
Data Version Control
The underappreciated, yet critical skill that data scientists overlook.

Git is best suited for versioning codebase, which is primarily composed of lightweight files.

However, ML projects are not solely driven by code.
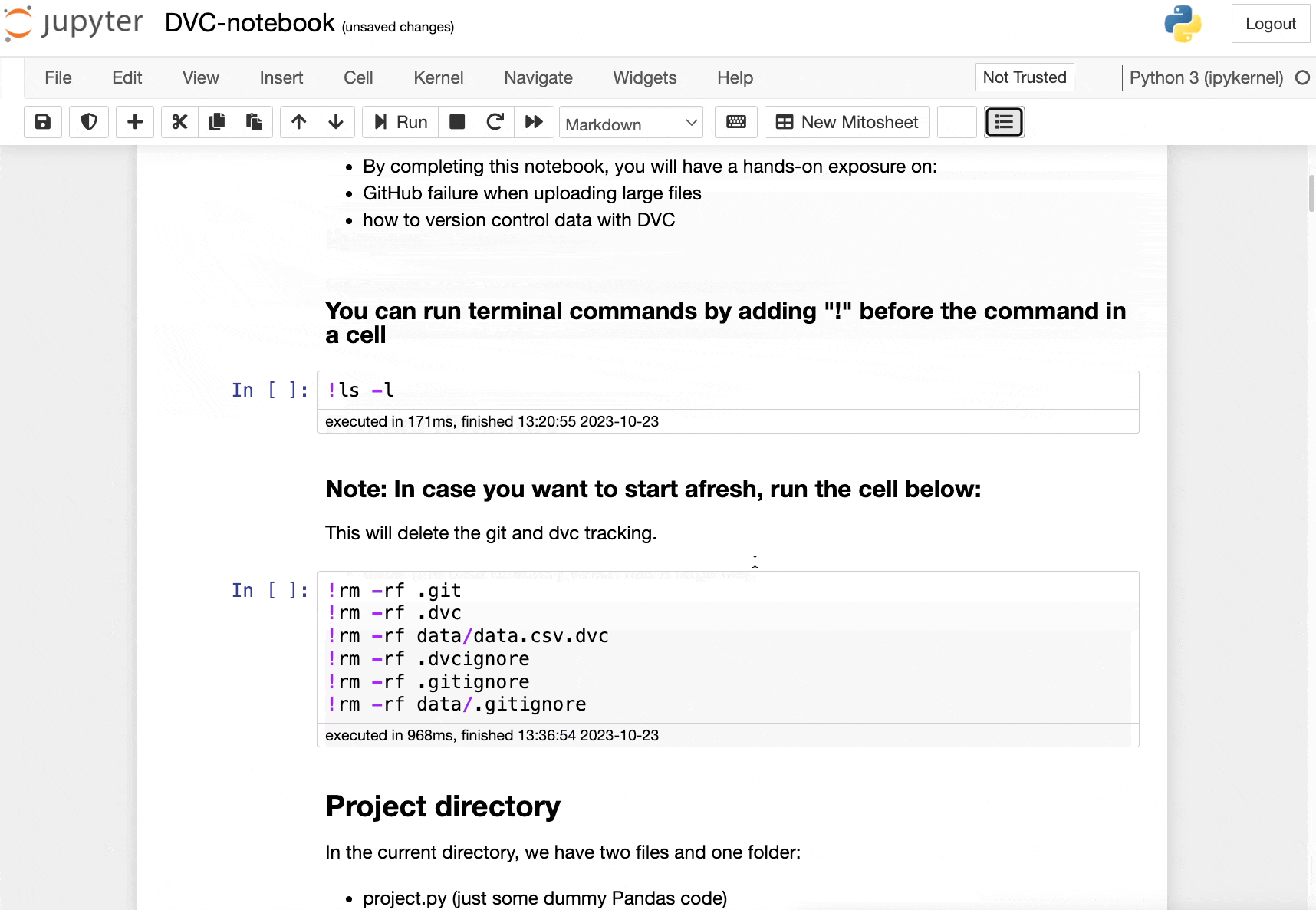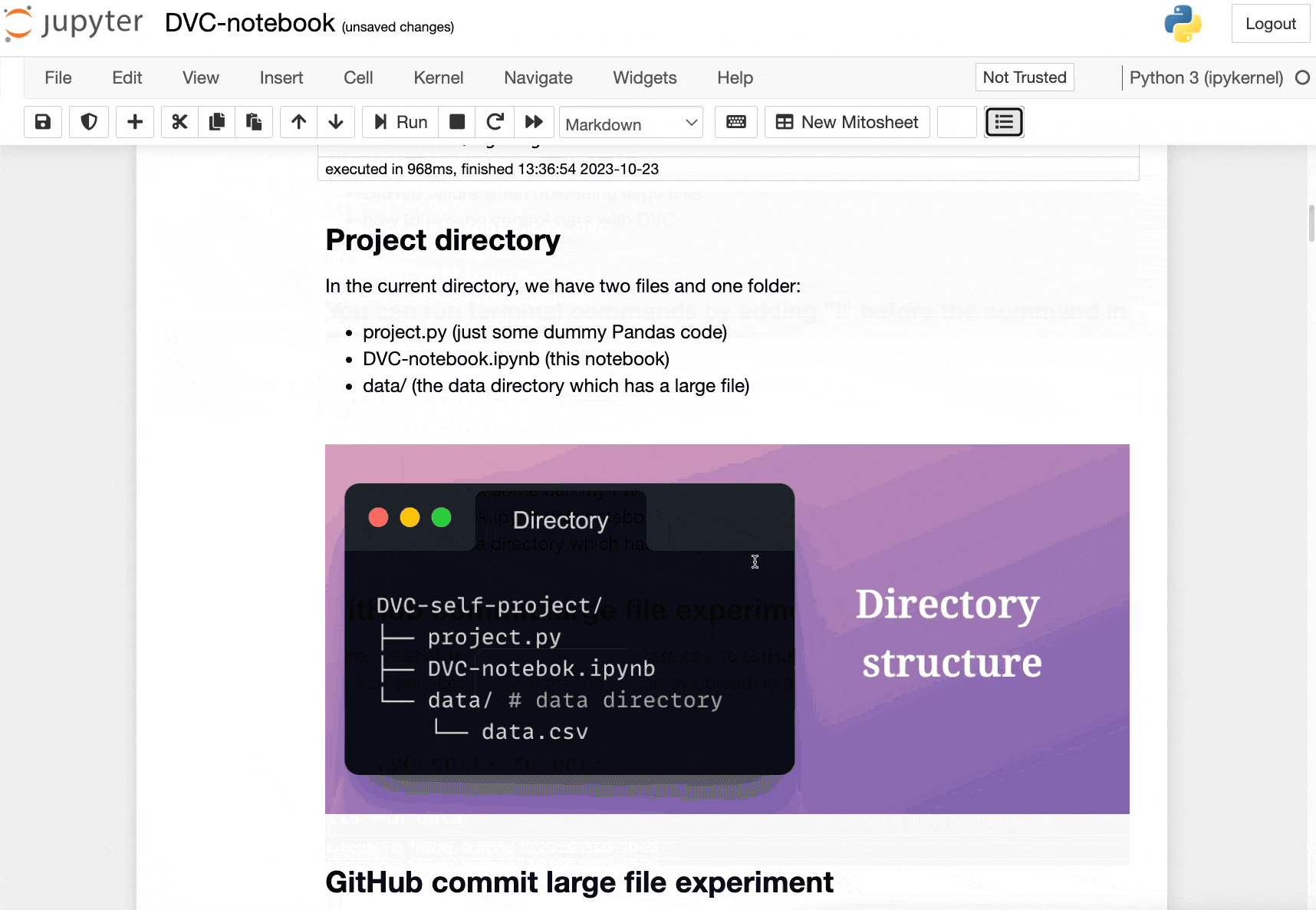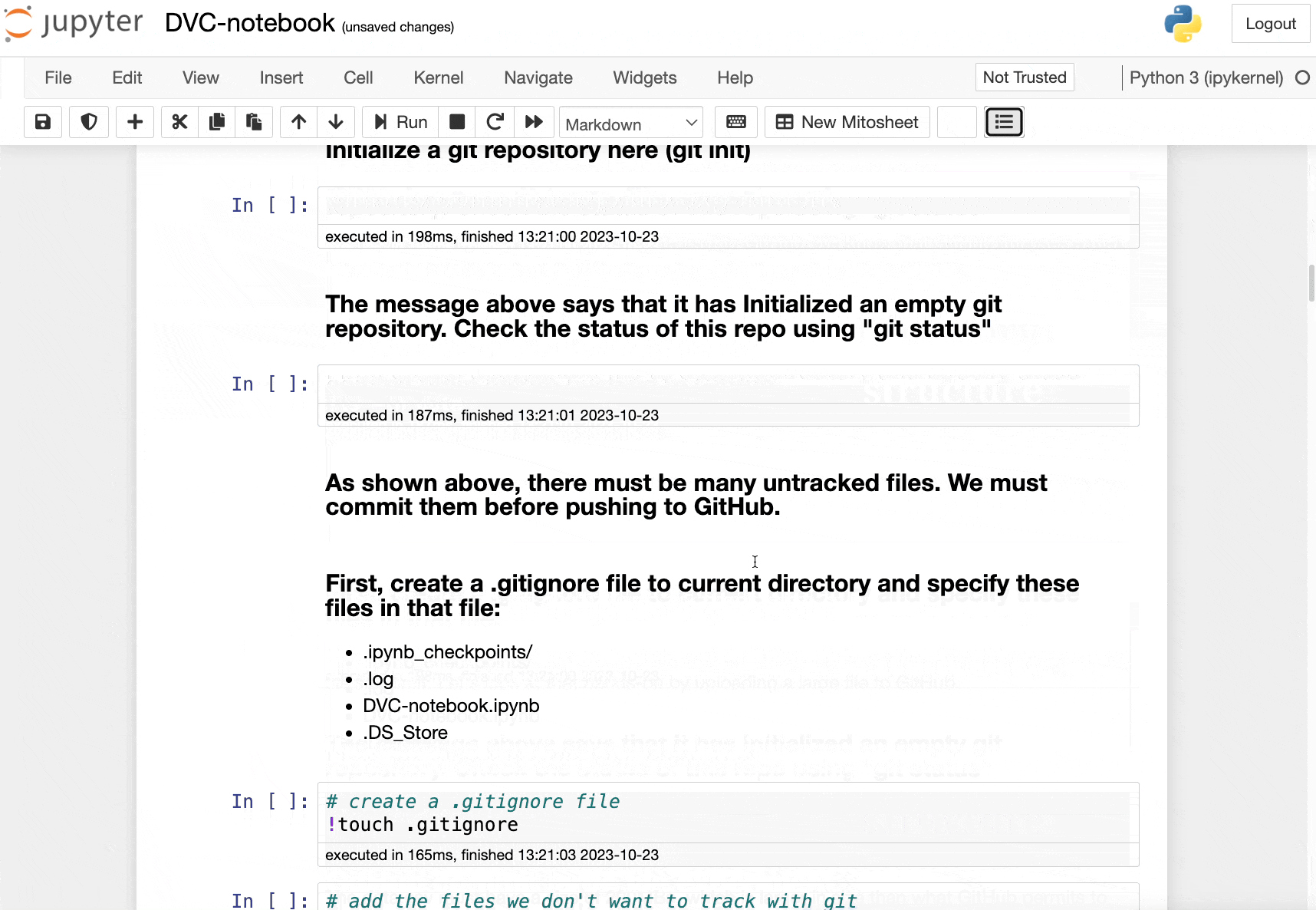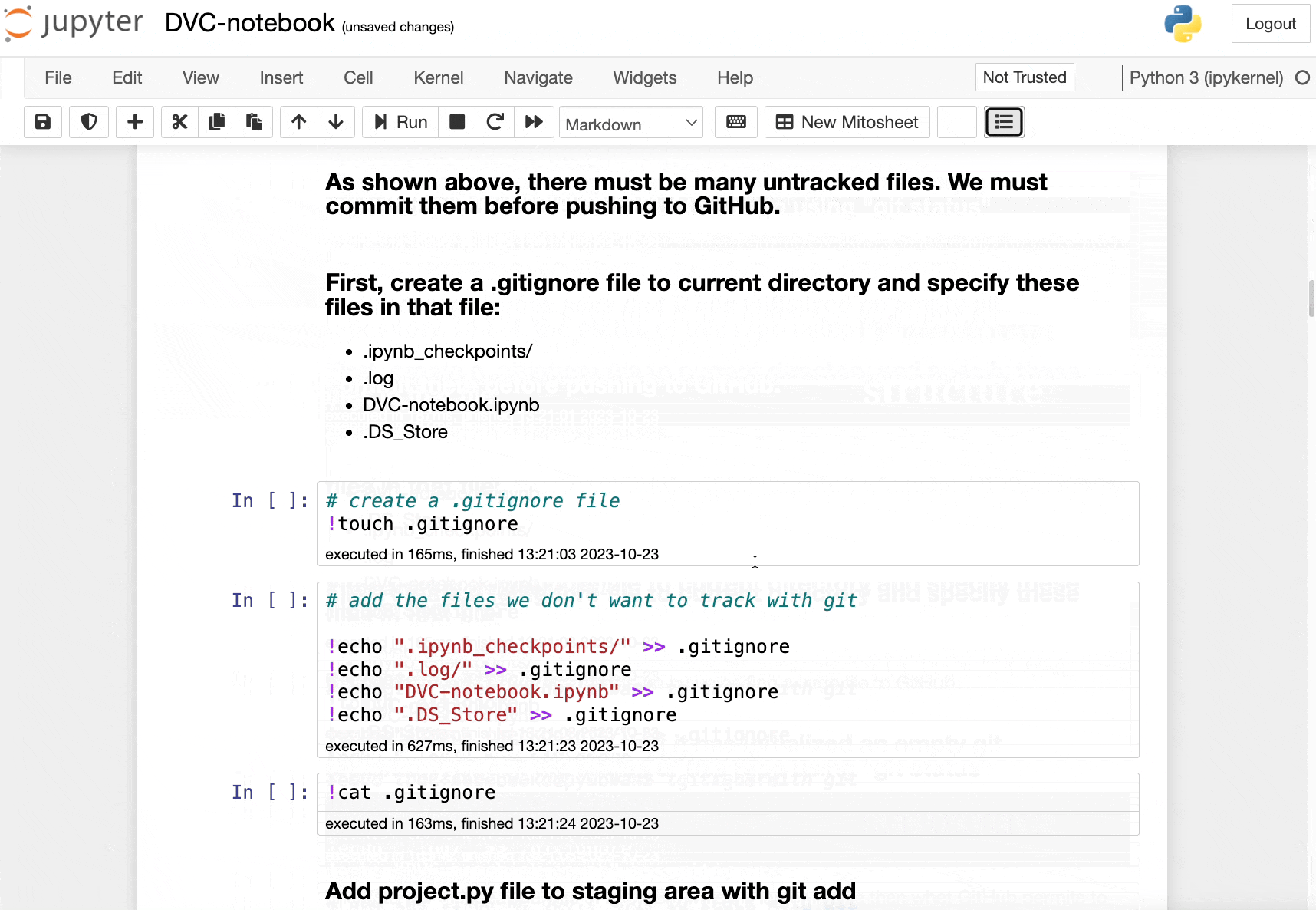
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.

That is what data version control (DVC) helps us with.
We did a hands-on, beginner-friendly deep dive here: You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why another tool?
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
This is depicted below:

Data version control (DVC) solves this.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
To help you skill up to build and deliver large data projects, we covered this in a dedicated deep dive here: You Cannot Build Large Data Projects Until You Learn Data Version Control!

This 32-minute deep dive will teach you everything you need to know about building 100% reproducible ML projects.
Why care?
As we transition to real-world data projects, we need data version control.
Many data science teams actively use it.
The idea behind data version control appeared to be extremely compelling and clever to me when I first learned it a few years back.
Learning and utilizing this skill has been extremely helpful to me in building reliable large ML models.
Thus, learning about data version control will be immensely valuable if you envision doing the same.
To help you truly get hold of this skill, the article covers everything from scratch and also contains a full exercise:
👉 Interested folks can read it here: You Cannot Build Large Data Projects Until You Learn Data Version Control!
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 78,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.