
CPU vs GPU vs TPU vs NPU vs LPU
...explained visually!

The missing layer between AI agents and your infrastructure
Most identity models were built for humans and static automation.
AI agents break those assumptions because they act continuously, make decisions independently, and access infrastructure at machine speed.
As a result, it becomes nearly impossible to control access, trace behavior, or know which agent is responsible for what.
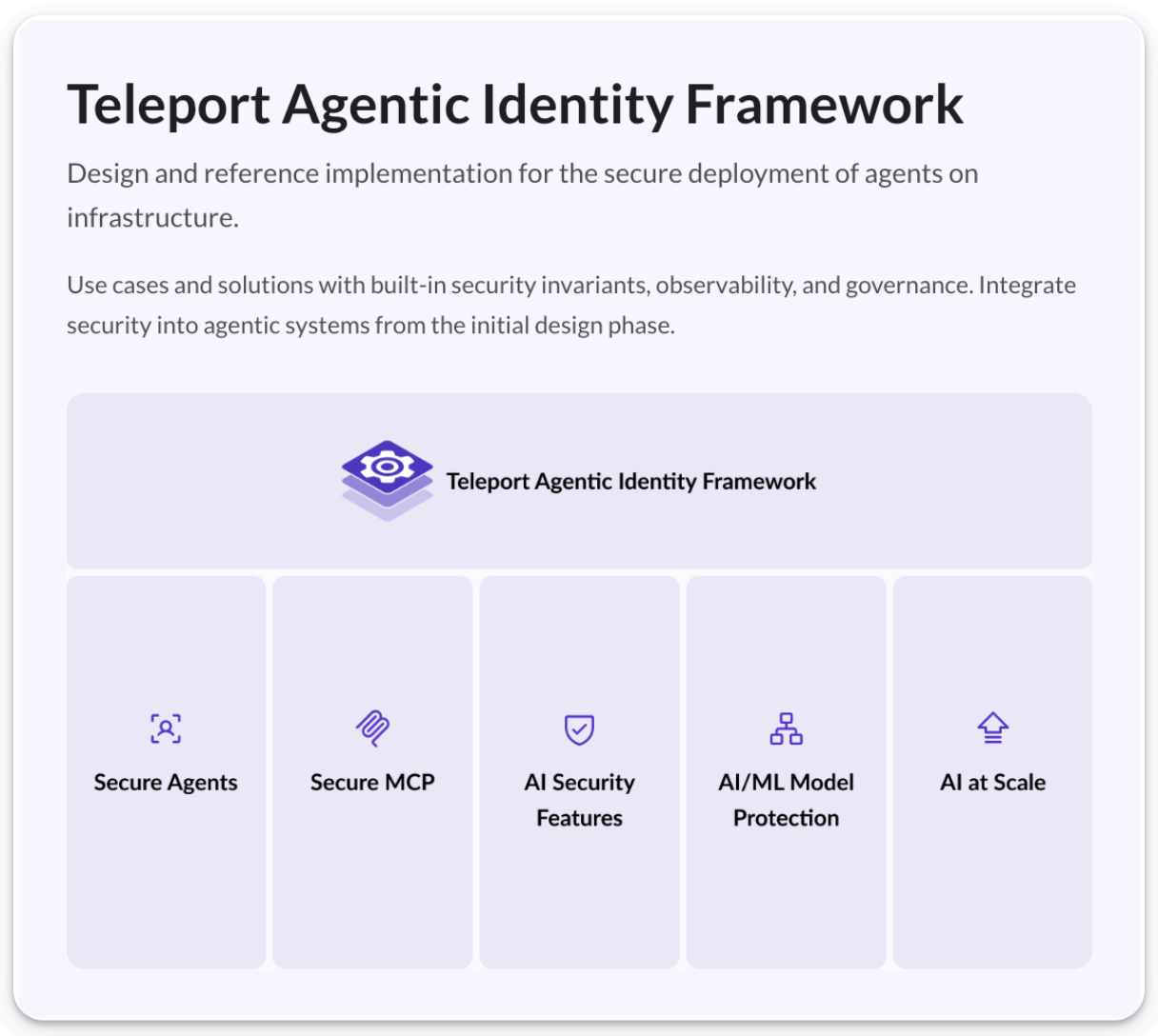
Teleport’s Agentic Identity Framework is an open-source, standards-driven architecture for deploying AI agents securely across infrastructure.
