
Enrich Your Missing Data Analysis with Heatmaps
A lesser-known technique to identify feature missingness.

Real-world datasets almost always have missing values.
In most cases, it is unknown to us beforehand why values are missing.
There could be multiple reasons for missing values. Given that we have already covered this in detail in an earlier issue, so here’s a quick recap:
Please read this issue for more details: The First Step Towards Missing Data Imputation Must NEVER be Imputation.
Missing Completely at Random (MCAR): The value is genuinely missing by itself and has no relation to that or any other observation.

Missing at Random (MAR): Data is missing due to another observed variable. For instance, we may observe that the percentage of missing values differs significantly based on other variables.

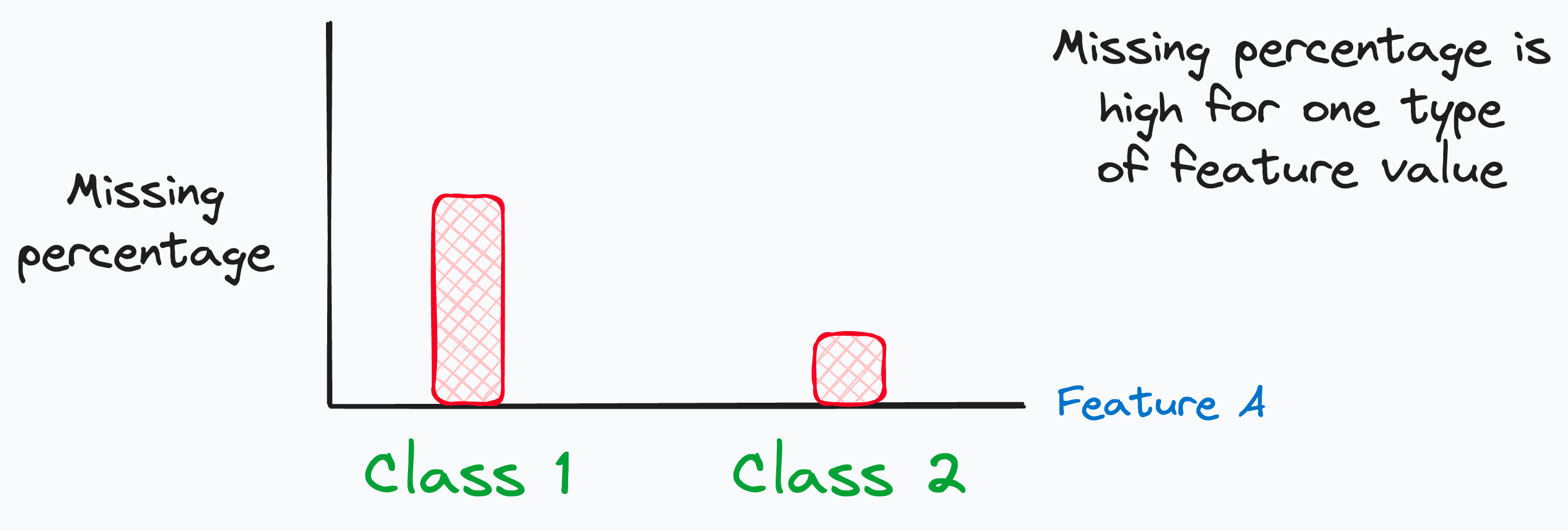
Missing NOT at Random (MNAR): This one is tricky. MNAR occurs when there is a definite pattern in the missing variable. However, it is unrelated to any feature we can observe in our data. In fact, this may depend on an unobserved feature.

Please read this issue for more details: The First Step Towards Missing Data Imputation Must NEVER be Imputation.
Identifying the reason for missingness can be extremely useful for further analysis, imputation, and modeling.
Today, let’s understand how we can enrich our missing value analysis with heatmaps.
Consider we have a daily sales dataset of a store that has the following information:

