
Define Elegant and Concise Python Classes with Descriptors
An underrated gem of Python OOP.

In yesterday’s post, we understood the use of the Python @property decorator. Here’s the visual from that post for a quick recap:

To reiterate, we saw how it allows us to validate and control the attribute (as achieved by defining explicit setter and getter methods) using dot notation itself.
Today, I want to continue our discussion on yesterday’s topic and tell you a limitation of the above approach, which I did not cover yesterday.
Moving on, we shall see how Descriptors in Python provide a much more elegant way of setting and getting values.
Let’s begin!
Limitations of @property decorator
Consider the above class implementation again:
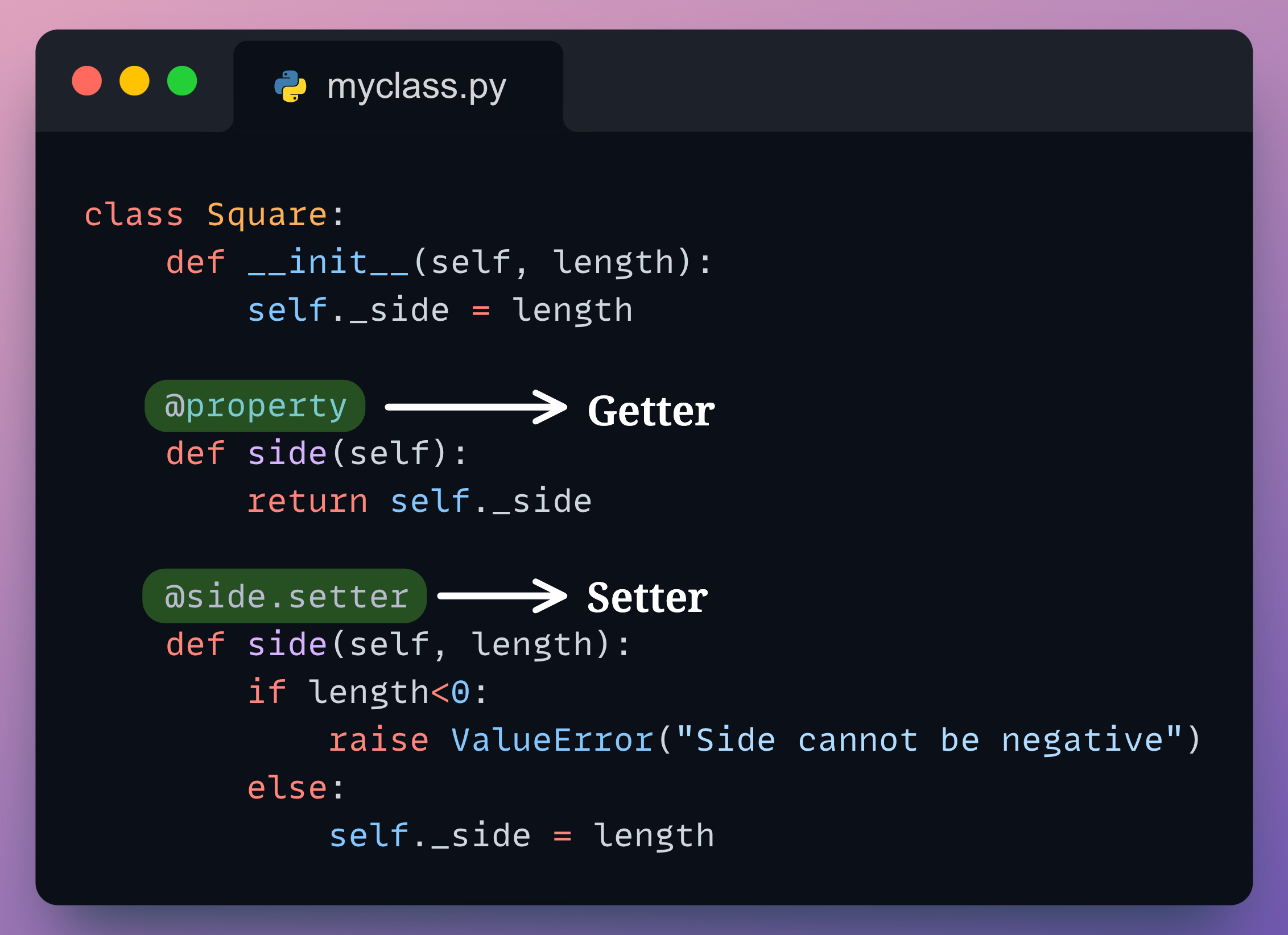
The biggest issue here is that we must define a getter and setter for every instance-level attribute.
So what if our class has, say, 3 such attributes, and all must be positive?
Of course, we will have 3 getters and 3 setters, which makes the overall implementation long, messy, and redundant.