It gives every agent its own cryptographic identity, enforces access at runtime instead of relying on static privileges, discovers shadow agents and unmanaged MCP servers automatically, and maintains full attribution as systems operate autonomously.
The framework also provides controls for LLM usage, including rate limiting, budgets, and guardrails.
Get started here to securely deploy Agents in production →
Thanks to Teleport for partnering today!
CPU vs GPU vs TPU vs NPU vs LPU
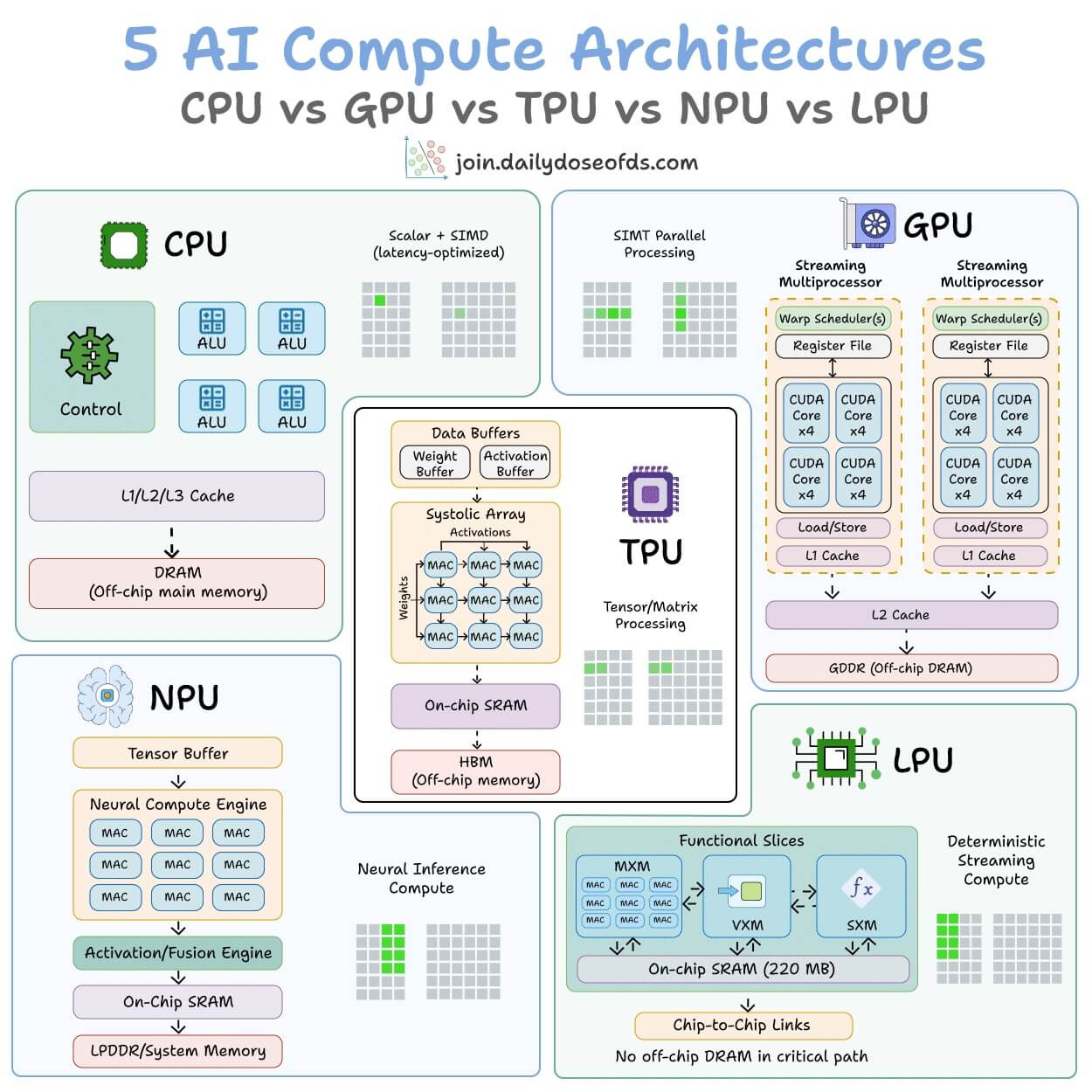
5 hardware architectures power AI today.