Day and Date
Store opening and closing time
Number of customers
Total sales
Account balance at open and close time
We can clearly see some missing values, but the reason is unknown to us.
Here, when doing EDA, many folks compute the column-wise missing frequency as follows:
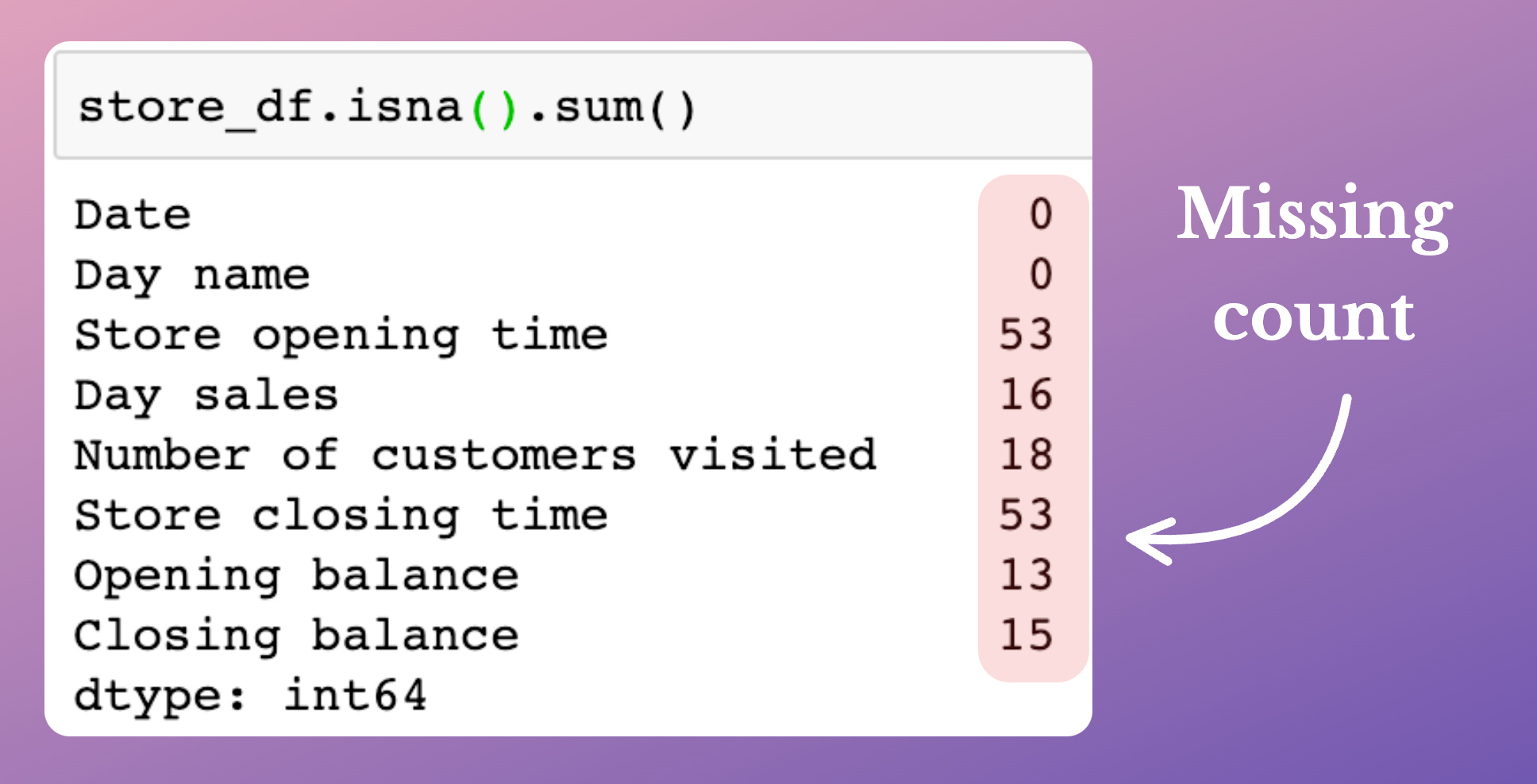
The above table just highlights the number of missing values in each column.
More specifically, we get to know that:
Missing values are relatively high in two columns compared to others.
Missing values in the opening and closing time columns are the same (53).
That’s the only info it provides.
However, the problem with this approach is that it hides many important details about missing values, such as:
Their specific location in the dataset.
Periodicity of missing values (if any).
Missing value correlation across columns, etc.
…which can be extremely useful to understand the reason for missingness.
To put it another way, the above table is more like summary statistics, which rarely depict the true picture.
Why?
We have already discussed this a few times before in this newsletter, such as here and here, and below are the visuals from these posts:

