
Euclidean Distance vs. Mahalanobis Distance
Euclidean distance is not always useful.

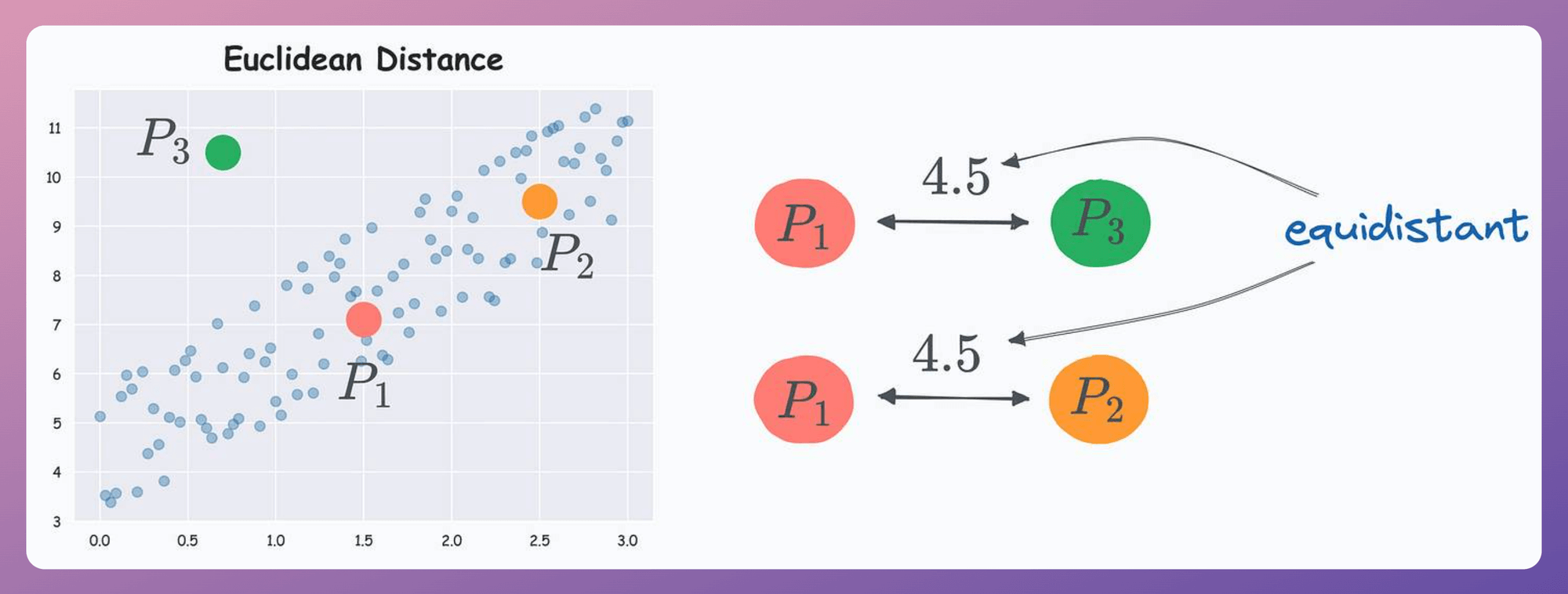
Consider the three points below in a dummy dataset with correlated features:

According to Euclidean distance, P1 is equidistant to P2 and P3.
But if we look at the data distribution, something tells us that P2 should be considered closer to P1 than P3 since P2 lies more within the data distribution.

Yet, Euclidean distance can not capture this.
Mahalanobis distance addresses this issue.
It is a distance metric that considers the data distribution during distance computation.
Referring to the above dataset again, with Mahalanobis distance, P2 comes out to be closer to P1 than P3:

How does it work?
The core idea is similar to what we do in Principal Component Analysis (PCA).
More specifically, we construct a new coordinate system with independent and orthogonal axes. The steps are:
Step 1: Transform the columns into uncorrelated variables.
Step 2: Scale the new variables to make their variance equal to 1.
Step 3: Find the Euclidean distance in this new coordinate system.
So, eventually, we do use Euclidean distance, but in a coordinate system with independent axes.
Uses
One of the most common use cases of Mahalanobis distance is outlier detection.
For instance, in this dataset, P3 is an outlier but Euclidean distance will not capture this.
But Mahalanobis distance provides a better picture:

Moreover, there is a variant of kNN that is implemented with Mahalanobis distance instead of Euclidean distance.
Further reading:
We covered 8 more pitfalls in data science projects here →
This mathematical discussion on the curse of dimensionality will help you understand why Euclidean produces misleading results in high dimensions.
👉 Over to you: What are some other limitations of Euclidean distance?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.