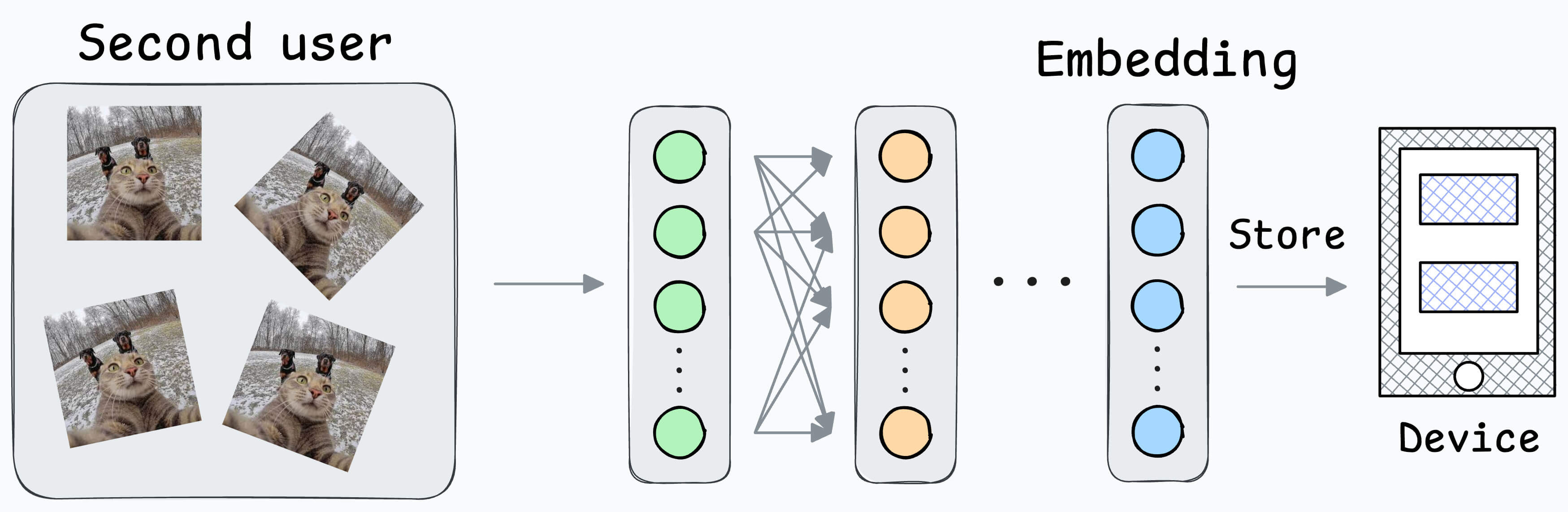
Create another embedding for the new user.
During unlock, compare the incoming user against all stored embeddings.
That was simple, wasn’t it?
I am ending today’s issue here, but tomorrow, we shall discuss a simple implementation of Siamese Networks using PyTorch.
Until then, here’s some further hands-on reading to learn how to build on-device ML applications:
Learn how to build privacy-first ML systems (with implementations): Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
👉 Over to you: Siamese Networks are not the only way to solve this problem. What other architectures can work?
For those wanting to develop “Industry ML” expertise:
All businesses care about impact.
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with “Industry ML.” Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model's Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
Being able to code is a skill that’s diluting day by day.
Thus, the ability to make decisions, guide strategy, and build solutions that solve real business problems and have a business impact will separate practitioners from experts.
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.