So here’s how I often enrich my missing value analysis with heatmaps.
Compare the missing value table we discussed above with the following heatmap of missing values:
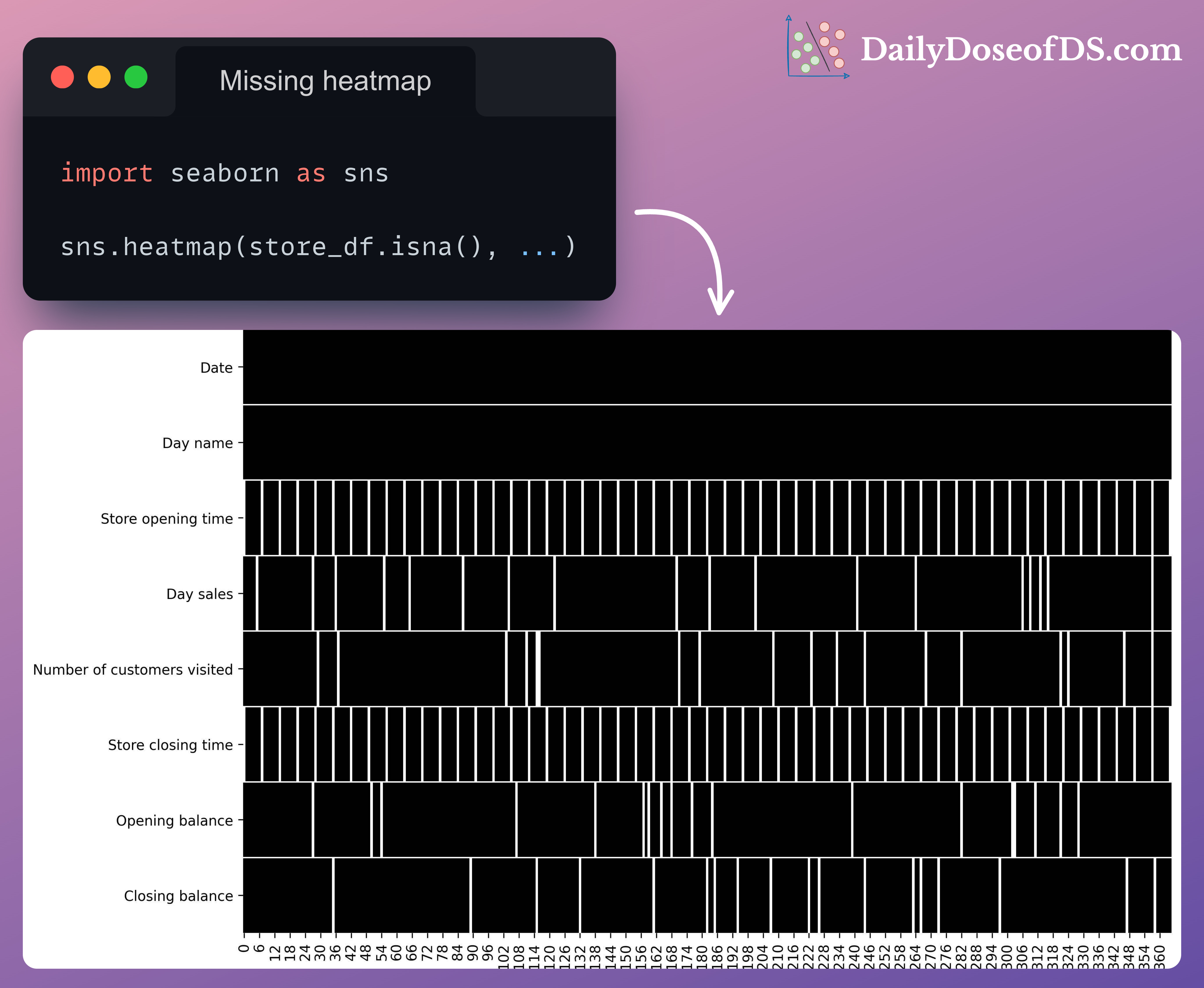
The white vertical lines depict the location of missing values in a specific column.
Now, it is immediately clear that:
Values are periodically missing in the opening and closing time columns.
Missing values are correlated in the opening and closing time columns.
The missing values in other columns appear to be (not necessarily though) missing completely at random.
Further analysis of the opening time lets us discover that the store always remains closed on Sundays:

Now, we know why the opening and closing times are missing in our dataset.
This information can be beneficial during its imputation.
This specific situation is “Missing at Random (MAR).”
Essentially, as we saw above, the missingness is driven by the value of another observed column.
Now that we know the reason, we can use relevant techniques to impute these values if needed.
For MAR specifically, techniques like kNN imputation, Miss Forest, etc., are quite effective. We covered them in these issues:
Wasn’t that helpful over naive “missing-value-frequency” analysis?
👉 Over to you: What are some other ways to improve missing data analysis?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
I can recommend the missingno package for studying missing data (I am not the developer haha)
https://github.com/ResidentMario/missingno