
Define Criticality Levels for Agents’ Instructions
Build Agents that actually follow your instructions (open-source)

Build any MCP server in two steps
Here’s the easiest way to build any MCP server:
Factory’s Droids handle the entire workflow to generate production-ready code with README, usage, error-handling…everything!
Here’s one of our test runs where we asked the Droids to build a stock analysis MCP server in Factory:
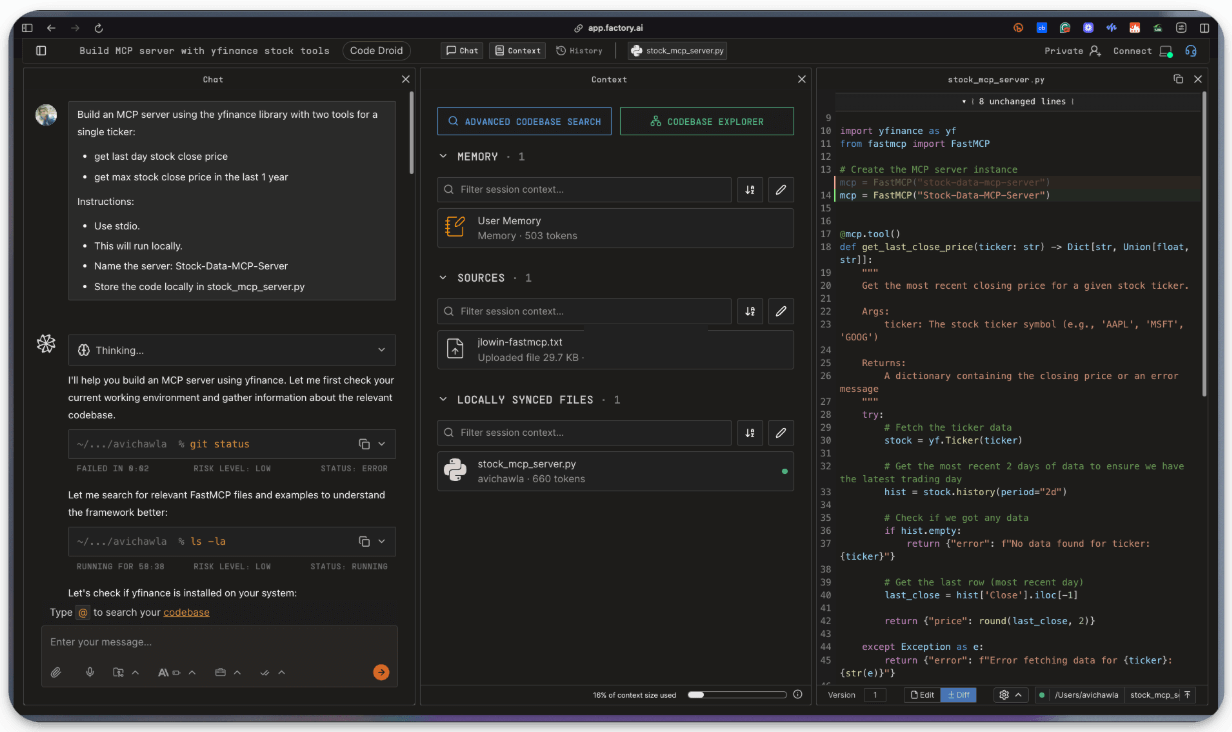
And it did it perfectly with zero errors, while creating a README and usage guide, and implementing error-handling, without asking:

Build your own MCP server here →
Define Criticality Levels for Agents’ Instructions
Here’s a fundamental tension in AI Agent design today!
And it becomes obvious only when you start building for production:
The more strictly you enforce an instruction, the more you sacrifice contextual nuance.
Think of it this way.
When you are building a customer-facing Agent, some instructions are indeed non-negotiable.
Thus, you want your Agent to enforce them strictly, even if it sounds robotic when doing so.
For instance, instructions like compliance disclosures in finance or safety warnings in healthcare cannot tolerate any mistakes.
But other instructions are gentle suggestions, like matching the customer’s tone or keeping responses concise. These should influence the conversation, not dominate it.
The problem is that most Agent architectures don’t let you express this distinction that easily.