There’s redundancy because every setter method will have almost the same lines of code (the if statements for validation).
Also, if you think about it, the getter methods are somewhat redundant and unnecessary too, as they just return an attribute.
If that is clear, there’s one more issue with the above implementation.
Recall what I mentioned earlier: “Our class will have 3 such instance-level attributes, and all must be positive?”
See what happens when we create an object with an invalid input:

As depicted above, Python does not raise any error, when ideally, it should.
An improper solution
One common way programmers try to eliminate redundancy is by defining explicit validation functions.
For instance, we can define a function that just validates the value received, as demonstrated below:

Next, we can invoke this method wherever needed:
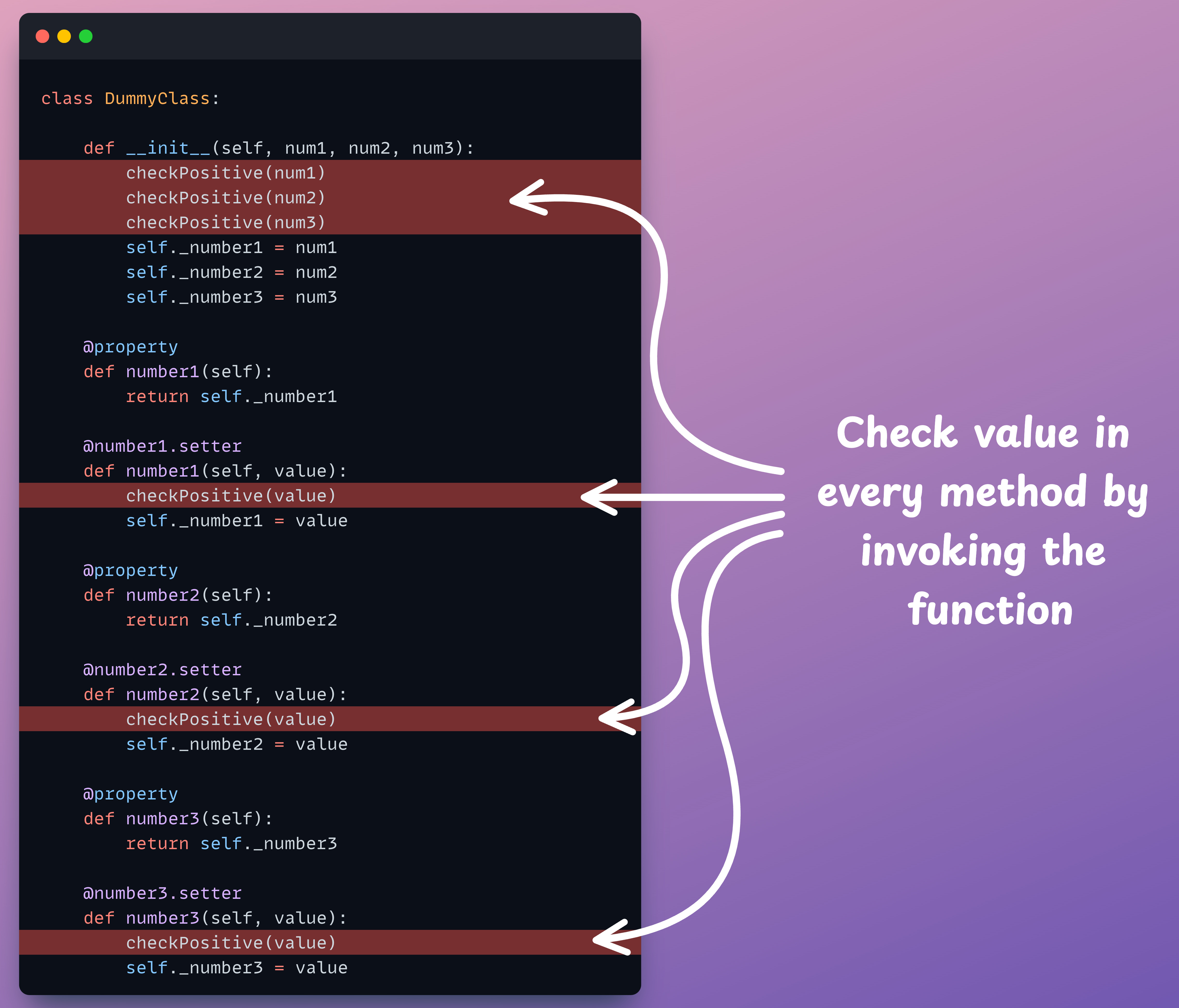
But this does not solve the problem either:
We still have explicit and redundant function calls in each setter method.
All getter methods still do the same thing and have high redundancy.
And most importantly, the
__init__method is now messed up with multiple function calls.
Descriptors
Simply put, Descriptors are objects with methods (like __get__, __set__, etc.) that are used to manage access to the attributes of another class.
So, every descriptor object is assigned to only one attribute of another class.
And just to be clear, this “another class” is the class we are primarily interested in — the DummyClass we saw earlier, for instance.

