
CPython vs. Cython: How to Speed-up Native Python Programs
...within minimal effort.

Brilliant — Daily Learning, Lifelong Impact!
People often use “Jack of all trades, master of none” in a demeaning tone. But this is incomplete. The full saying is: “Jack of all trades, master of none, oftentimes better than master of one.”
I have observed the full saying to be true with most high-performing engineers I know—they are generalists, not specialists. They are constantly picking up new knowledge by putting in deliberate and consistent effort—spending time each day diving into topics that spark curiosity, even if it’s outside their immediate field.
While motivation is always at its peak in the early days, most people lose momentum sooner or later. Luckily, Brilliant is there to help.

Brilliant is an interactive platform with 1000s of lessons that simplify complex concepts in math, programming, data analysis, etc., using fun, hands-on, and visual experiences.
Features like Streaks and Leagues help you stay committed to your goals, and even ten minutes of learning a day can help you build a lifelong learning habit.
Join over 10 million people around the world by starting your 30-day free trial. Plus, Daily Dose of Data Science readers get a special 20% off a premium annual subscription:
Thanks to Brilliant for sponsoring today’s issue.
CPython vs. Cython
Python’s default interpreter — CPython, isn’t smart.
It serves as a standard interpreter for Python and offers no built-in optimization.
This profoundly affects the run-time performance of the program, especially when it’s all native Python code.
Today, I want to tell you about Cython, an optimized compiler, which addresses the limitations of the default interpreter of Python.
CPython and Cython are different. Don’t get confused between the two.
Let’s begin!
In a gist, Cython automatically converts your Python code into C, which is fast and efficient.
Here’s how we use it, say, in a Jupyter Notebook:
First, load the Cython extension (in a separate cell of the notebook):

Where we have native Python code, add the Cython magic command at the top of the cell:

If our code has functions, specify the data type of the parameters as follows:

Define every variable using the “
cdef” keyword and specify its data type.




A sample conversion of a Python function is shown below:

