
Ensuring Reproducibility in Machine Learning Systems
...and the best practices to achieve it.

There’s a pattern repeating across Machine Learning (ML) systems. You train a model, deploy it, and see its performance falter. Or worse, you can’t quite get it to give you the same results twice.
Why? Because if you can’t reproduce your previous efforts, pinpointing the cause of any deviation is nearly impossible.
Reproducibility isn’t just a nice-to-have, it’s critical. Without it, debugging becomes a clueless exercise, improvements are pure guesswork, and collaboration grinds to a halt.
The importance of reproducibility
Even the smallest change (like a shifted random seed) can lead to wildly different outcomes when reproduced. Imagine tweaking a model, only to realize later that it doesn’t quite behave the same.
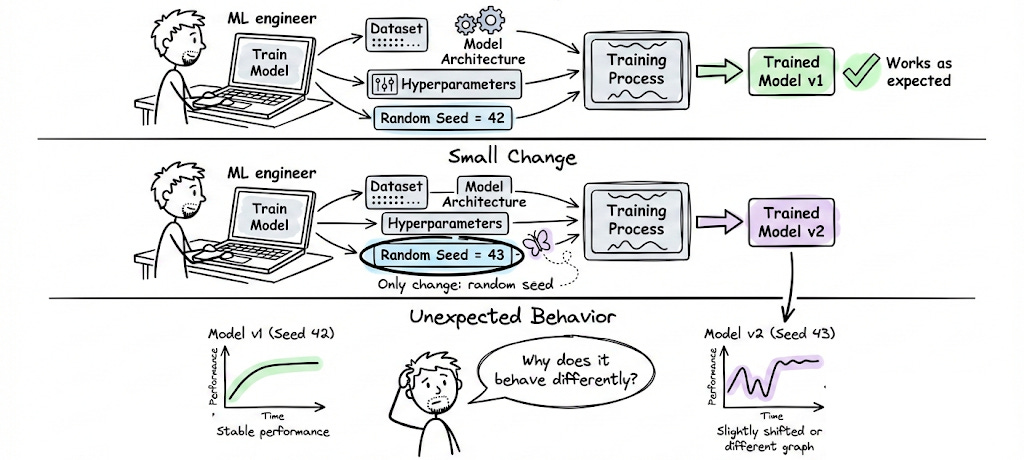
Also, think of reproducibility in ML like something that builds trust and predictability.
Because in many regulated industries, proving the consistency of a model’s behavior isn’t optional. Finance, healthcare, and autonomous vehicles demand regulatory compliance. Knowing exactly what led to a specific model decision can mean the difference between passing a regulation and failing it.
Debugging and collaboration
Error tracking is straightforward only when the process is consistent. If your model’s accuracy suddenly drops, being able to see what caused it helps immensely.
Without reproducibility, you’re lost in a moving target hunt, every slight divergence a potential culprit. For teams, reproducibility eases collaboration. Because rerunning another engineer’s experiment shouldn’t be a guessing exercise.
Some best practices for reproducibility
First, version everything: code, data, and your outputs. Git for your scripts, and something like DVC for data. These tools offer a way to tie everything into a cohesive, versioned workflow.
Ensure your ML processes are deterministic. Frameworks like TensorFlow and PyTorch allow you to fix random seeds. This doesn’t make them foolproof, but it narrows the variables.
Testing for reproducibility: It sounds obvious, but test it. Once a model is trained, verify its consistency by rerunning it with known inputs. Results should match expectations.
Track expermiments: Leverage tools like MLflow to log experiments. Detailed logs covering run IDs, hyperparameters, and environment info ensure any successful run can be inspected and replicated.

For data, track versions or partitions used in training. Even a simple “used data file X with checksum Y” can become invaluable for verifying dataset consistency.
Finally, capture the full software environment including configurations, code, data, performance, etc. Requirement files can help greatly in managing configurations by nailing down versions, thus preventing unnecessary updates from introducing discrepancies.

