
Decoding, Generation Parameters, and the LLM Application Lifecycle
The full LLMOps course (with code).

Part 4 of the full LLMOps course is now available, where we cover the decoding strategies, generation parameters, best practices, and the broader lifecycle of LLM-based applications.
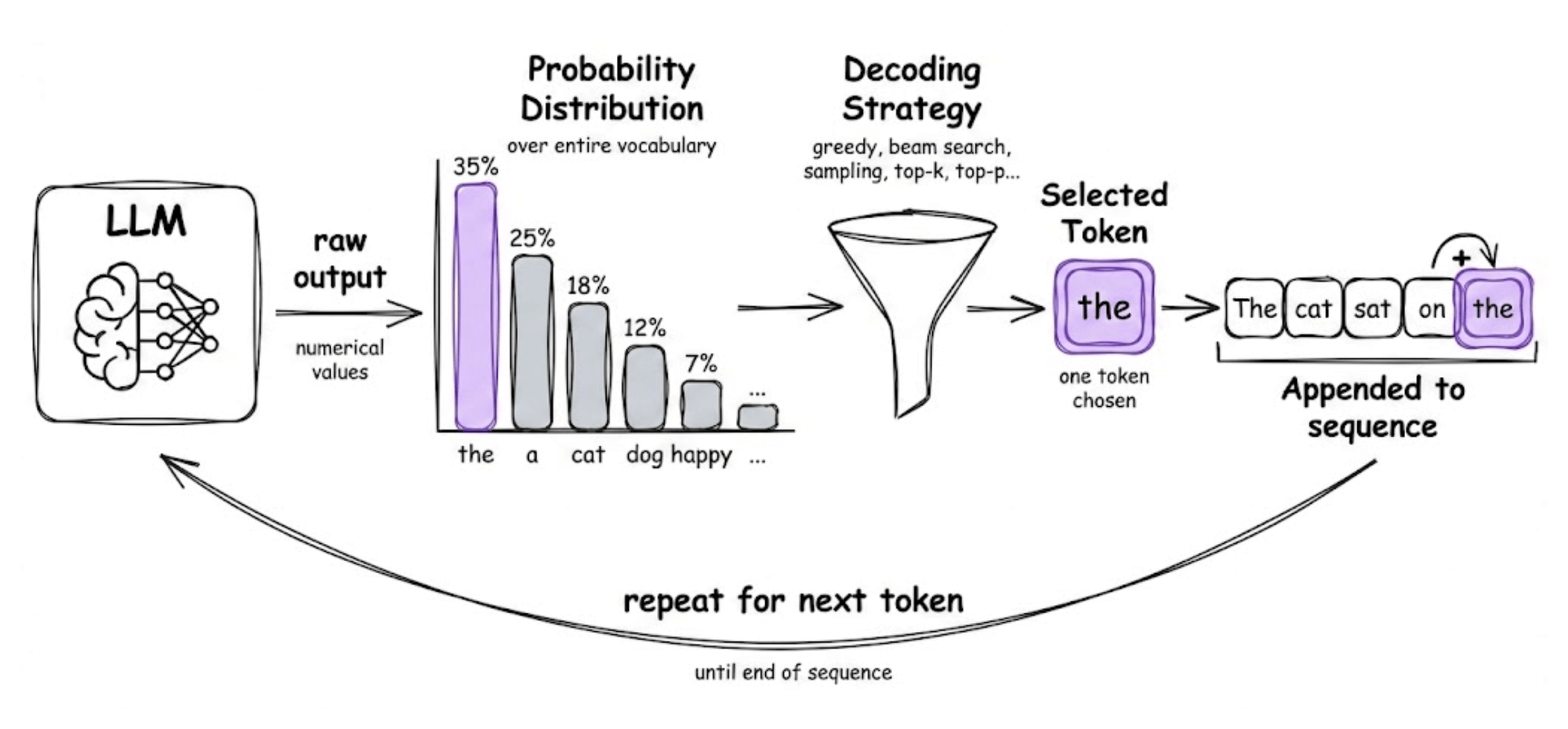
It also covers hands-on code demos to understand different decoding strategies and generation parameters, etc.
Getting an LLM to generate impressive outputs takes minutes.
Getting it to do so reliably, affordably, and safely in production? That’s where most teams struggle.
The API call is the easy part.
But the hard part is everything around it, like managing costs that spiral with scale, handling hallucinations before they reach users, optimizing latency without sacrificing quality, and building evaluation systems for outputs that have no single “correct” answer.
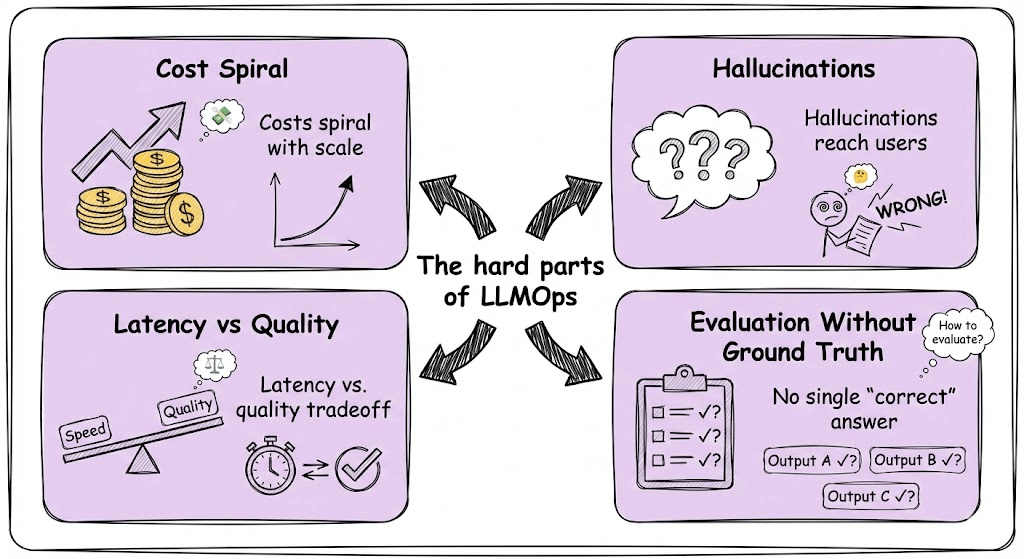
Traditional MLOps prepared us for models we train and control.
LLMOps prepares us for models we configure, prompt, and orchestrate, which is a fundamentally different engineering discipline.
This chapter of the LLMOps course series breaks down that discipline systematically, giving you the mental models and practical implementations to build LLM applications that actually survive contact with production.
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our applications to the next stage and what exactly the framework should be for that.
👉 Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!