
DevOps vs. MLOps vs. LLMOps
...explained visually!

Build an automated Agent optimization workflow
Yesterday, we talked about Comet’s Opik, which implements an automated technique to find the best prompts for any agentic workflow you’re building.
We recorded this video, which explains this in much more depth:
The idea is simple yet powerful:
Start with an initial prompt & eval dataset
Let the optimizer iteratively improve the prompt
Get the optimal prompt automatically!
And this is done using just a few lines of code, as demonstrated in the video.
You can learn more about Agent Optimization in the docs here →
DevOps vs. MLOps vs. LLMOps
Many teams are trying to apply DevOps practices to LLM apps.
But DevOps, MLOps, and LLMOps solve fundamentally different problems, and this visual summarizes this:
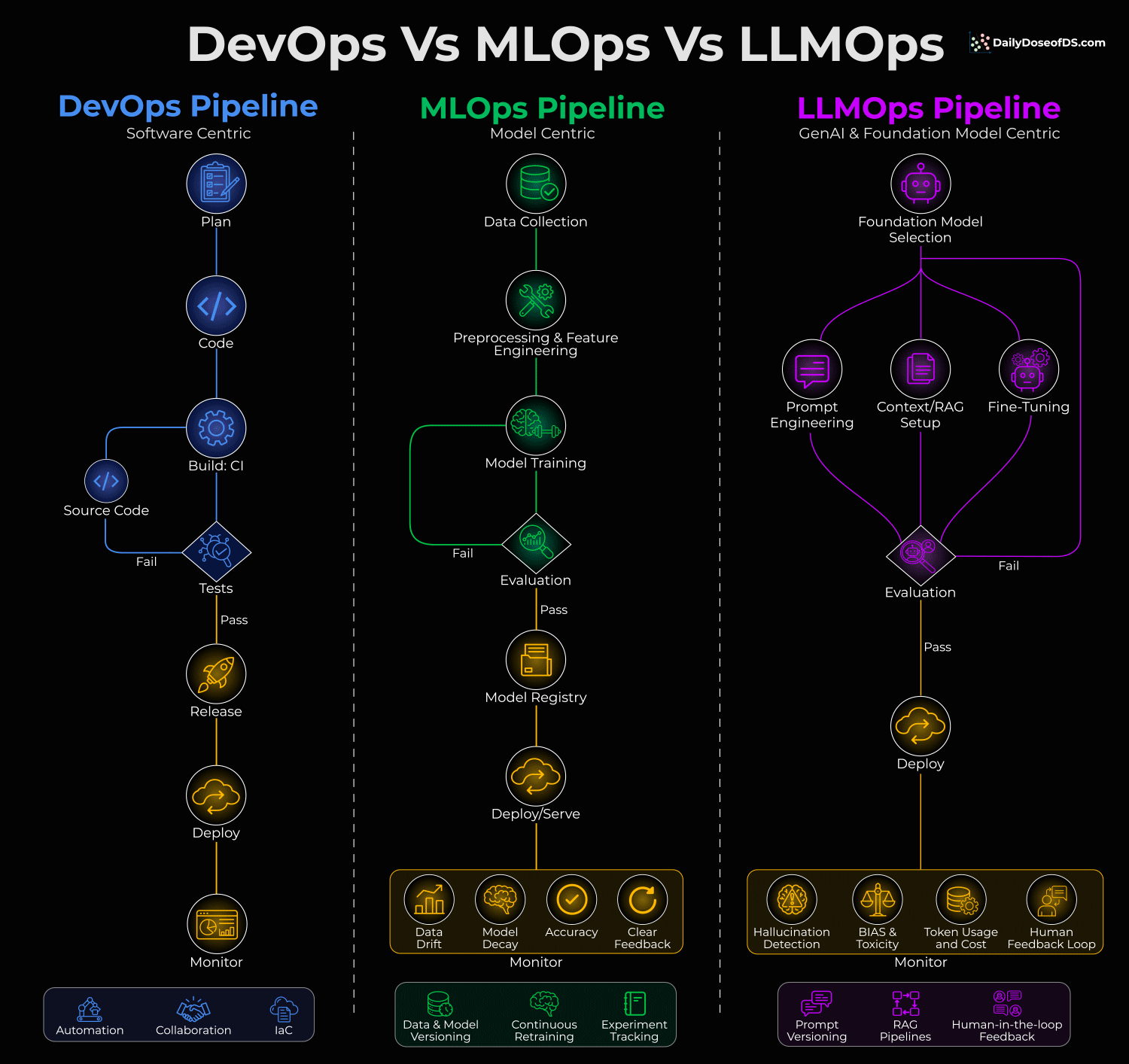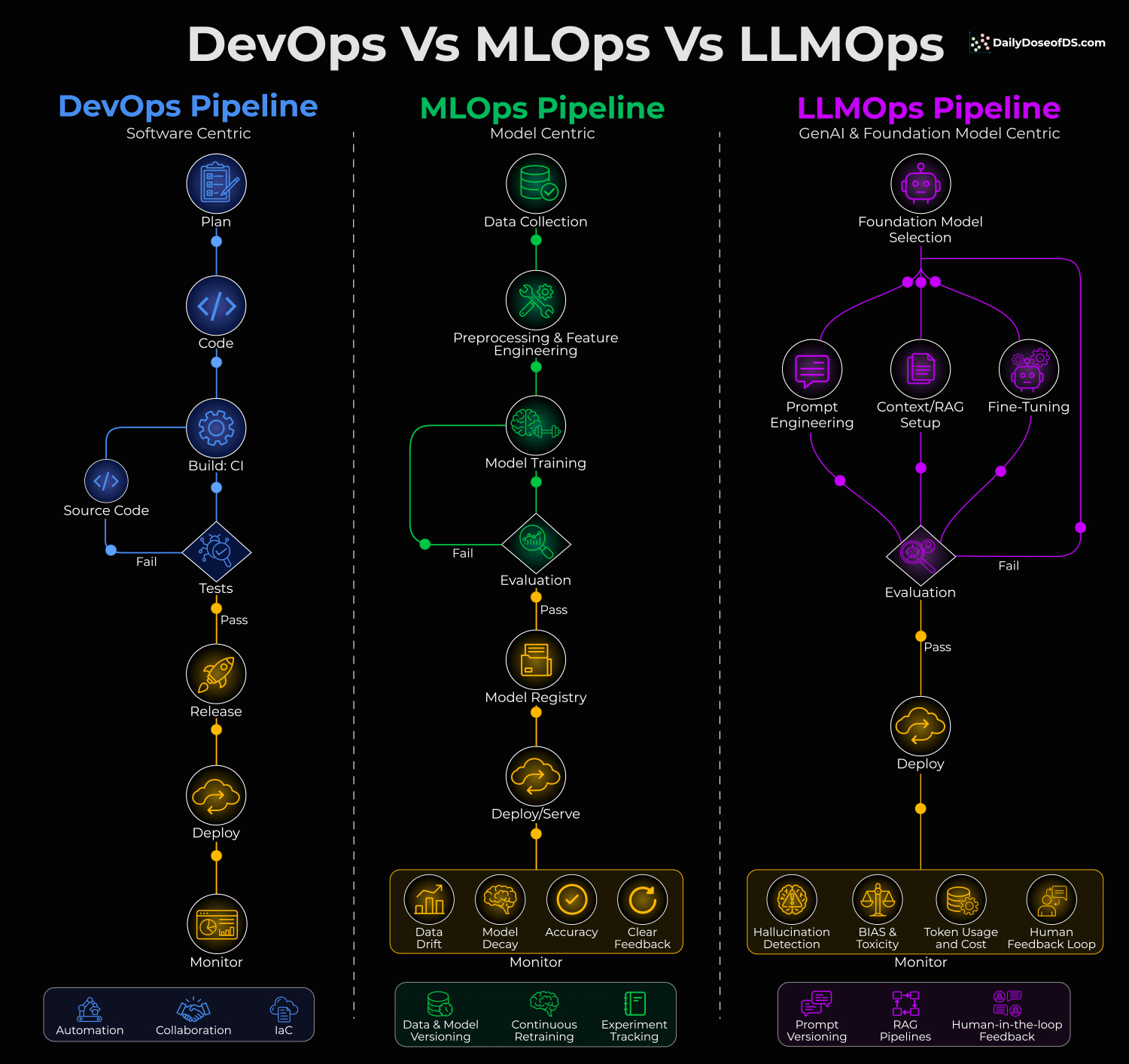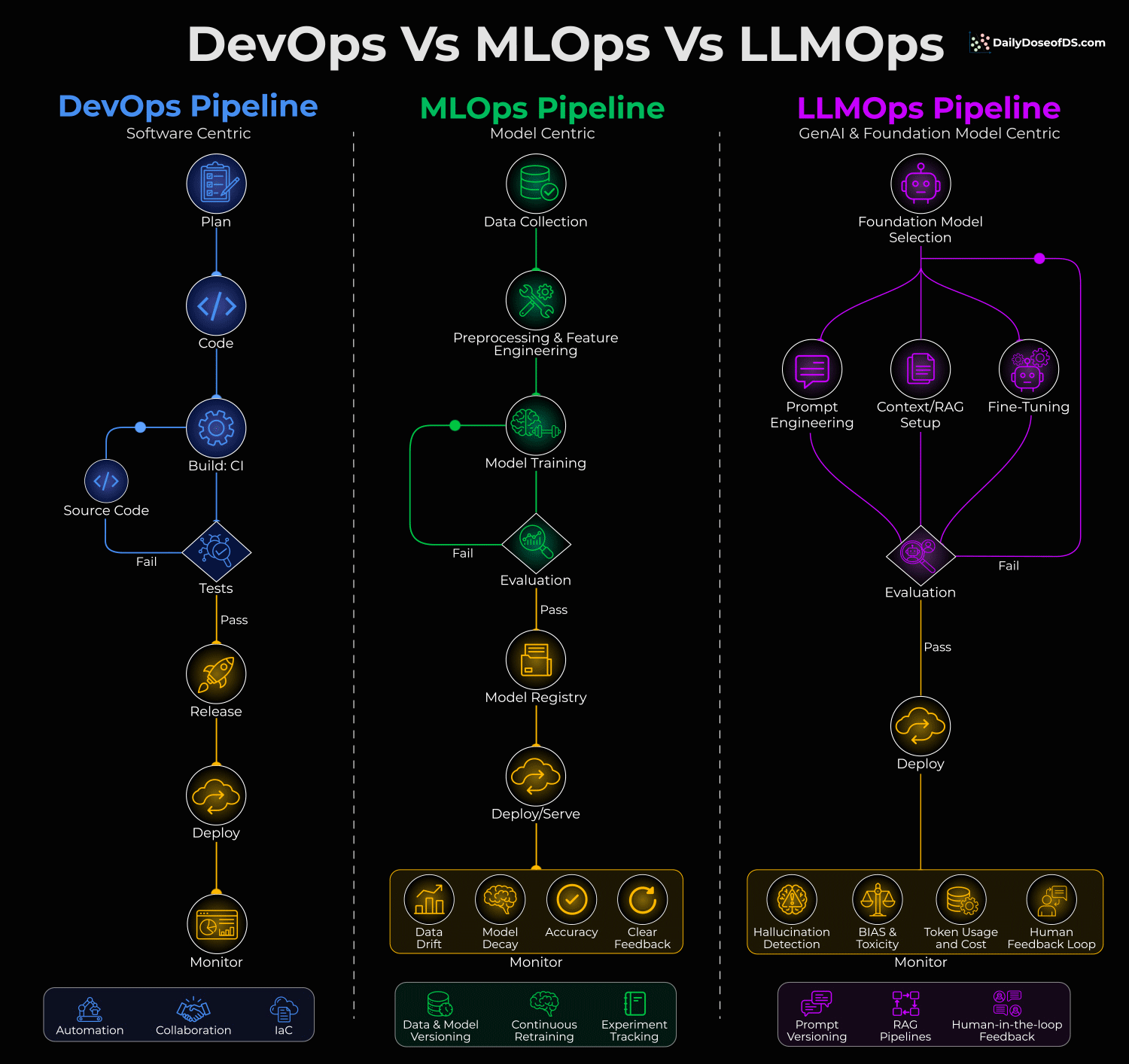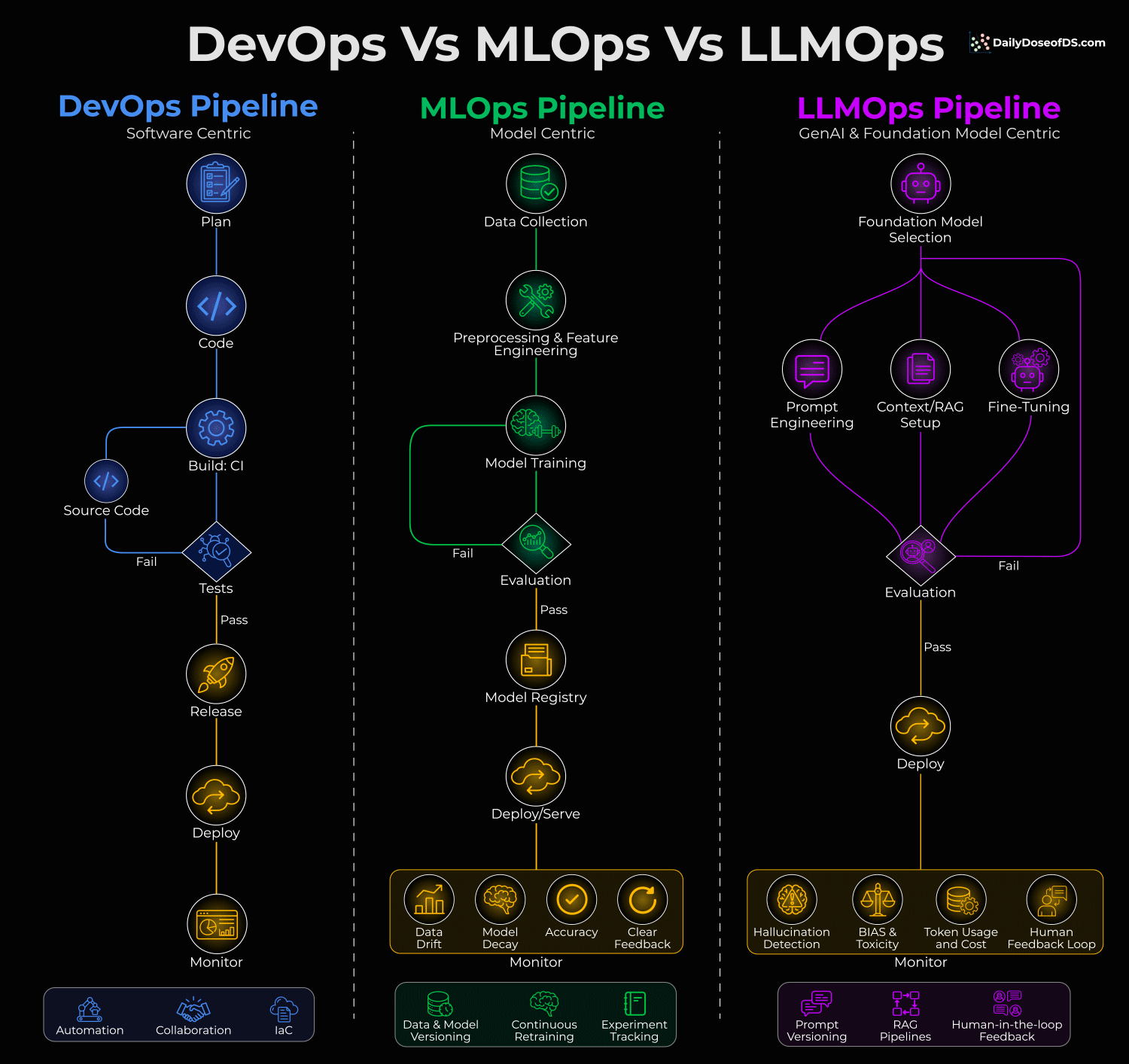
Let’s dive in to learn more!
