
DeepSeek Cracked The O(L²) Attention Bottleneck
2x-3x reduction in cost and better performance.

Opik: Open-source LLM evaluation platform

Opik is a 100% open-source production monitoring platform for LLM apps that gives real-time insights, feedback tracking, and trace analytics at daily/hourly granularity for enterprise-scale apps.
Real-time dashboard with scores & token metrics
Automated LLM-as-a-Judge evaluation scoring
Python SDK + UI feedback logging
Advanced trace search & update APIs
Complete trace content management
High-volume production-ready
DeepSeek cracked the O(L²) attention bottleneck
DeepSeek’s new V3.2 model introduces DeepSeek Sparse Attention (DSA), and it’s the only architectural change they made.
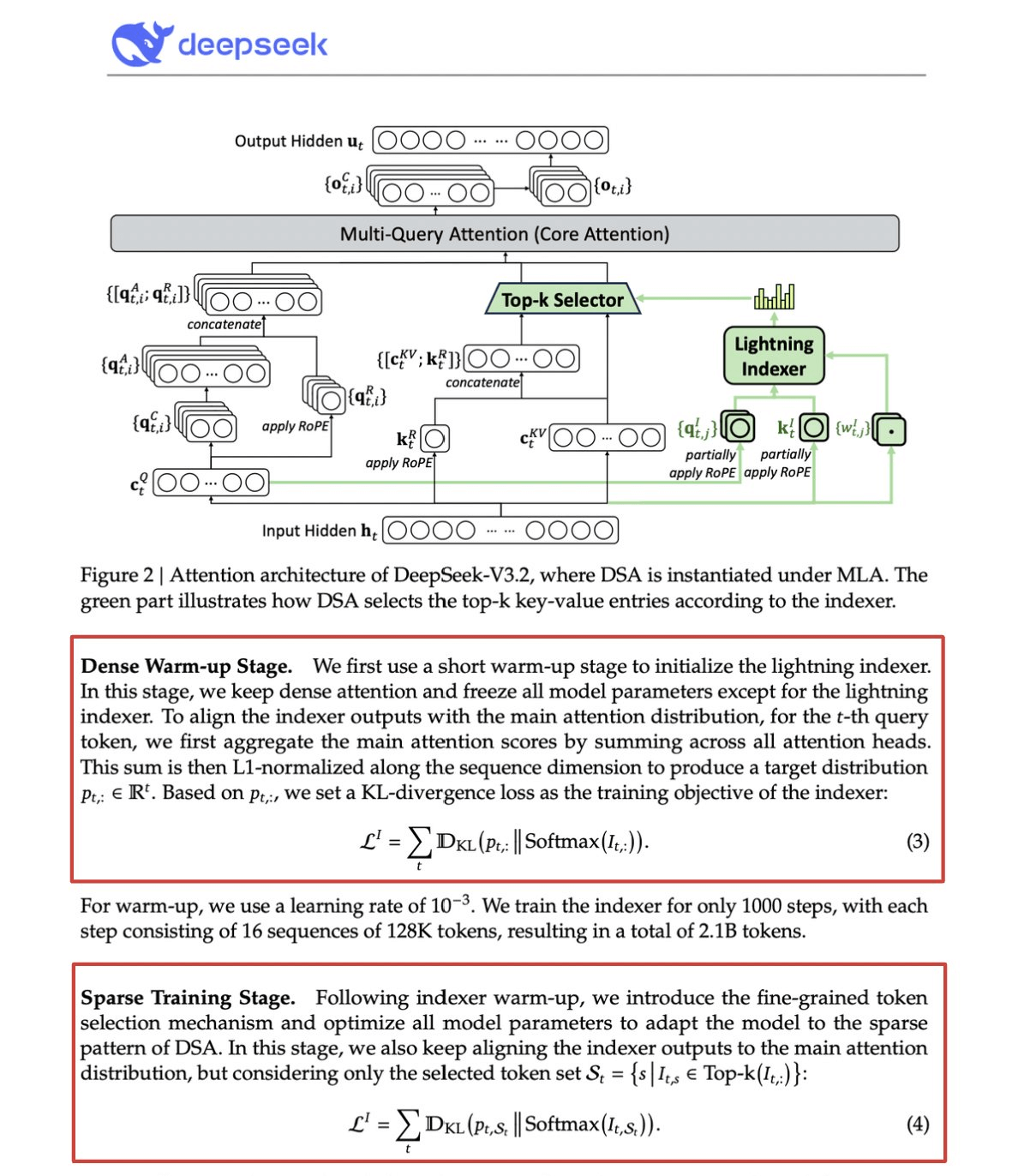
That tells you how important this is.