Each one makes a fundamentally different tradeoff between flexibility, parallelism, and memory access.
The visual below maps the internal architecture of all five side by side:
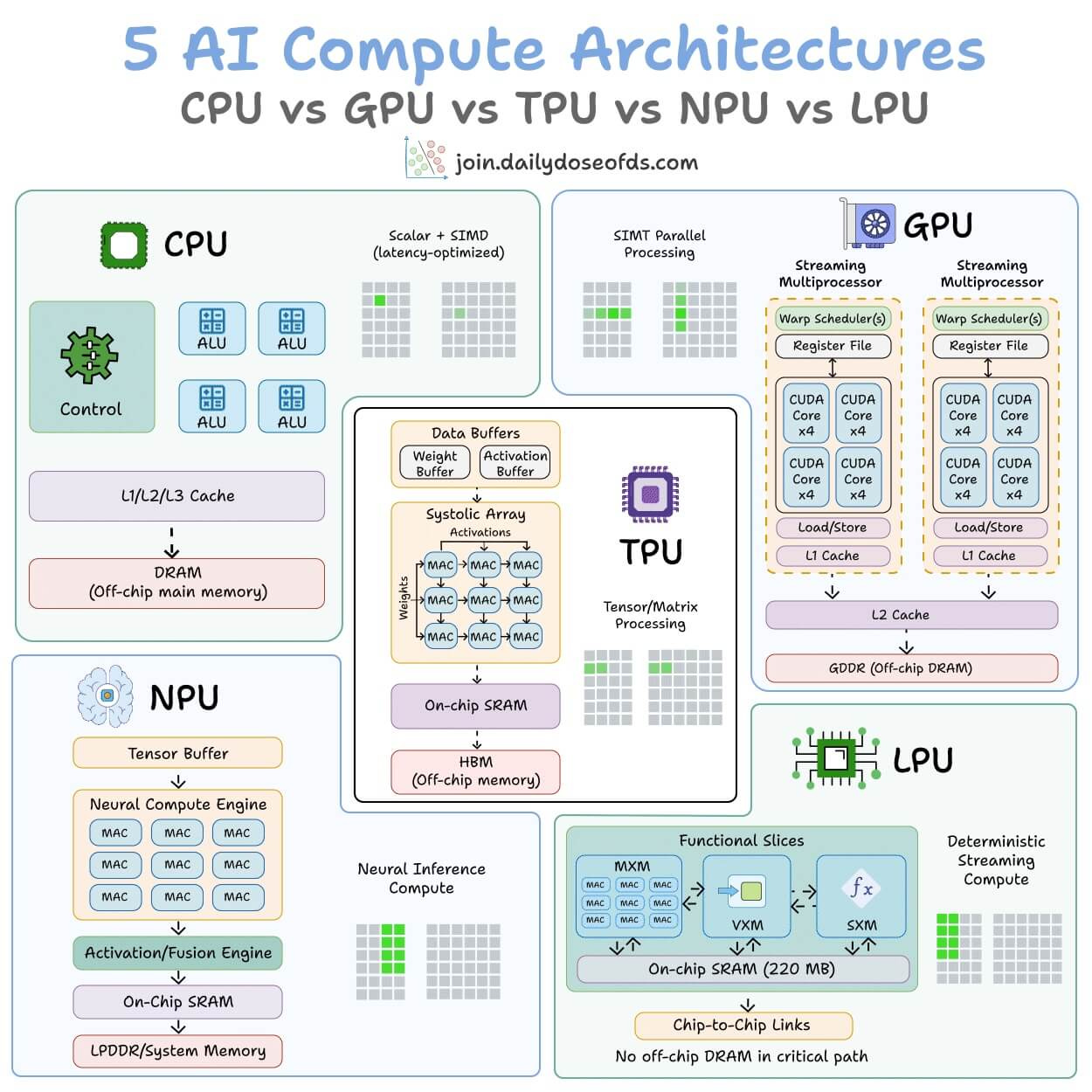
CPU
It is built for general-purpose computing. A few powerful cores handle complex logic, branching, and system-level tasks.