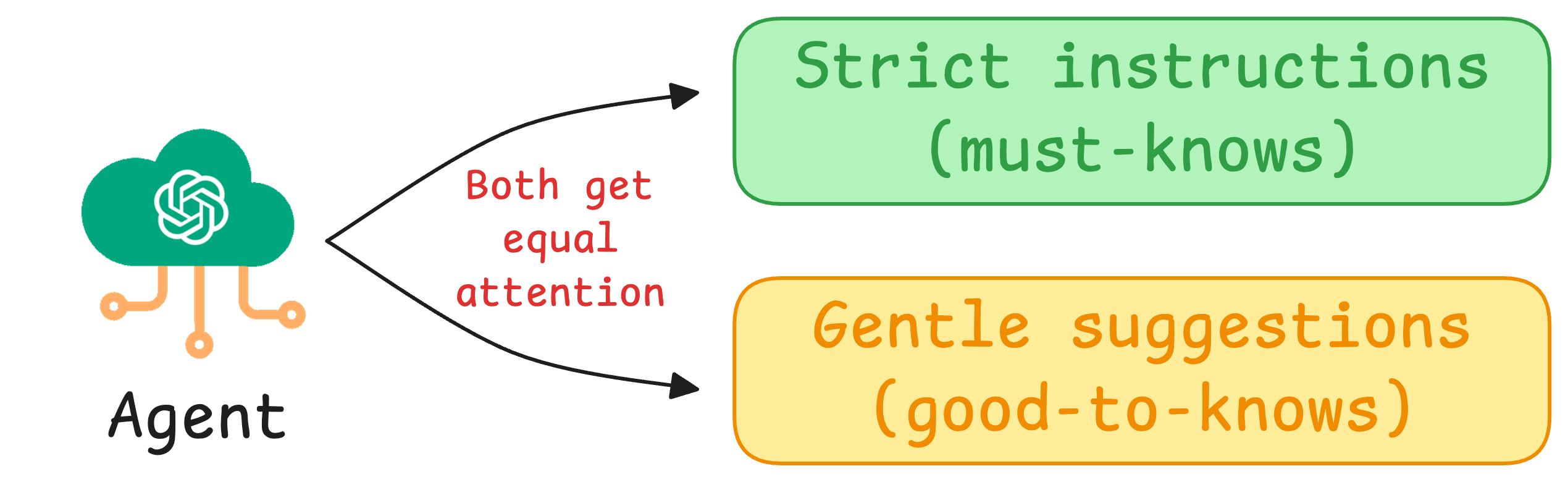
Every instruction typically gets the same level of enforcement, so you’re either forced to be strict about everything and sound robotic, or be flexible about everything and risk missing critical rules.
And no, you can’t just emphasize certain instructions in the prompt itself because the mere presence of an instruction in the prompt already biases the model’s behavior. Emphasis just adds more bias on top of existing bias.
We find Parlant’s latest control of “criticality levels” interesting (open-source with 18k stars).
It allows you to specify the level of attention to pay to each instruction.
agent.create_guideline(
condition=”Customer asks about medicines”,
action=”Direct to healthcare provider”,
criticality=Criticality.HIGH
)
agent.create_guideline(
condition=”Customer completes a purchase”,
action=”Mention the loyalty program”,
criticality=Criticality.LOW
)This means you can set an instruction’s criticality as LOW, MEDIUM, or HIGH, which makes it easier to achieve the behavioral sweet spot you’re looking for in the agent’s conversations with users.
What’s interesting is how criticality levels actually get enforced under the hood. Parlant uses an innovative reasoning technique called Attentive Reasoning Queries (ARQs) under the hood.
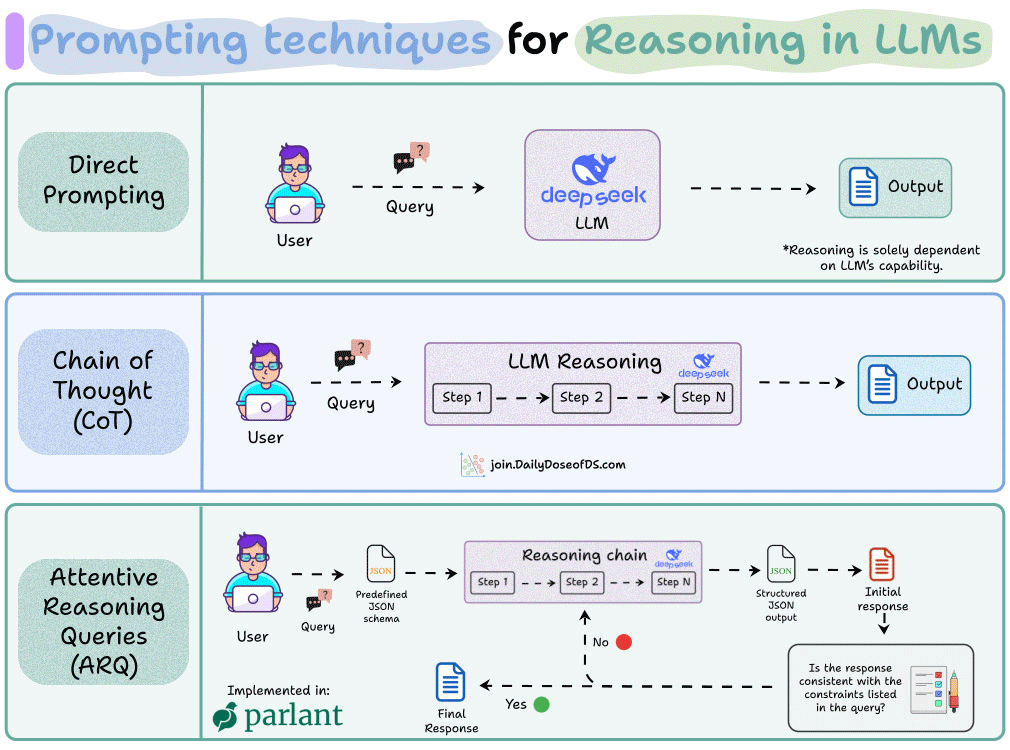
Essentially, instead of letting the LLM reason freely, it walks through structured checkpoints that explicitly reference the active guidelines.
So when you mark something as HIGH criticality, the model doesn’t just try harder on that.
Instead, it’s actually prompted to verify compliance at each reasoning step before generating output.
The research paper is available on arXiv if you want to learn more, and the visual above explains how it works.
In general, we love how this framework is evolving and how the features naturally build up on a basic, solid philosophy from version to version.
You can see the full implementation on GitHub and try it yourself.
Thanks for reading!