
Cost Complexity Pruning in Decision Trees
Decision trees always overfit. Prevent it this way.

By default, a decision tree (in sklearn’s implementation, for instance), is allowed to grow until all leaves are pure.
This happens because a standard decision tree algorithm greedily selects the best split at each node.
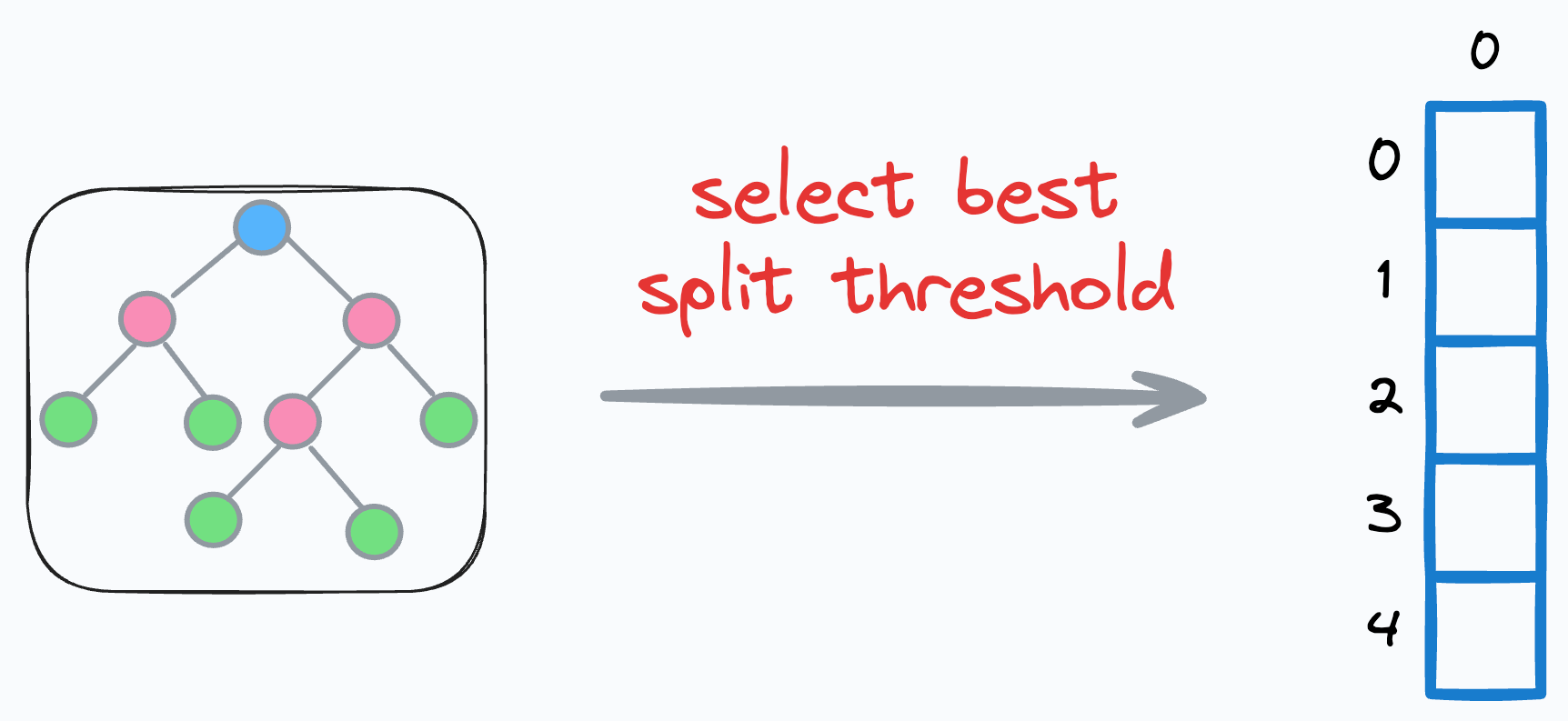
This makes its nodes more and more pure as we traverse down the tree.
As the model correctly classifies ALL training instances, it leads to 100% overfitting, and poor generalization.
For instance, consider this dummy dataset:
Fitting a decision tree on this dataset gives us the following decision region plot:

It is pretty evident from the decision region plot, the training and test accuracy that the model has entirely overfitted our dataset.
Cost-complexity-pruning (CCP) is an effective technique to prevent this.
CCP considers a combination of two factors for pruning a decision tree:
Cost (C): Number of misclassifications
Complexity (C): Number of nodes
The core idea is to iteratively drop sub-trees, which, after removal, lead to:
a minimal increase in classification cost
a maximum reduction of complexity (or nodes)
In other words, if two sub-trees lead to a similar increase in classification cost, then it is wise to remove the sub-tree with more nodes.

In sklearn, you can control cost-complexity-pruning using the ccp_alpha parameter:
large value of
ccp_alpha→ results in underfittingsmall value of
ccp_alpha→ results in overfitting
The objective is to determine the optimal value of ccp_alpha, which gives a better model.
The effectiveness of cost-complexity-pruning is evident from the image below:

As depicted above, CCP results in a much simpler and acceptable decision region plot.
That said, Bagging is another pretty effective way to avoid this overfitting problem.
The idea (as you may already know) is to:
create different subsets of data with replacement (this is called bootstrapping)
train one model per subset
aggregate all predictions to get the final prediction
As a result, it drastically reduces the variance of a single decision tree model, as shown below:

While we can indeed verify its effectiveness experimentally (as shown above), most folks struggle to intuitively understand:
Why Bagging is so effective.
Why do we sample rows from the training dataset with replacement.
How to mathematically formulate the idea of Bagging and prove variance reduction.
Can you answer these questions?
If not, we covered this in full detail here: Why Bagging is So Ridiculously Effective At Variance Reduction?

The article dives into the entire mathematical foundation of Bagging, which will help you:
Truly understand and appreciate the mathematical beauty of Bagging as an effective variance reduction technique
Why the random forest model is designed the way it is.
Also, talking about tree models, we formulated and implemented the XGBoost algorithm from scratch here: Formulating and Implementing XGBoost From Scratch.
It covers the entire mathematical details for you to learn how it works internally.
👉 Over to you: What are some other ways you use to prevent decision trees from overfitting?
For those who want to build a career in DS/ML on core expertise, not trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.
For instance:
15 Ways to Optimize Neural Network Training (With Implementation)
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Neat and detailed article. Keep up the good work man!
ur articles are too good Avi, since i am a student, any discount on lifetime access ?