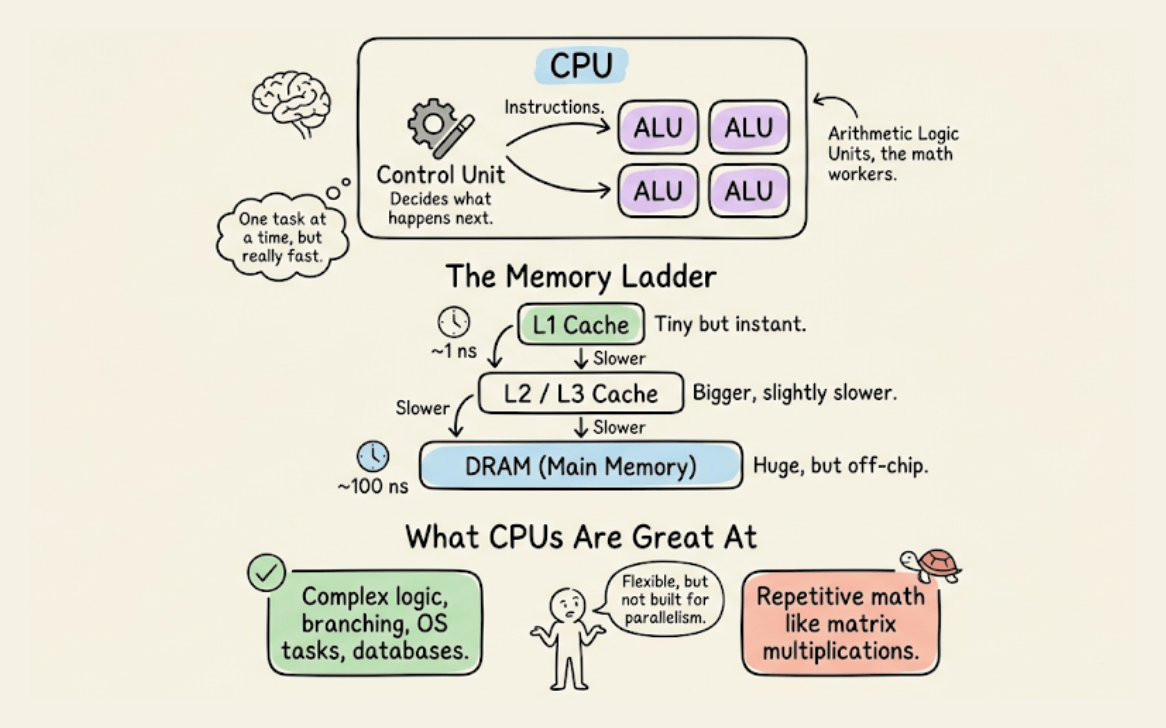
It has deep cache hierarchies and off-chip main memory (DRAM). It’s great for operating systems, databases, and decision-heavy code, but not that great for repetitive math like matrix multiplications.
GPU
Instead of a few powerful cores, GPUs spread work across thousands of smaller cores that all execute the same instruction on different data.