What does it solve:
Standard attention scales quadratically. Double your context length, quadruple the compute. This is why long-context inference gets expensive fast.
DSA brings complexity down from O(L²) to O(Lk), where k is fixed.
How it works:
A lightweight Lightning Indexer scores which tokens actually matter for each query. Small number of heads, runs in FP8, computationally cheap. Then a selection mechanism retrieves only the top-k key-value entries.
The key insight: only 2,048 tokens get selected per query, regardless of context length. The expensive attention computation happens on this small subset, not the full 128K sequence.
Less attention, better results. DeepSeek V3.2 just proved it.
The results:
At 128K context, prefilling costs drop from ~$0.65 to ~$0.35 per million tokens. Decoding drops from ~$2.4 to ~$0.8.
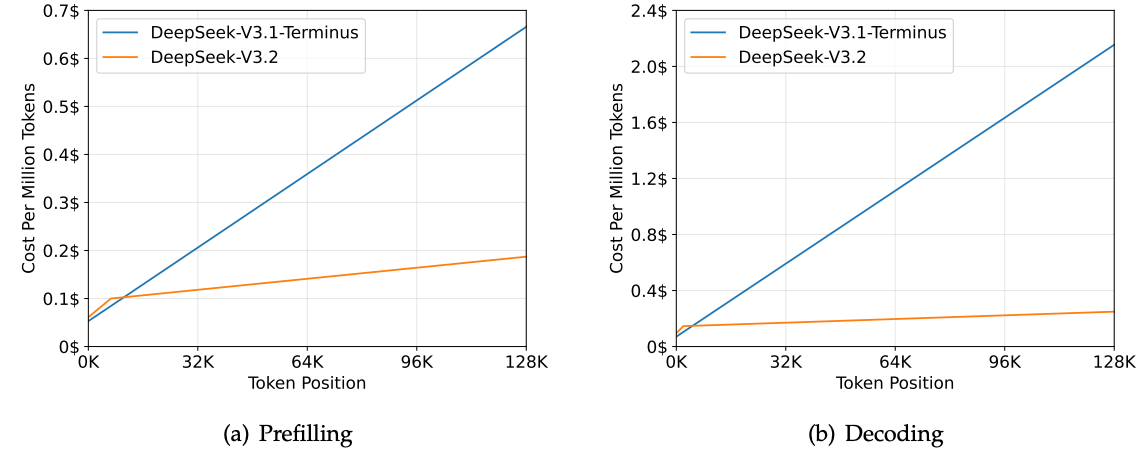