For complete snapshots, we can also containerize our environment with Docker.
Overall, ML reproducibility is a framework in itself. As the saying goes, “If it isn’t reproducible, it’s not science.” In MLOps, if it isn’t reproducible, it won’t be robust in production.
If you want to learn more about these real-world ML practices and start your journey with MLOps, we have already covered MLOps from an engineering perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, model compression, deployment, Docker and Kubernetes, cloud fundamentals, virtualization, a deep dive into AWS EKS, monitoring, and CI/CD in production.
To specifically explore reproducibility in greater depth click here
Thanks for reading!
Skill Graphs > SKILL .md
Everyone’s talking about skills for AI agents.
But almost nobody is talking about how to structure them.
Right now, the default approach is simple. You write one skill file that captures one capability. A skill for summarizing. A skill for code review. A skill for writing tests.
One file, one job, and it works.
But I recently came across an idea that made me rethink this entirely.
What if skills weren’t flat files? What if they were graphs?
Let me explain what I mean.
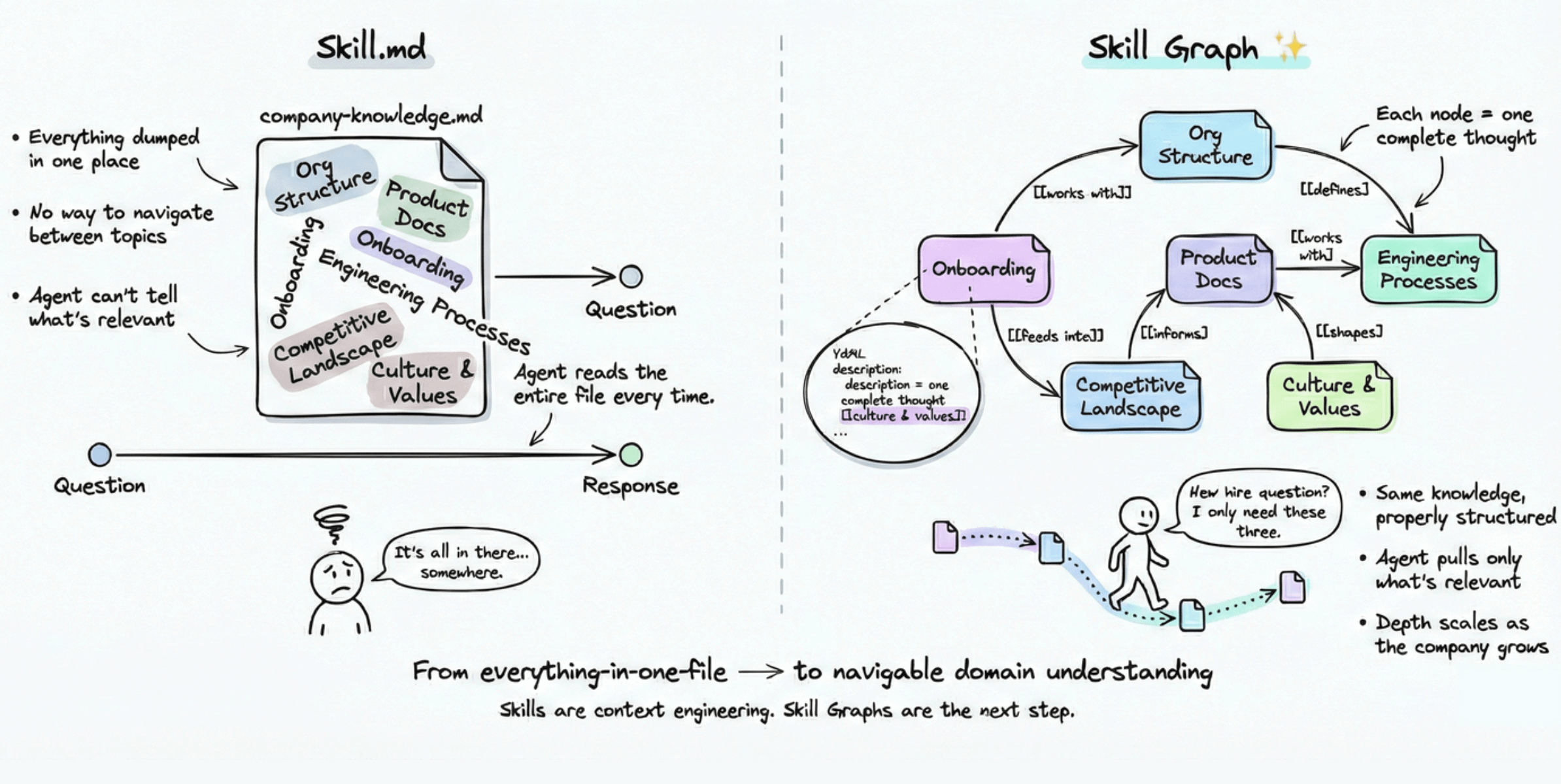
Think about how a senior engineer onboards you to a large codebase. They don’t hand you one giant document and say “read this.” They give you a map. They point you to the right modules. They explain how pieces connect. Then they let you go deeper only where you need to.
That’s the mental model behind a skill graph.
Instead of one big file, you build a network of small, composable skill files connected through wikilinks. Each file captures one complete thought, technique, or concept. The links between them tell the agent when and why to follow a connection.
Here’s what changes with this approach.
The agent doesn’t load everything upfront. It scans an index, reads short descriptions, follows relevant links, and only reads full content when it actually needs to. Most decisions happen before reading a single complete file.
Each node is standalone but becomes more powerful in context. A “position sizing” node in a trading skill graph works on its own. But link it to risk management, market psychology, and technical analysis, and now you have context flowing between concepts.
And suddenly, domains that could never fit in one file become navigable. Company knowledge. Legal compliance. Product documentation. Org structure. All traversable from a single entry point.
The building blocks are surprisingly simple.
Wikilinks embedded in prose so they carry meaning, not just references. YAML frontmatter so the agent can scan nodes without reading them. Maps of content that organize clusters into navigable sub-topics.
Markdown files linking to markdown files, and nothing more.
If you want to dig deeper or try building one yourself:
It’s an open-source plugin that sets up the structure and helps you build skill graphs with your agent.