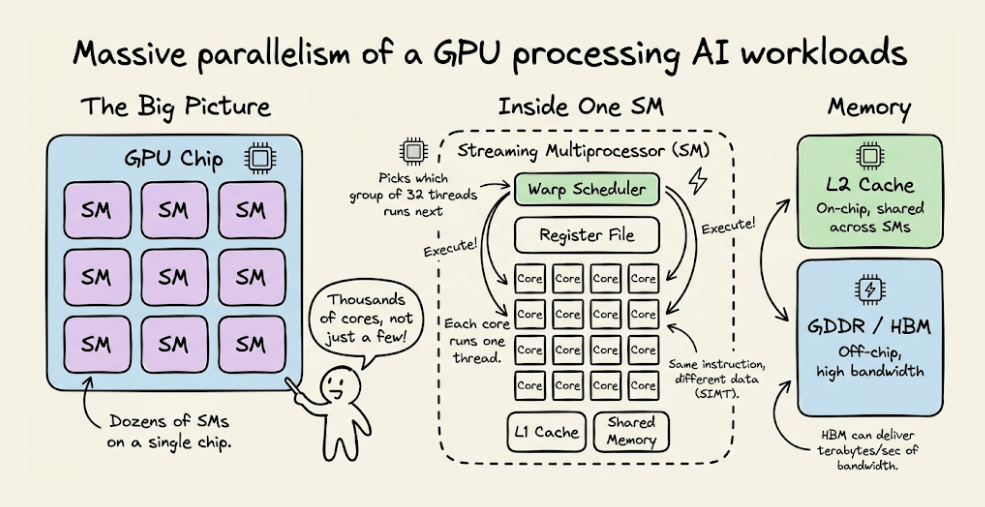
This is why GPUs dominate AI training. The parallelism maps directly to the kind of math neural networks need.
TPU
They go one step further with specialization.
The core compute unit is a grid of multiply-accumulate (MAC) units where data flows through in a wave pattern.
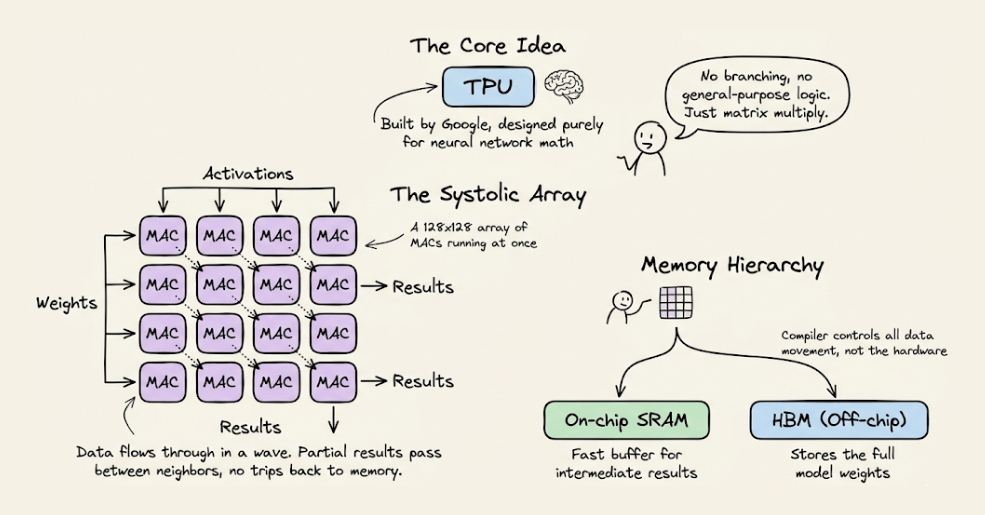
Weights enter from one side, activations from the other, and partial results propagate without going back to memory each time.
The entire execution is compiler-controlled, not hardware-scheduled. Google designed TPUs specifically for neural network workloads.
NPU
This is an edge-optimized variant.
The architecture is built around a Neural Compute Engine packed with MAC arrays and on-chip SRAM, but instead of high-bandwidth memory (HBM), NPUs use low-power system memory.
