
DropBlock vs. Dropout for Regularizing CNNs
Addressing a limitation of Dropout when used in CNNs.

In today's newsletter:
State of Developer Experience Report 2025.
DropBlock vs. Dropout for Regularizing CNNs.
Label Smoothing for Regularization.
State of Developer Experience 2025

Atlassian’s new State of Developer Experience Report 2025 shares insights from 3500+ developers and developer managers globally.
Here’s a preview of some interesting nuggets:
68% of developers reported saving 10+ hours a week from using AI, significantly more than last year’s results
Despite reporting increased productivity with AI, developers are also reporting more time wasted. 50% of developers lose 10+ hours a week due to organizational inefficiencies.
The full report dives deep into how AI is changing workflows, how to solve common friction points in dev teams, and the widening disconnect between leadership expectations and developer experience.
Thanks to Atlassian for partnering today!
DropBlock vs. Dropout for Regularizing CNNs
Applying Dropout over the input features in an image (pixels) isn’t that effective when you use convolution layers:

To understand this, if we zoom in on the pixel level of the digit ‘9’ above, the red pixel (or feature) will be highly correlated with other features in its vicinity:

Thus, dropping the red feature using Dropout will have no effect since its information can still be sent to the next layer due to the convolution operation.
DropBlock is a much better, effective, and intuitive way to regularize CNNs.
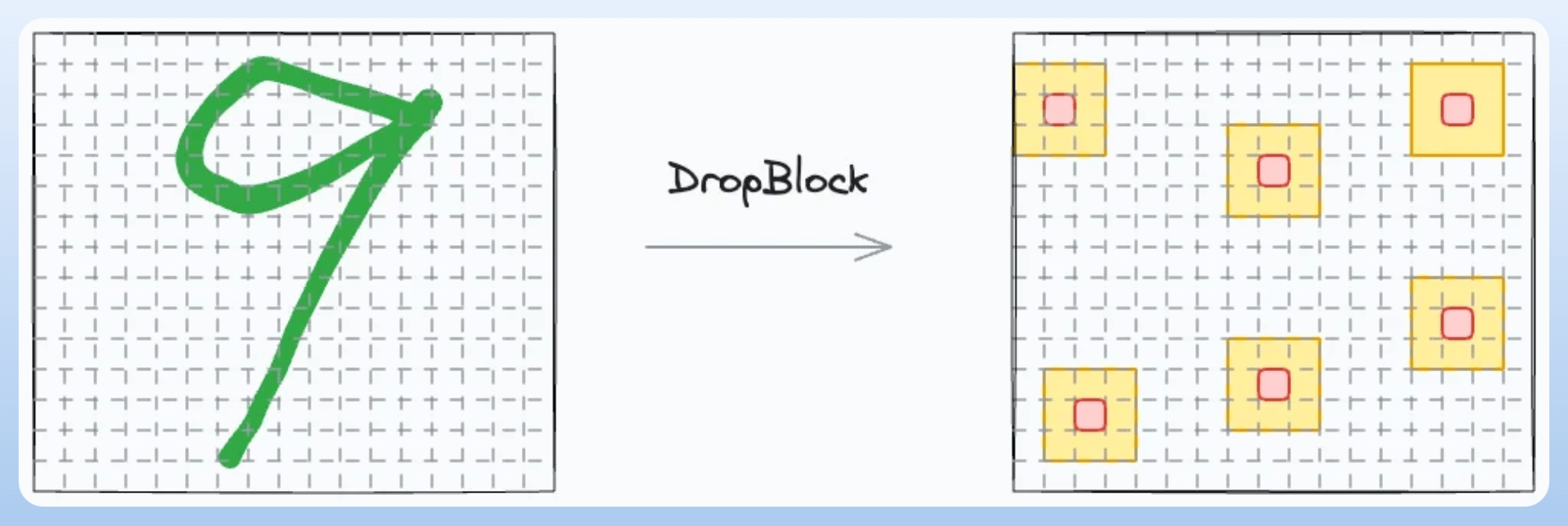
The core idea in DropBlock is to drop a contiguous region of features (or pixels) rather than individual pixels:

This forces the network to learn more robust representations that don’t rely on small local patches.
By removing an entire block, the spatial redundancy is disrupted, encouraging the model to look at a broader context.
DropBlock has two main parameters:

Block_size: The size of the box to be dropped.Drop_rate: The drop probability of the central pixel.
To apply DropBlock, first, we create a binary mask on the input sampled from the Bernoulli distribution:

Next, we create a block of size block_size*block_size which has the sampled pixels at the center:
The efficacy of DropBlock over Dropout is evident from the results table below:

On the ImageNet classification dataset:
DropBlock provides a 1.33% gain over Dropout.
DropBlock with Label smoothing (covered below) provides a 1.55% gain over Dropout.
Thankfully, DropBlock is also integrated with PyTorch. There’s also a library for DropBlock, called dropblock.
Further reading:
We covered 8 fatal (yet non-obvious) pitfalls and cautionary measures in data science here →
We discussed 11 uncommon but powerful techniques to supercharge ML models here →
👉 Over to you: What are some other ways to regularize CNNs specifically?
Let's understand Label smoothing next!
Label Smoothing for Regularization
The entire probability mass belongs to just one class in typical classification problems, and the rest are zero:

This can sometimes impact its generalization capabilities since it can excessively motivate the model to learn the true class for every sample.
Regularising with Label smoothing addresses this issue by reducing the probability mass of the true class and distributing it to other classes:

In the experiment below, I trained two neural networks on the Fashion MNIST dataset with the same weight initialization.
One without label smoothing.
Another with label smoothing.

The model with label smoothing (right) resulted in better test accuracy, i.e., better generalization.
When not to use label smoothing?
Label smoothing is recommended only if you only care about getting the final prediction correct.
But don't use it if you also care about the model’s confidence since label smoothing directs the model to become “less overconfident” in its predictions, resulting in a drop in the confidence values for every prediction:

That said, L2 regularization is another common way to regularize models. Here’s a guide that explains its probabilistic origin: The Probabilistic Origin of Regularization.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.