And performance? Stays the same. On some long-context benchmarks, V3.2 actually scores higher.
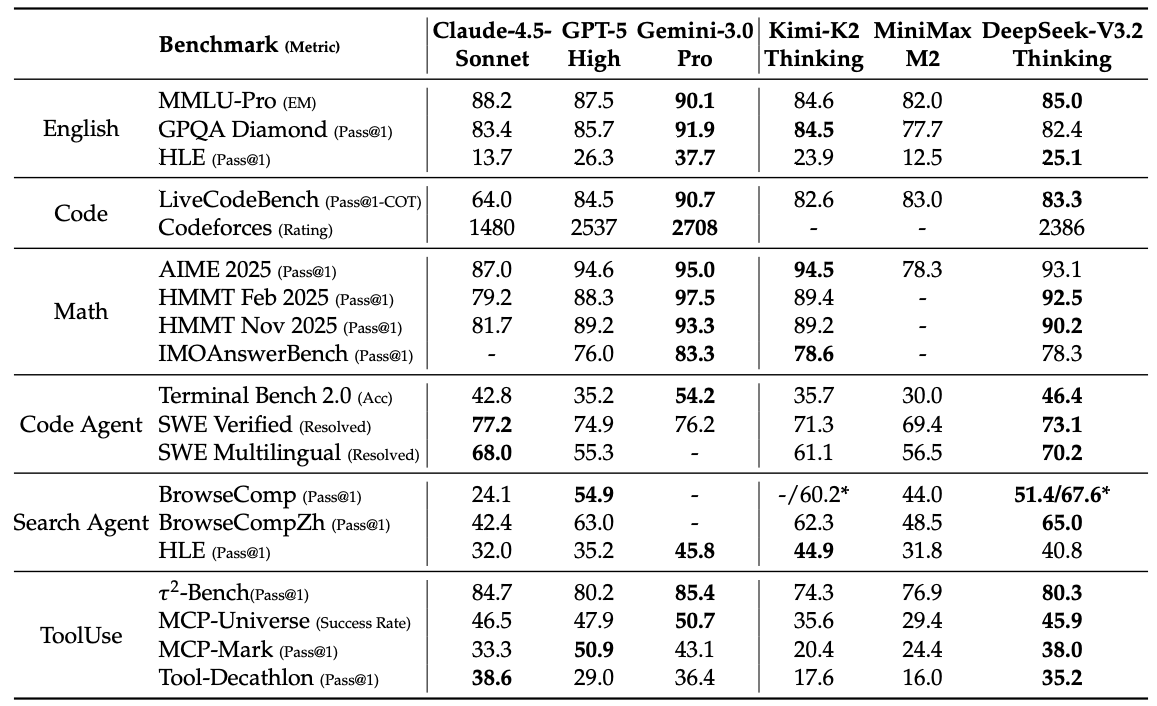
Sparse attention isn’t new. Making it work without losing quality is hard.
DeepSeek cracked it with a two-stage training process, first aligning the indexer using KL-divergence, then training the full model to adapt to sparse patterns.
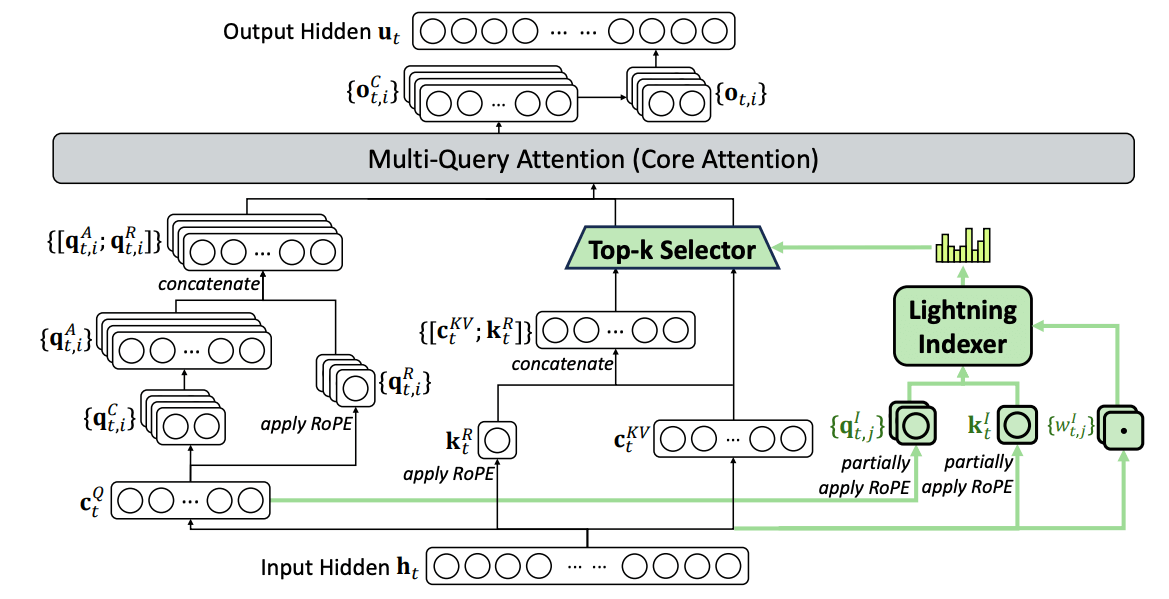
This is how you scale context without scaling costs.
Why this matters beyond DeepSeek:
Ilya Sutskever recently mentioned in a podcast that scaling data and compute has hit a wall. You can throw more GPUs at the problem, but natural data is finite.
The next leap comes from architectural breakthroughs and research, not just scaling.
DSA looks like a step in that direction.
What are your thoughts?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.