
Create Evaluation Metrics for Your LLM Apps
...in pure english.

If you are building with LLMs, you absolutely need to evaluate them.
Today, let’s understand how to create any evaluation metric for your LLM apps in pure English with Opik—an open-source, production-ready end-to-end LLM evaluation platform.
Let’s begin!
The problem
Standard metrics are usually not that helpful since LLMs can produce varying outputs while conveying the same message.
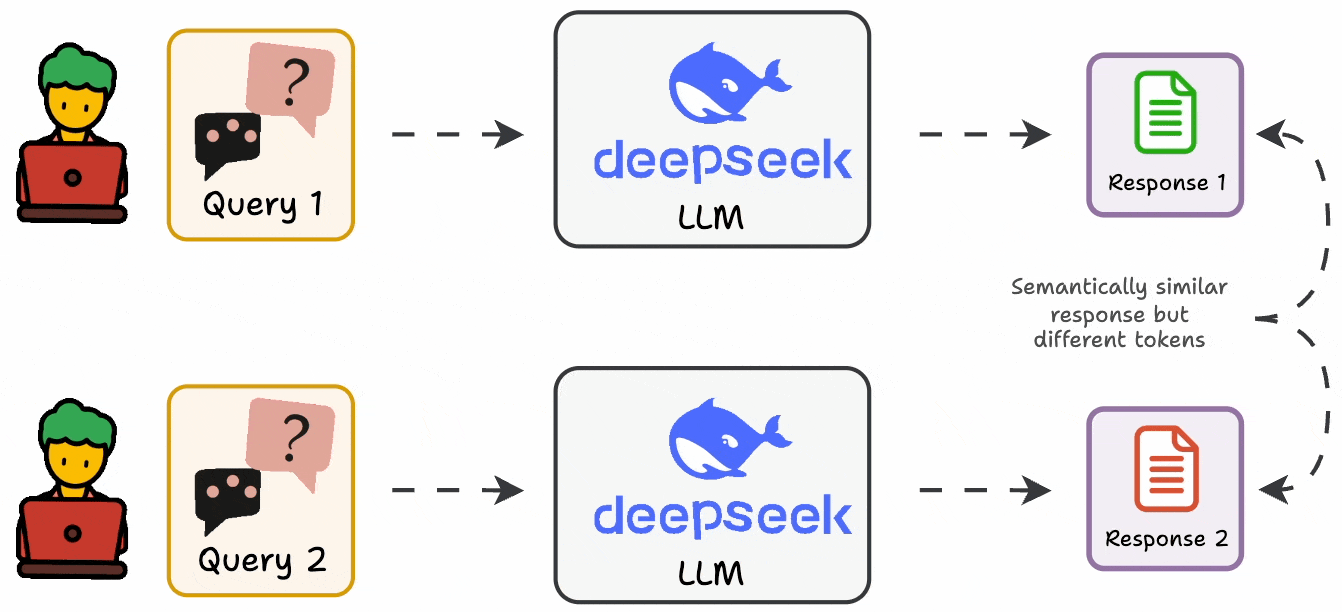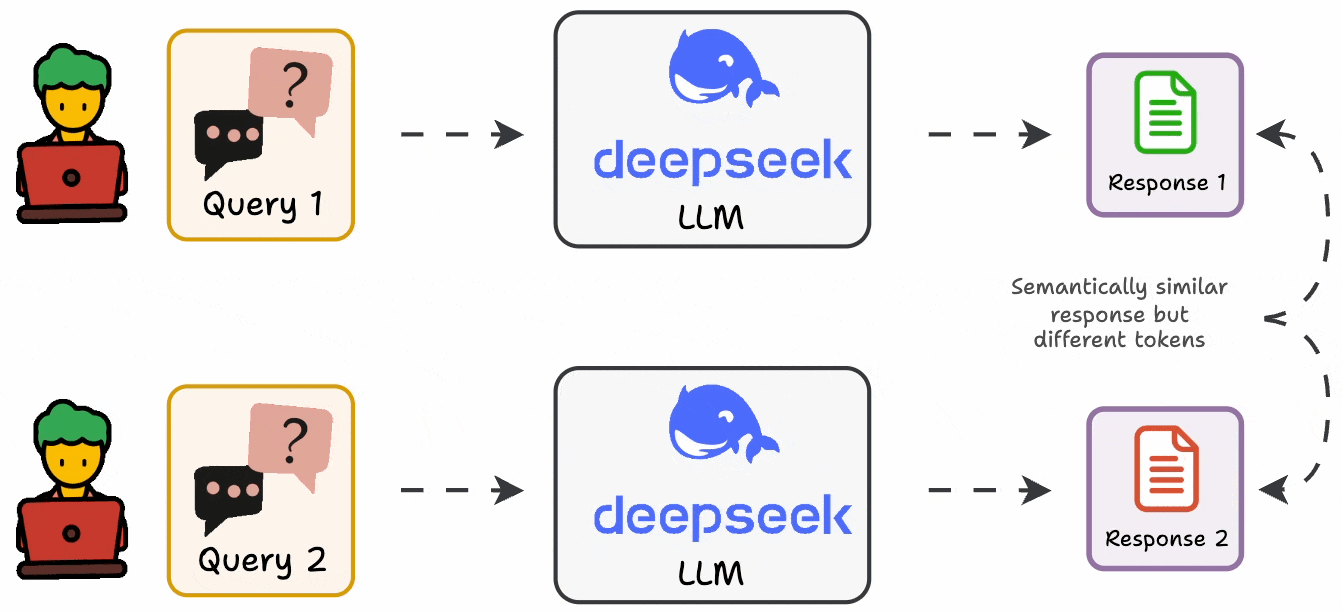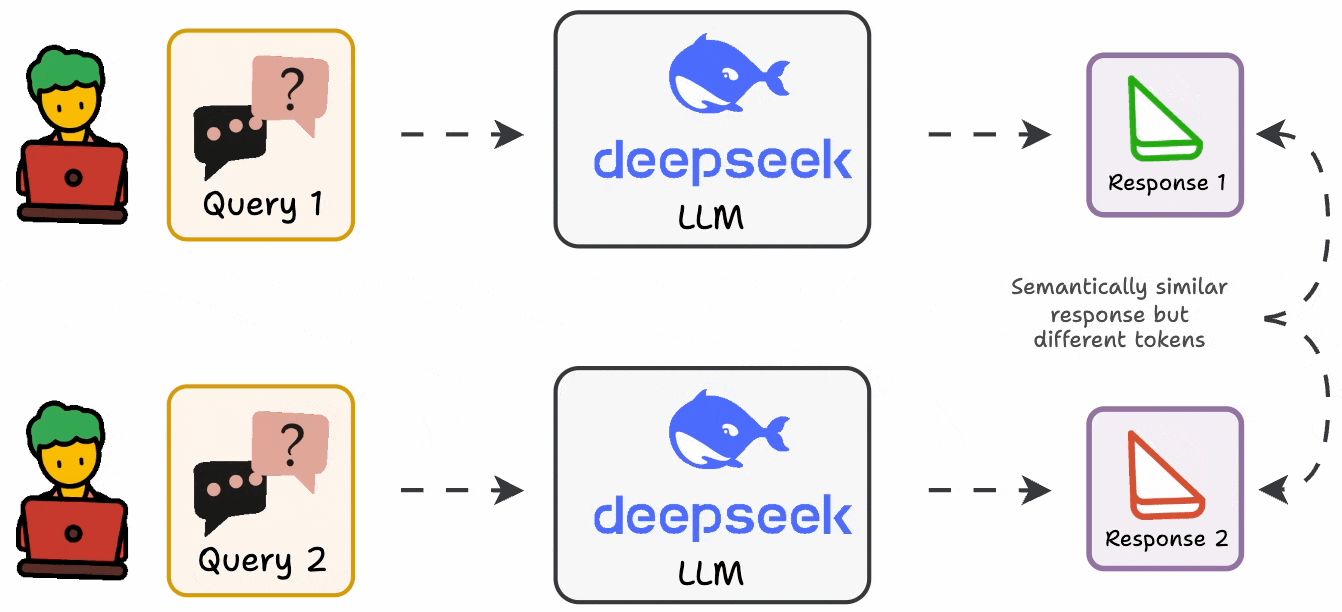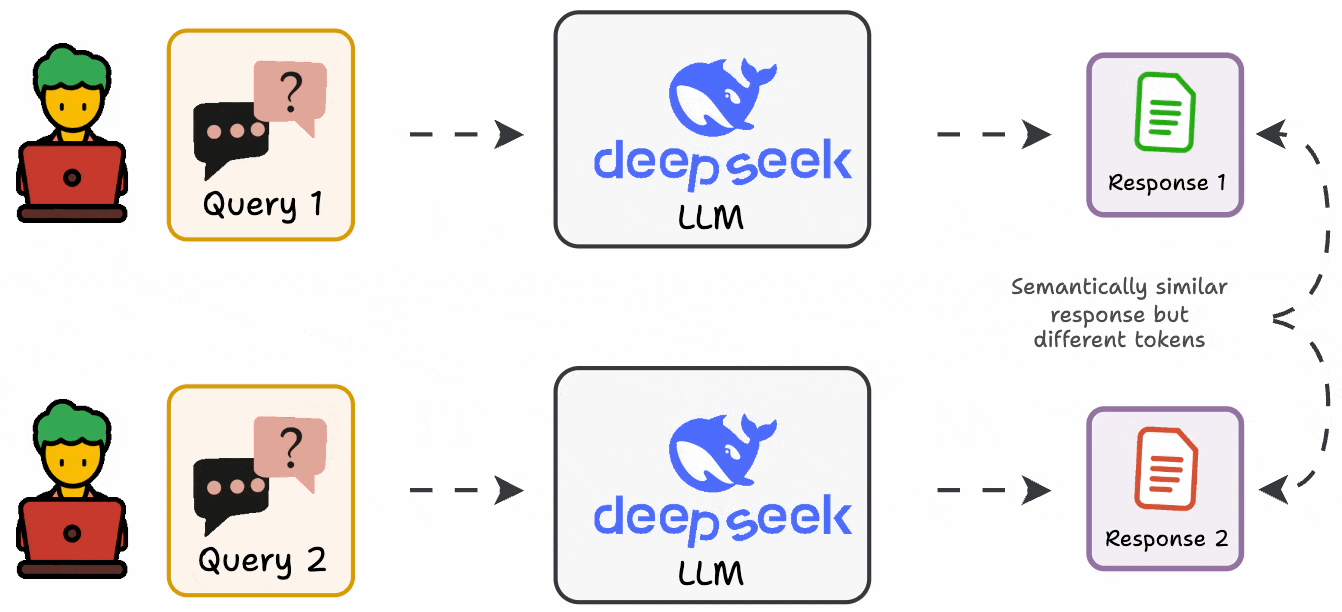
In fact, in many cases, it is also difficult to formalize an evaluation metric as a deterministic code.
The solution
G-Eval is a task-agnostic LLM as a Judge metric in Opik that solves this.
The concept of LLM-as-a-judge involves using LLMs to evaluate and score various tasks and applications.
It allows you to specify a set of criteria for your metric (in English), after which it will use a Chain of Thought prompting technique to create evaluation steps and return a score.
Let’s look at a demo below.
First, import the GEval class and define a metric in natural language:

Done!
Next, invoke the score method to generate a score and a reason for that score. Below, we have a related context and output, which leads to a high score:

However, with unrelated context and output, we get a low score as expected:

Under the hood, G-Eval first uses the task introduction and evaluation criteria to outline an evaluation step.
Next, these evaluation steps are combined with the task to return a single score.
That said, you can easily self-host Opik, so your data stays where you want.
It integrates with nearly all popular frameworks, including CrewAI, LlamaIndex, LangChain, and HayStack.
If you want to dive further, we also published a practical guide on Opik to help you integrate evaluation and observability into your LLM apps (with implementation).
It has open access to all readers.
Start here: A Practical Guide to Integrate Evaluation and Observability into LLM Apps.
Thanks for reading!