On a side note, we have already covered MLOps from a fully beginner-friendly perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, Spark, model compression, Deployment phase, Kubernetes, cloud infra, virtualisation, deep dive into AWS, and monitoring in production.
DevOps is software-centric. You write code, test it, and deploy it. The feedback loop is straightforward: Does the code work or not?
MLOps is model-centric. Here, you’re dealing with data drift, model decay, and continuous retraining. The code might be fine, but the model’s performance can degrade over time because the world changes.
LLMOps is foundation-model-centric. Here, you’re typically not training models from scratch. Instead, you’re selecting foundation models and then optimizing through three common paths:
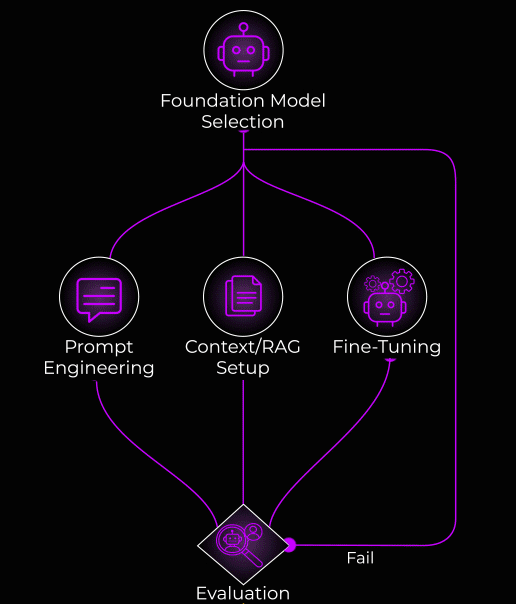
Prompt Engineering
Context/RAG Setup
Fine-Tuning
But here’s what really separates LLMOps: The monitoring is completely different.
In MLOps, you track data drift, model decay, and accuracy.
In LLMOps, you’re watching forL
Hallucination detection
Bias and toxicity
Token usage and cost
Human feedback loops
This is because you can’t just check if the output is “correct.” You need to ensure it’s safe, grounded, and cost-effective.
The evaluation loop in LLMOps also feeds back into all three optimization paths simultaneously. Failed evals might mean you need better prompts, richer context, OR fine-tuning.
So it’s not a linear pipeline anymore.
Lastly, the cost dimension in LLMOps is wildly underestimated.
In DevOps, compute costs are typically predictable. In LLMOps, a bad prompt can 10x your token spend overnight. We have seen teams blow through monthly budgets in days because they ignored token usage per query.
If you want to start with MLOps, we have already covered MLOps from a fully beginner-friendly perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, Spark, model compression, Deployment phase, Kubernetes, cloud infra, virtualisation, deep dive into AWS, and monitoring in production.
Start with MLOps Part 1 here →
We also started the LLMOps crash course recently, and its Part 1 covers:
Fundamentals of AI engineering & LLMs
The shift from traditional ML models to foundation model engineering
Levers of AI engineering
MLOps vs. LLMOps key differences
Start with LLMOps Part 1 here →
👉 Over to you: What does your LLM monitoring stack look like right now?
Thanks for reading!
Good read