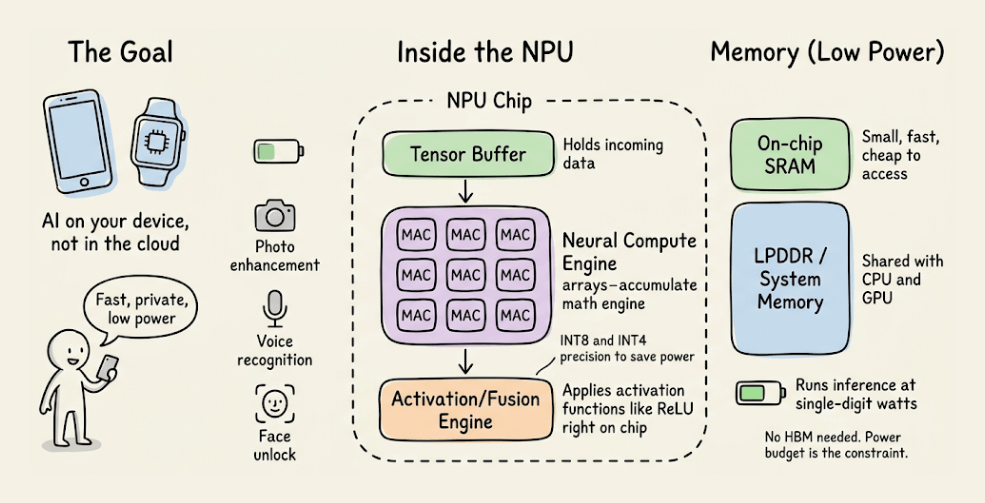
The design goal is to run inference at single-digit watt power budgets, like smartphones, wearables, and IoT devices.
Apple Neural Engine and Intel’s NPU follow this pattern.
LPU (Language Processing Unit)
This is the newest entrant, by Groq.
The architecture removes off-chip memory from the critical path entirely. All weight storage lives in on-chip SRAM.
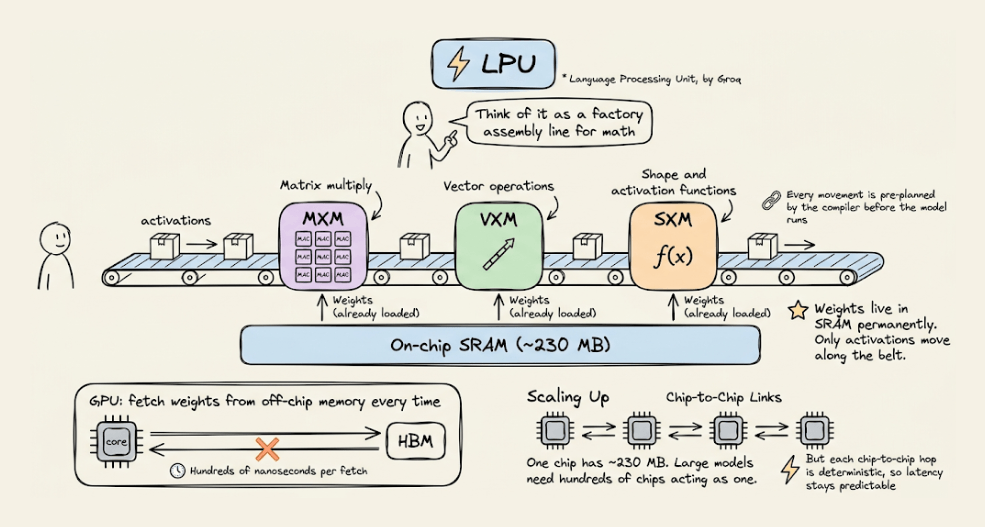
Execution is fully deterministic and compiler-scheduled, which means zero cache misses and zero runtime scheduling overhead.
The tradeoff is that it provides limited memory per chip, which means you need hundreds of chips linked together to serve a single large model. But the latency advantage is real.
AI compute has evolved from general-purpose flexibility (CPU) to extreme specialization (LPU). Each step trades some level of generality for efficiency.
The visual below maps the internal architecture of all five side by side, and it was inspired by ByteByteGo’s post on CPU vs GPU vs TPU. We expanded it to include two more architectures that are becoming central to AI inference today.
That said, if you want to get hands-on with actual GPU programming using CUDA, learn about how CUDA operates GPU’s threads, blocks, grids (with visuals), etc., we covered it here: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
👉 Over to you: Which of these 5 have you actually worked with or deployed on?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Hey Avi,
Great illustrations!
There is an issue. The image for TPU shows the GPU's image.