Thus:
The attribute
number1→ gets its own descriptor.The attribute
number2→ gets its own descriptor.The attribute
number3→ gets its own descriptor.
A typical Descriptor class is implemented with three methods, as shown below:

The
__set__method is called when the attribute is assigned a new value. We can define the custom checks here.The
__set_name__method is called when the descriptor object is assigned to a class attribute. It allows the descriptor to keep track of the name of the attribute it’s assigned to within the class.The
__get__method is called when the attribute is accessed.
Also:
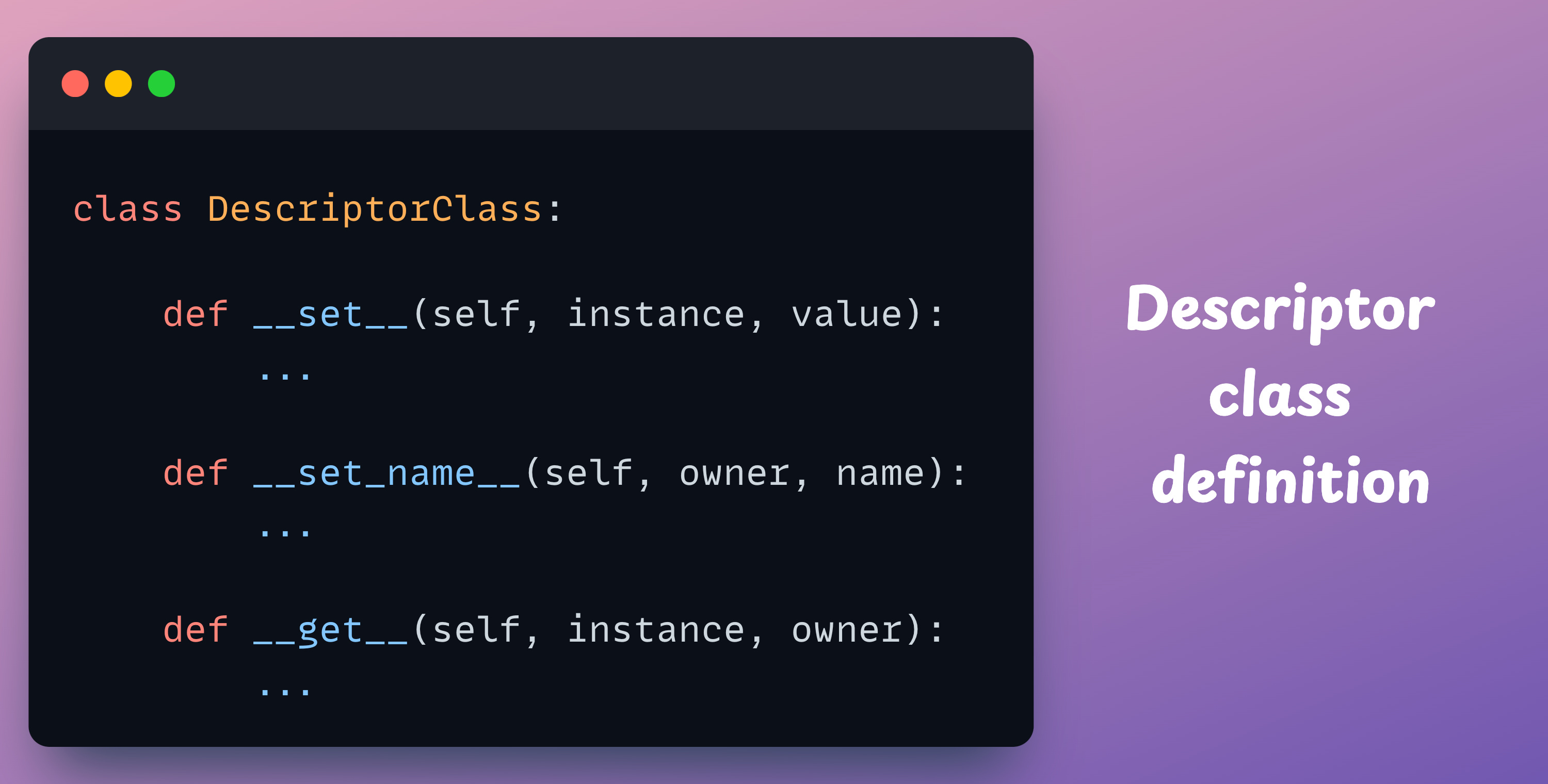
The
instanceparameter refers to the object of the desired class —DummyClass().The
ownerparameter is the desired class itself —DummyClass.The
valueparameter is the value being assigned to an attribute of the desired class.The
nameparameter is the name of the attribute.
If it’s unclear, let me give you a simple demonstration.
Consider this Descriptor class:

I’ll explain this implementation shortly, but before that, let’s consider its usage, which is demonstrated below:

Now, let’s go back to the DescriptorClass implementation:
__set_name__(self, owner, name): This method is called when the descriptor is assigned to a class attribute (line 3). It saves the name of the attribute in the descriptor for later use.__set__(self, instance, value): When a value is assigned to the attribute (line 6), this method is called. It raises an error if the value is negative. Otherwise, it stores the value in the instance’s dictionary under the attribute name we defined earlier.__get__(self, instance, owner): When the attribute is accessed, this method is called. It returns the value from the instance’s dictionary.
Done!
Now, see how this solution smartly solves all the problems we discussed earlier.
Let’s create an object of the DummyClass:

As depicted above, assigning an invalid value to the attribute raises an error.
Next, let’s see what happens when the attribute specified during the initialization is invalid:

Great! It validates the initialization too.
Here, recall that we never defined any explicit checks in the __init__ method, which is super cool.
Moving on, let’s define multiple attributes in the DummyClass now:
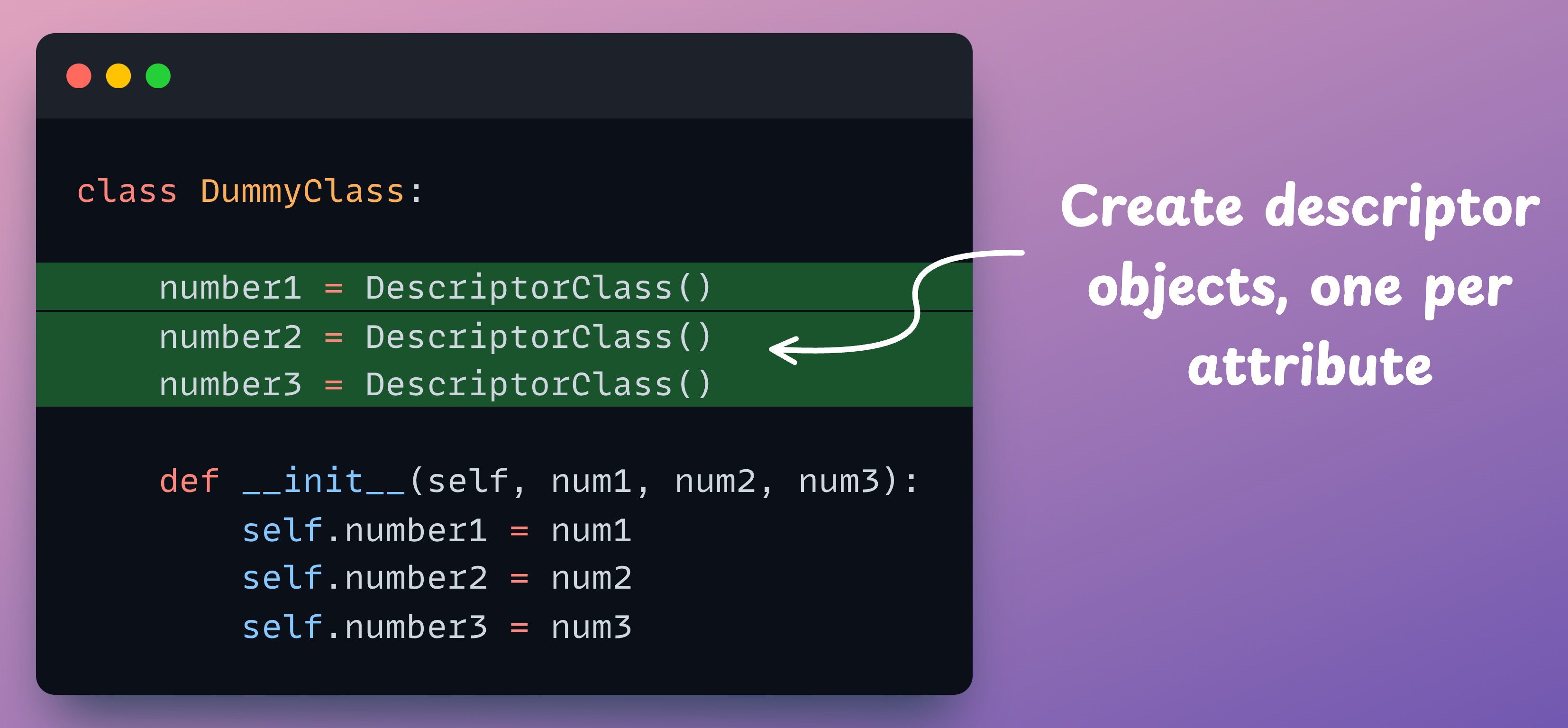
Creating an object and setting an invalid value for any of the attributes raises an error:

Works seamlessly!
Recall that we never defined multiple getters and setters for each attribute individually, like we did with the @property decorator earlier.
This is great, isn’t it?
I find descriptors to be massively helpful in reducing work and code redundancy while also making the entire implementation much more elegant.
If you want to try them out, I prepared this notebook for you to get started: Python Descriptors Notebook.
Have fun playing around with them!
Also, here’s a full deep dive into Python OOP if you want to learn more about advanced OOP in Python: Object-Oriented Programming with Python for Data Scientists.
👉 Over to you: What are some cool things you know about Python OOP?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
I need to learn even more... to keep my codes cleaner.
Good tip, Avi Chawla 🤗!
Isn't writing and maintaining `DescriptorClass` still cumbersome?