Simple, isn’t it?
Once we do that, Cython will convert our Python code to C, as depicted below:
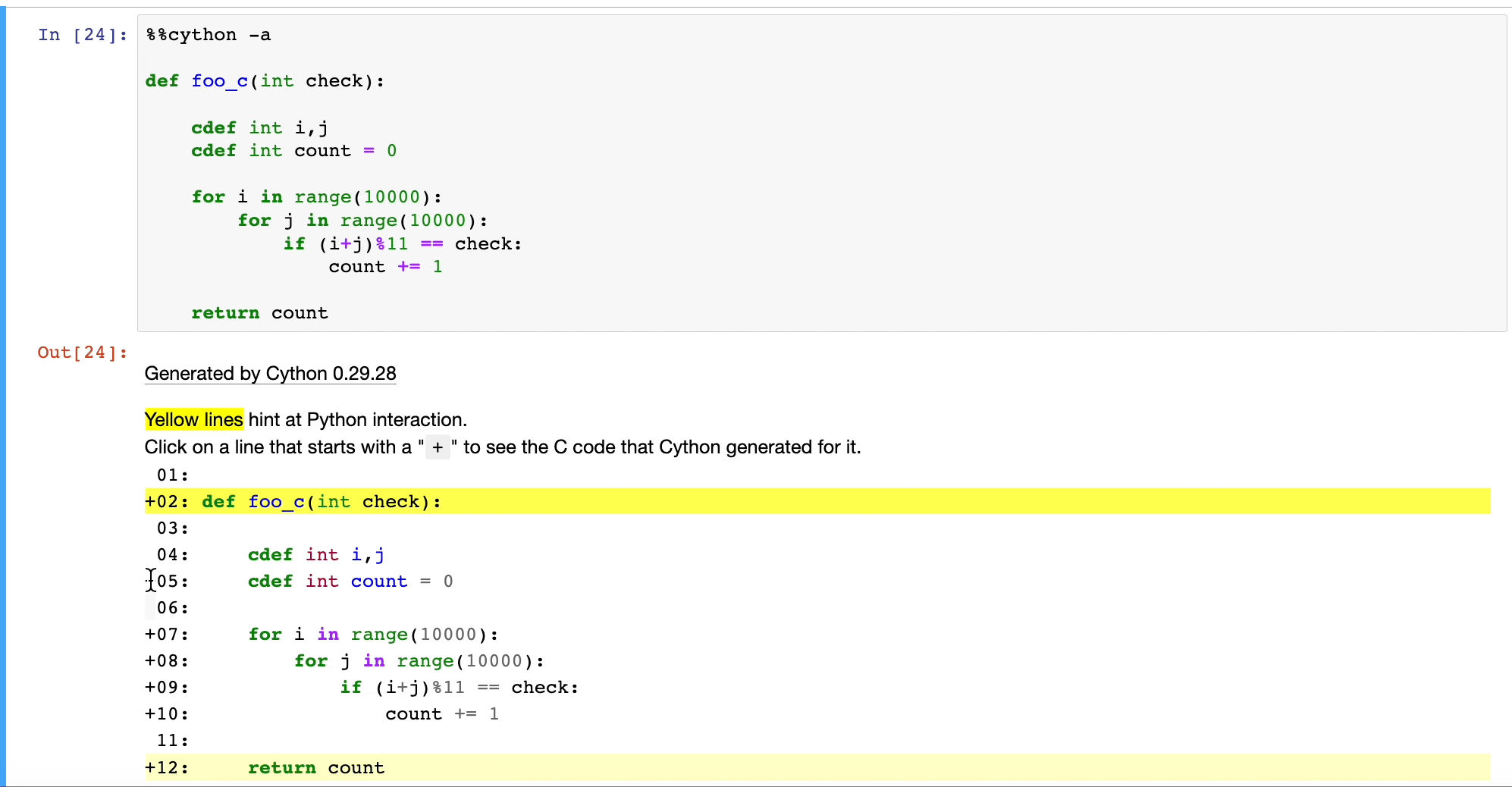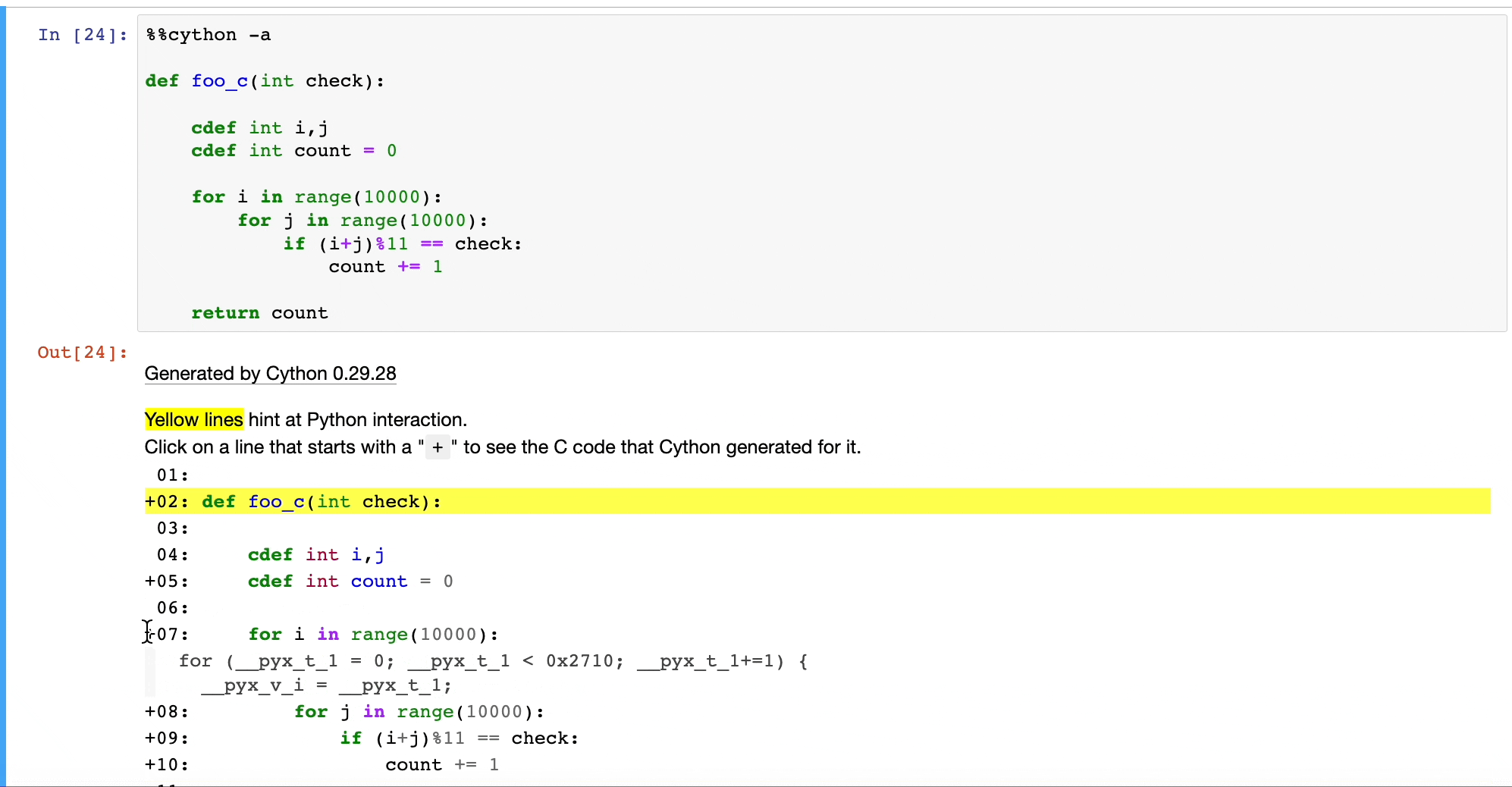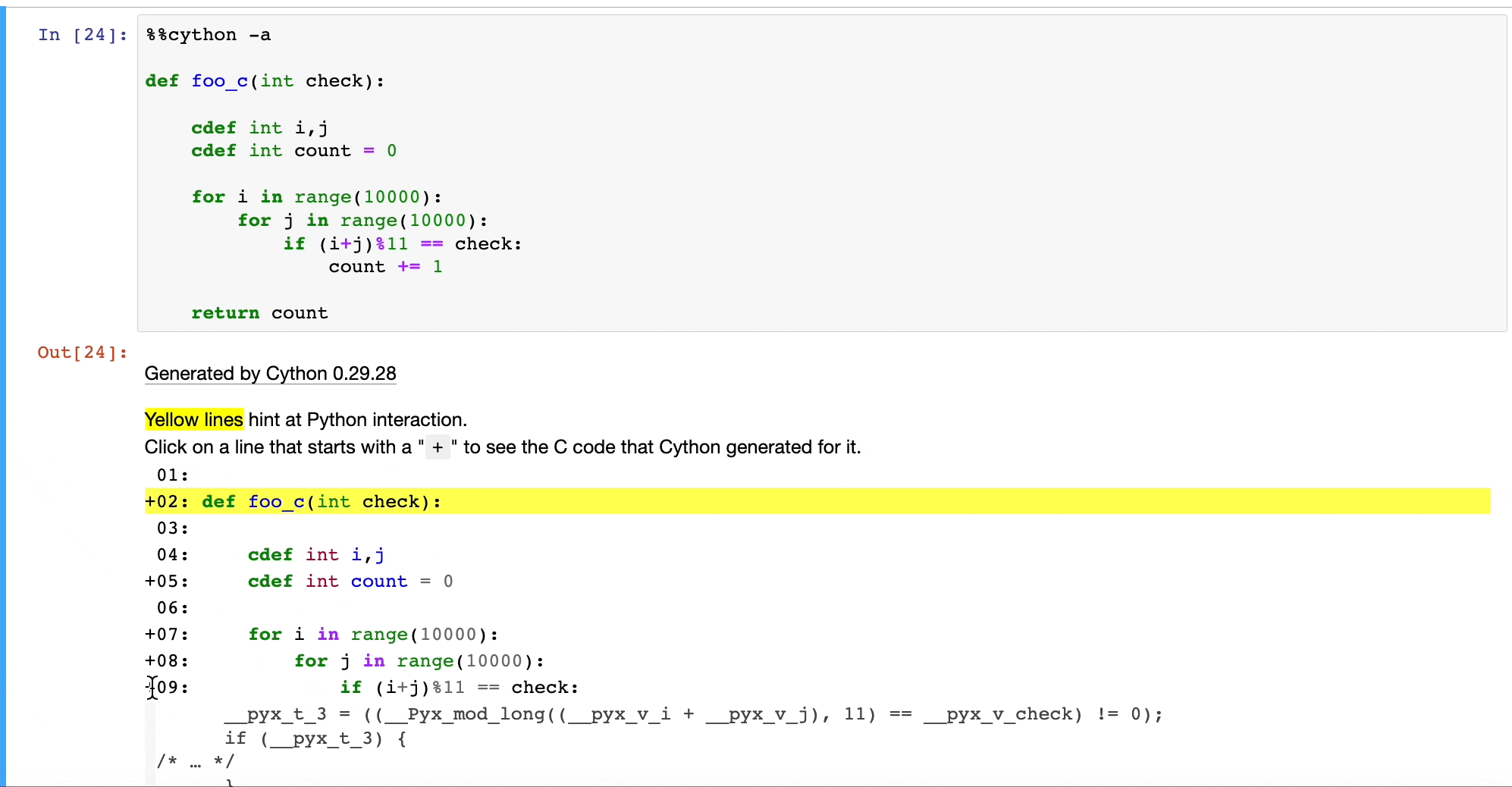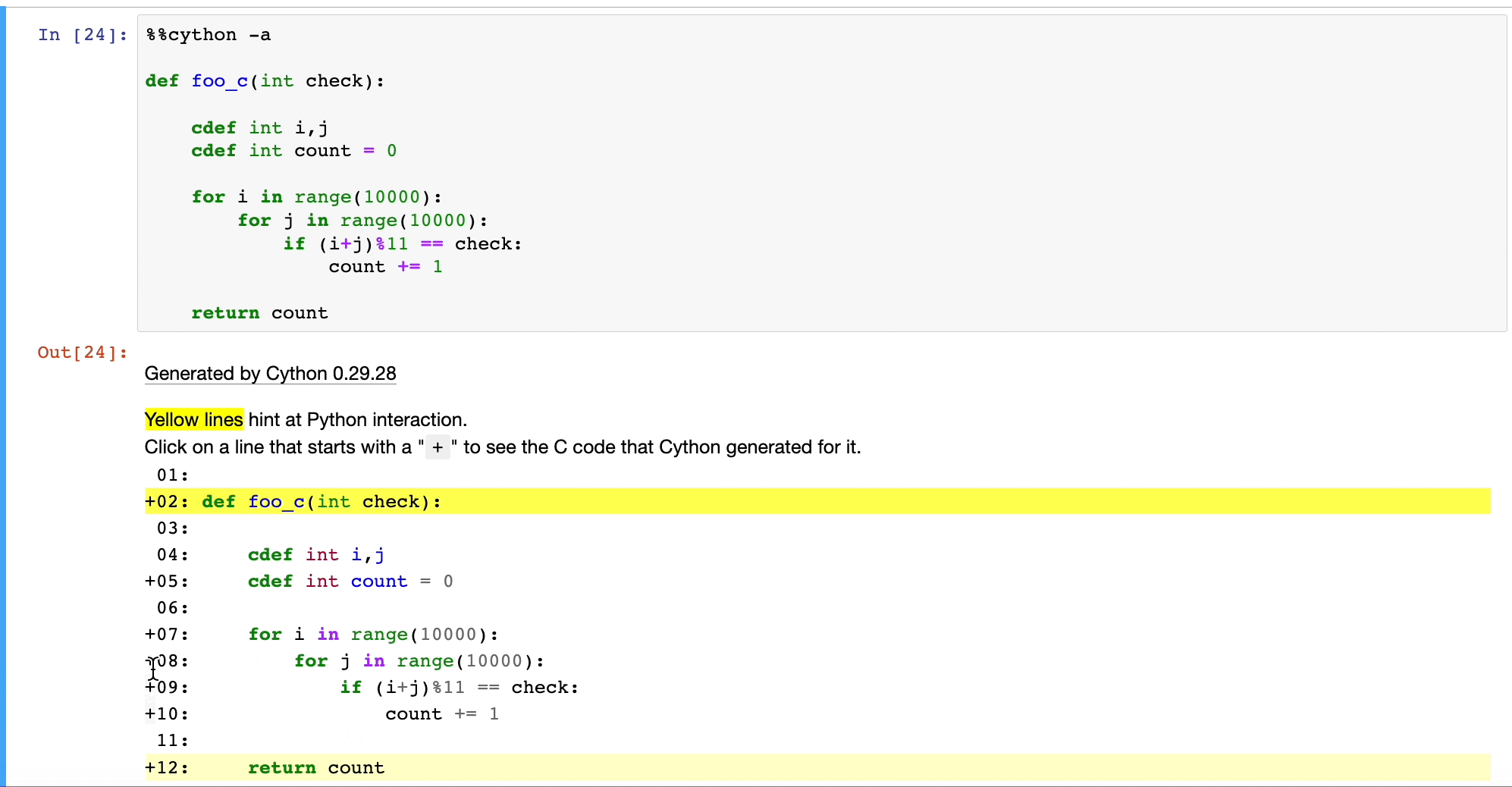
This will run at native machine code speed.
To do so, we can invoke the method as we usually would:
The speedup is evident from the image below:

Python code is slow.
But Cython provides over 100x speedup.
Why does this work?
Essentially, Python is dynamic in nature.
For instance, we can define a variable of a specific type. But later, we can change it to some other type.

But these dynamic manipulations come at the cost of run time. They also introduce memory overheads.
However, Cython restricts Python’s dynamicity.
More specifically, we avoid the above overheads by explicitly specifying the variable data type.

The above declaration restricts the variable to a specific data type. This means the program would never have to worry about dynamic allocations.
This speeds up run-time and reduces memory overheads.
Isn’t that cool?
I prepared this notebook for you to get started with Cython: Cython Jupyter Notebook.
👉 Over to you: Can you tell me some more limitations of Python’s default interpreter?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 87,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.